第一章 绪论
概述
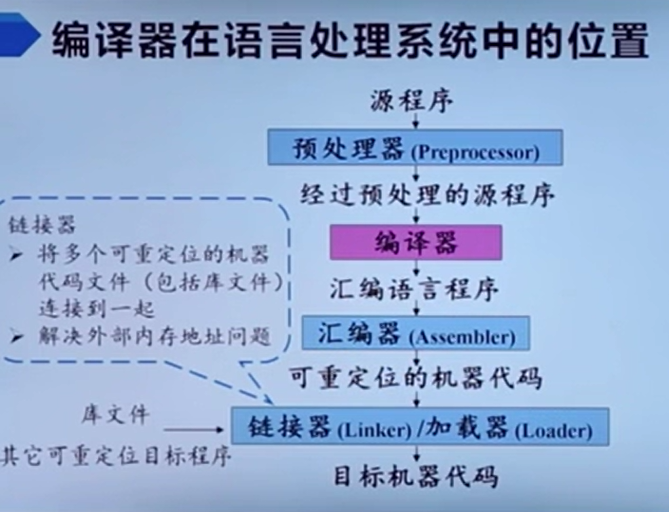
可重定位的代码通过linker和loader重定位这部分内容就是在之前那本书学过的。
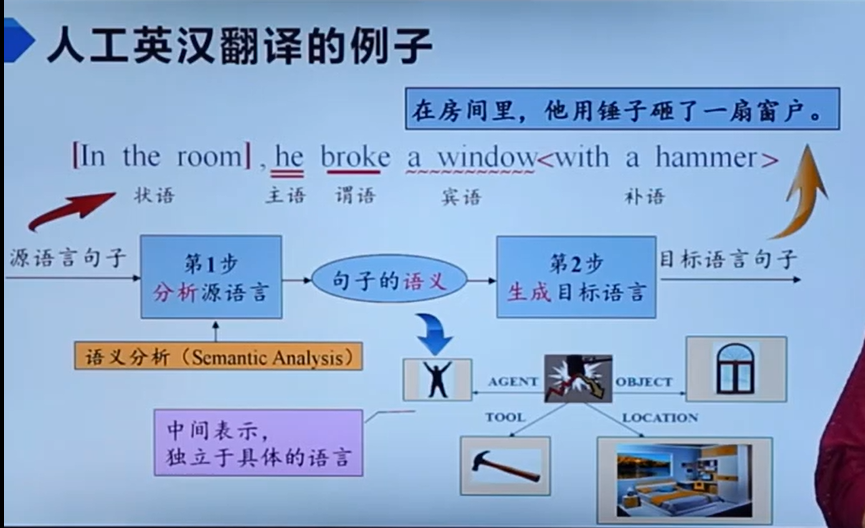
从中,我们也可以看到有语法分析、中间代码的影子。
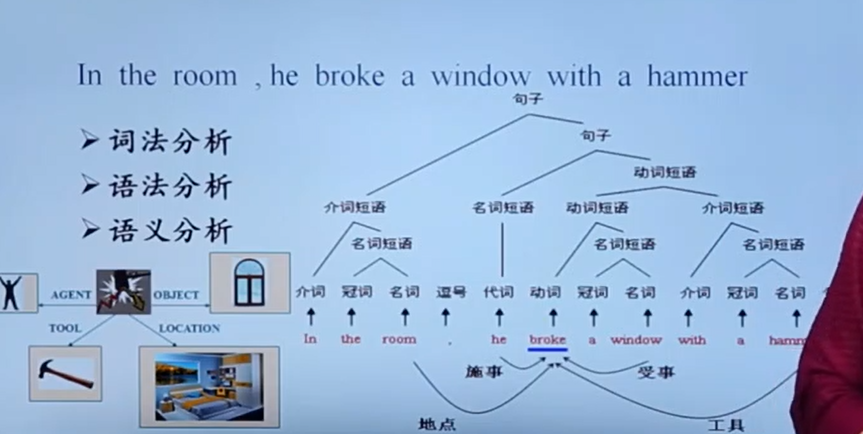
