卷学分绩的过程中,从应试的角度学习这些基础课,也给我带来了不少收获。因而,我选择将课内复习的笔记包含在这里,并且除去一些非必要的糟粕,仅保留最精华的部分,以供以后学习参考使用。
点击每个标题超链接,可进入分文章进行查看。
计算机组成原理
编译原理
yysy,感觉编译原理这门课应该能算大三学了之后收获最大的专业课。理论课从形式化的原理出发,讲述了编译器的构成:词法分析、语法分析、语义分析、中间代码生成、代码优化、目标代码生成。实验课又实现了一个简单的具有基本功能的编译器。这二者相辅相成,学完这门课之后真的对编译系统的构造有了一个较为全面的了解。
词法分析
词法分析对源程序进行分析,提取出标识符和关键字等符号,形成token list(token:<值, 种别码>)。
词法分析事实上就是构造一个有穷自动机,来识别标识符相关的正则表达式:
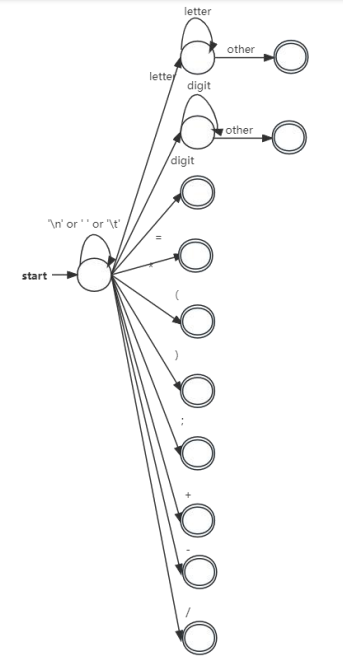
最后相当于把一个具体的符号用一个种别码来标识,以供之后的语法分析来使用。
比如说,”a” “abc” “a123”都是标识符,但是它们在语法分析中(例如下面这个文法)都统一被称为”id“。我们的词法分析的作用就是生成<a, id> <abc, id> <a123, id>这样的token。这样,语法分析就无需关注原程序这些抽象的符号是什么意思,只需根据种别码表示下这个是个标识符就差不多得了。
语法分析
语法分析的输入是词法分析的token list。它通过自顶向下/自底向上两种分析方法,根据给定的上下文无关文法来进行语法分析,主要用于纠出静态语法错误和语法制导翻译。
在实验中,我们使用自底向上的LR(1)文法来进行语法分析。我们通过软件编译工作台,将给定的上下文无关文法转化为了LR分析表:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15P -> S_list;
S_list -> S Semicolon S_list;
S_list -> S Semicolon;
S -> D id;
D -> int;
S -> id = E;
S -> return E;
E -> E + A;
E -> E - A;
E -> A;
A -> A * B;
A -> B;
B -> ( E );
B -> id;
B -> IntConst;然后,只需在代码中根据分析表和当前输入的token进行移入或者归约即可。
语义分析/中间代码生成
语义分析和中间代码生成一般都是依靠SDT(语法制导翻译)来完成的。它通过在语法分析过程中按照一定次序执行一系列与产生式关联的语义规则,计算符号的属性,完成副作用,来进行语义分析和中间代码生成。
感觉这一步也算是编译器实现的一大精髓。别看它定义如此简单,但实际上占据了很多重要部分,比如说符号表的填写、各种类型中间代码的生成(包括复杂的布尔表达式回填技术,这个就需要在代码中多设计些复杂数据结构了)。
在实验中,我们仅实现了最精简的语义分析和中间代码生成,也即只对声明语句和简单赋值语句做处理。并且,实验架构采用了观察者模式,也即语法分析进行移入和归约后,会通知作为观察者的语义分析器和中间代码生成器。
由于我们使用的是S-SDD+LR(1),因此只需在移进时将对应的属性也一同进栈,然后在归约时执行对应的语义动作(如填入符号表、根据产生式生成一条中间代码)即可。
运行时存储
除了上述编译器组成原理之外,还涉及了一些运行时栈帧内分布及调用序列返回序列对应的中间代码生成。它主要以过程嵌套函数和非过程嵌套函数两种分类,讲述了这两类语言对应的栈帧结构是怎么样的。
非过程嵌套语言,如C语言,不允许一个过程中声明另一个过程。在这种情况下,栈帧构成较为简单,只需存放听得耳朵出茧子的什么形参、ra之类的东西。
过程嵌套语言,如pascal,如我觉得别的什么java c++之类的应该也都支持,允许在一个过程中声明另一个过程。在这种情况下,为了记录过程嵌套关系,就绪引入静态链(访问链)和动态链(控制链)。静态链指向的是当前过程声明所在的那层,动态链指向的是调用该过程的那一层。有了这俩东西,我们就可以在一个过程中沿着这两个链访问另一嵌套深度过程中的变量了(而且只能里面访问外面,所以一般不会有自外向内的链。。。)。
但是,这样的链式访问必定会导致寻址时的效率低下,所以我们引入了Display表。