词法分析相当于通过DFA NFA捉出各类符号,形成简单的符号表和token list;语法分析相当于对token list组词成句,判断该句子是否符合语言规则;语义分析相当于对词句进行类型判断和中间代码的生成,获得基本语义。
编译程序总体结构
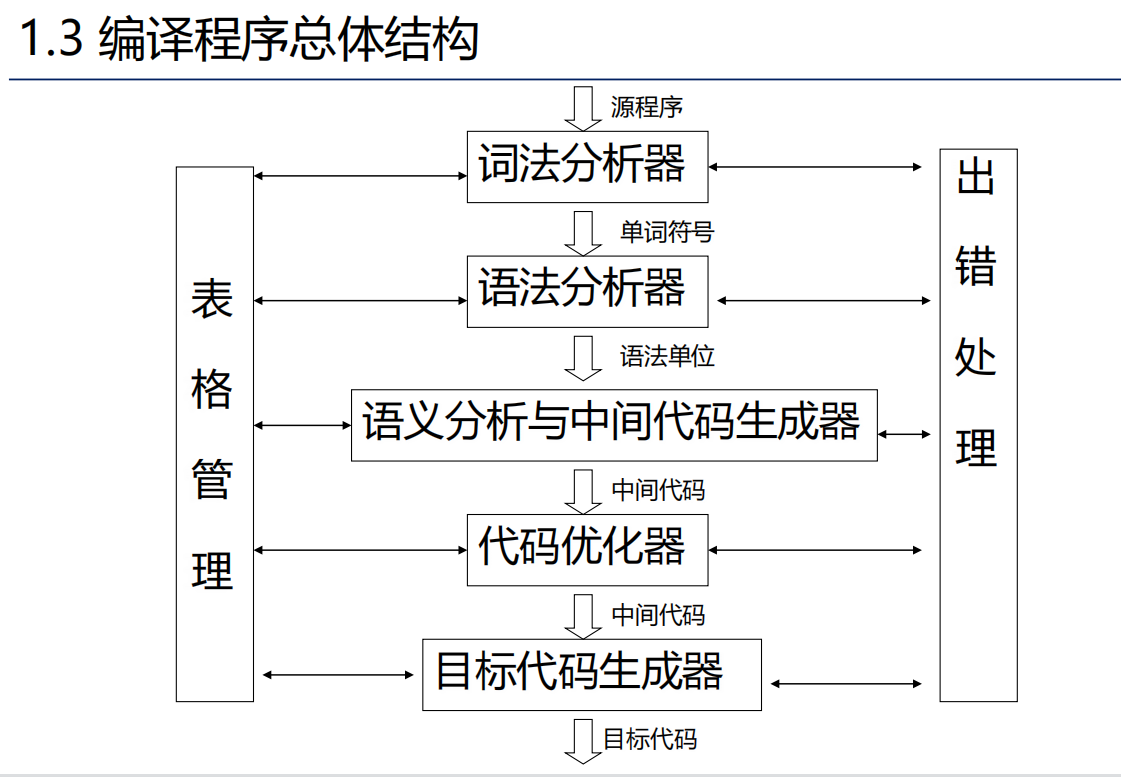
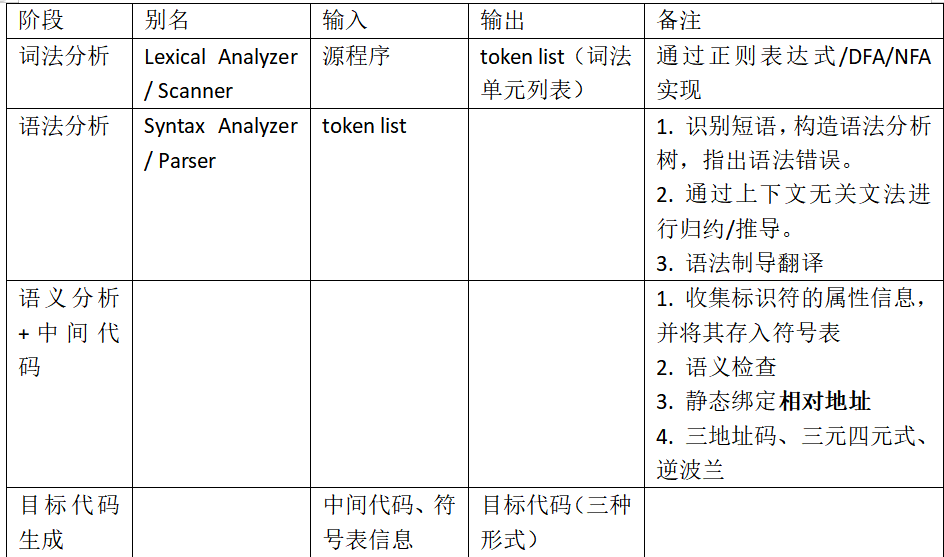
语法制导翻译:语义分析和中间代码生成集成到语法分析中
词法分析
将结果转化为token的形式。


语法分析
从token list中识别出各个短语,并且构造语法分析树。
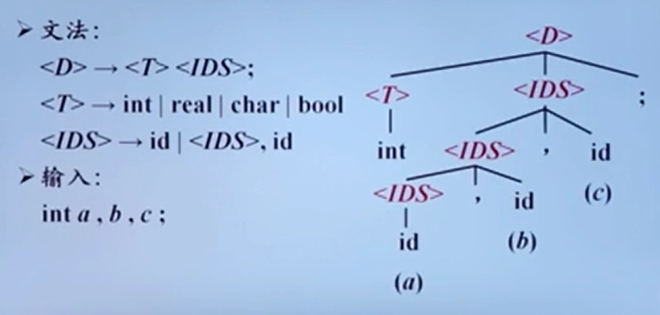

相当于是通过文法来进行归约(自底向上的语法分析),从而判断给定句子是否合法。
语义分析

- 收集标识符的属性信息,并将其存入符号表
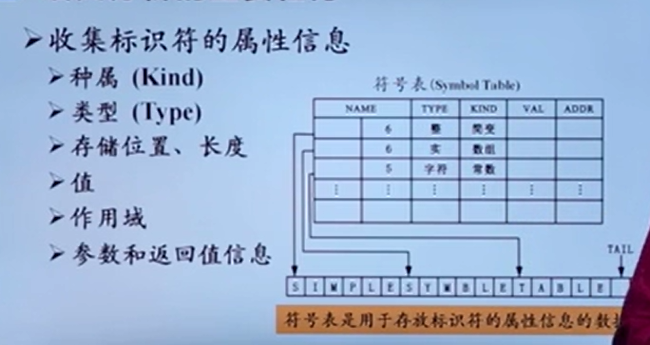
种属就是比如是函数还是数组之类的。

- 语义检查

静态绑定
包括绑定代码相对地址(子程序)、数据相对地址(变量)
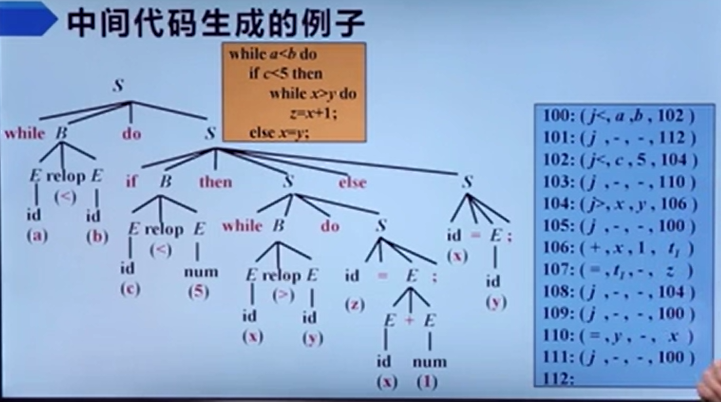
中间代码生成


波兰也就是前序遍历二叉树(中左右),逆波兰也就是后序遍历二叉树(左右中)
代码优化

无关机器

有关机器

目标代码生成

表格管理
这也挺好理解,相当于管理符号表吧。

错误处理

编译程序的组织
了解了编译程序的基本结构,那么我们就可以想想该怎么实现这个编译器了。
最直观的想法是,我们有几个步骤就对代码进行多少次扫描:
- 首先扫一次,进行词法分析,将所有标识符写入到符号表中,同时进行语法分析,看看有没有错,如果出错了就转到错误处理,没有的话就进行语义分析;(三合一)
- 然后再针对得出来的语义分析树进行中间代码生成;
- 再对得出来的中间代码进行代码优化,最后对优化出来的代码进行翻译处理。(二合一)