相当于比如说以前想要访问父父过程,需要两次链式访问,但是通过display表就只需要一次,极大优化了嵌套深度大的情况。
密码学基础
纯纯觉得ppt写得好。通识这一方面做得很不错。
数据库原理
大概算是自顶向下地,从sql语句(以及相应的关系代数实现)、数据库核心技术(索引实现、查询实现/优化、事务处理、安全性与完整性、故障恢复)、与磁盘的交互(数据库存储、缓冲区策略)这几个方面全方位介绍了数据库的实现思路。
sql语句和关系代数在此就不做赘述。
概述
收获最大还是了解了下网状/层次模型。我记得有说过现在好像有一些非关系模型也开始火了,感觉也算是比较前沿的方向。
索引实现
主要介绍了稠密索引、稀疏索引、主索引、聚簇索引、辅助索引等这几类索引。它们都可以用b+树来实现性能更好的多级索引。还介绍了动态散列索引,通过线性增长和溢出桶实现。
查询实现和优化
关系代数的各种操作的实现算法主要有一趟扫描、迭代器、两趟扫描等。
优化和代价估算的算法也不做赘述了。
事务处理
主要介绍了三种常见的并发控制方法:封锁协议、时间戳、有效性检测。感觉现实中应该主要还是用的封锁协议吧。冲突可串行性这个理论也是很有意思。
【这里需要注意的是,这三种就是具体的事务调度方法(特别是封锁协议),而不是说先进行事务调度再通过这三个实现事务……】
安全性与完整性
主要通过静态约束和动态约束(trigger)来保障数据库的完整性。第一次知道trigger可以被视为约束,感觉这个角度也蛮酷。
保障安全性有两种常见措施,一个就是我们在实践中也做了很多的授权机制,如grant、revoke之类的;另一个就是感觉比较罕见的那个什么表了。
故障恢复
主要介绍了不同缓冲区策略对应的三种日志类型,看了也是让人收获颇深。
复习过程中有个疑惑,也即Undo/Redo型日志的恢复顺序,似乎是因数据库实现而异。在mysql中,是先执行的redo log,再执行的undo log。
数据库存储
主要介绍了文件的几种组织方式,如堆文件、有序文件、散列、聚簇等。
实验
前两次实验就是写写sql没啥好说的。最后两次实验,一个是挣扎前端,另一个就比较有意思了,聚焦于关系代数几个操作的实现,有点像写了一个mini的数据库引擎。
计算机体系结构
我校的arch课感觉有点怪怪的,该讲的地方一笔带过默认你会(比如除去并行体系结构之外的其它体系结构我怎么感觉也是很值得一讲的,相当于扩展一下计组内容),不该涵盖的地方(指完全可以另开一门课的AI体系结构)又写了一大堆又很简略,导致最后好像深度广度都没有,所以之后还是得多看看书培养一下。总之,还是在这里记录一下应试过程中我学到了什么吧。
现代处理器体系结构
大概是讲了现代处理器为了实现指令级并行会遇到的一些问题和对应的处理方法。
一些指令之间的相关关系可能会导致无法并行执行or有结果不正确的风险,如数据相关(无法并行)、名相关(风险,输出相关和反相关)以及控制相关(通过前瞻执行解决),这些相关关系就会造成几种数据冲突,RAW(数据相关)、WAW(输出相关)、WAR(反相关)。
为了提高并行度,我们引入了流水线、多流出(超标量技术和VLIW技术),而前者会导致RAW,后者会导致WAW和WAR(因为引入了乱序执行,导致某些指令读写操作滞后/推前),导致执行错误或者并发度太小。
为了解决这样的问题,我们就需要引入指令调度算法。指令调度算法可以分为编译器静态调度和硬件实时动态调度。后者又有记分牌、Tomaluso算法等常见调度算法,它们分别划为4 or 3级流水,在特定的阶段结合硬件做一些事情(比如说乱序执行、暂停、寄存器换名等措施)来解决这些冲突问题。
同时,除了通过指令调度算法,我们还可以通过软流水、循环展开来提高并发度。
AI体系结构
首先大概是说了SISD、SIMD、MIMD这几种并行体系结构分类都是什么,本章主角自然是MD了。
然后又简单介绍了GPU的体系结构,比如说它可以分为SM(流多处理器)和显存(层次结构),还有一些CUDA编程的基本概念,比如kernel、线程相关(Thread、Wrap、Block、Grid)之类的,其中Wrap是最小调度单位,也即Wrap内所有线程执行同一代码。
然后还讲了下具体的性能优化,比如访存优化(Stream、避免bank冲突增加padding)等等等。
最后简单介绍了目前的典型DL框架PyTorch。
自动驾驶体系结构
写得依托,懒得说了。