实现编译器

T形图
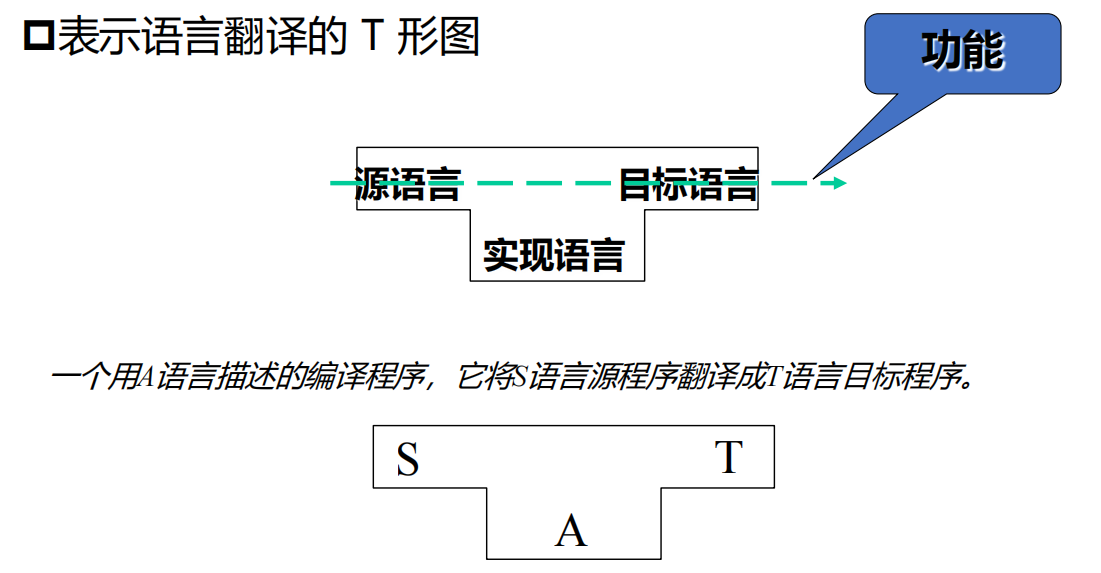
自展

也就是说:
- P0是汇编语言,可以用来编译C语言子集;(P0:汇编语言,C子集→汇编)
- P1是机器语言,可以用来把汇编语言翻译为机器语言;(P1:机器语言,汇编→机器)
- 所以我们就得到了P2,也即一个可以用来编译C语言子集的机器语言程序;(P2:机器语言,C子集→汇编)
- 然后我们就可以用C语言子集来写C语言编译程序P3,再用P2翻译P3,就可以得到工具P4。(P4:汇编语言,C→汇编)

帅的。
移植

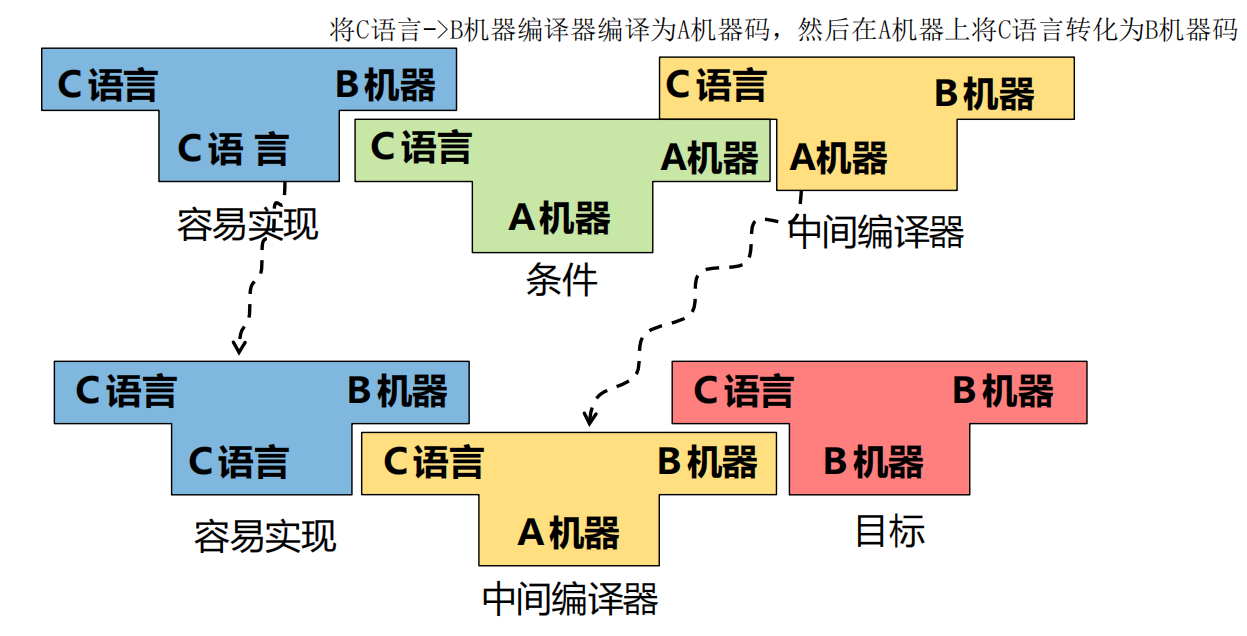
本机编译器的利用
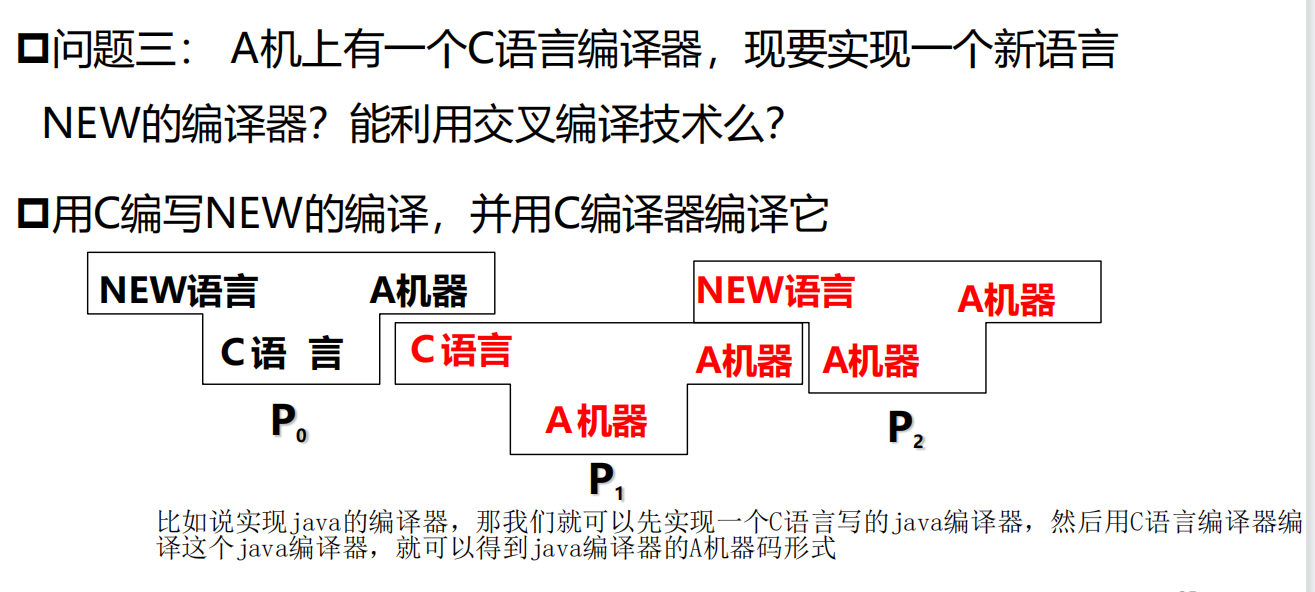
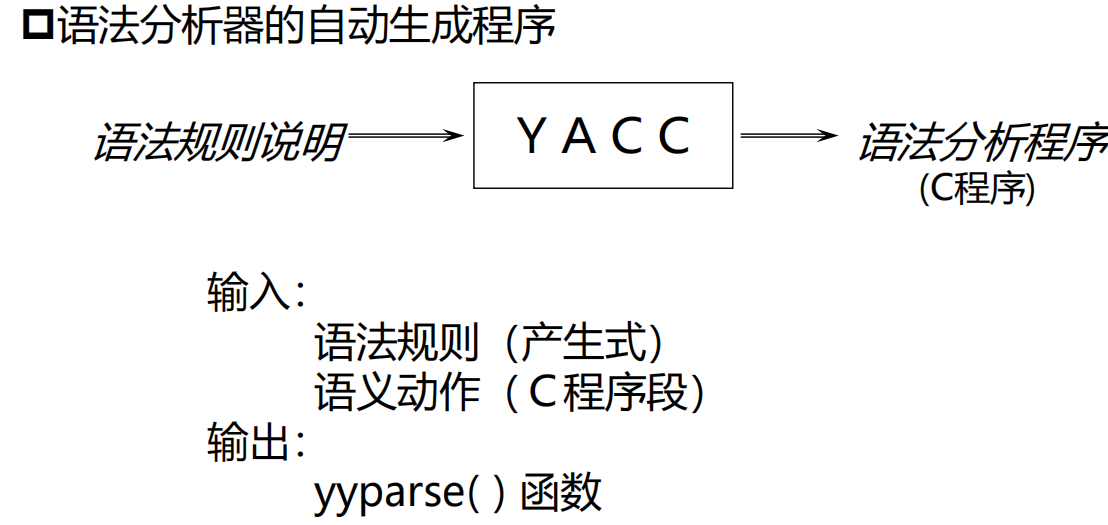
编译程序的自动生成
这大概是描述了我们到时候会怎么实现这两个阶段代码。
不过确实,词法分析可以看作是正则匹配,语法分析可以看作是产生式。
第二章 文法等概念

基本概念
字母表




串
克林闭包中的每一个元素都称为是字母表Σ上的一个串



文法

如果文法用于描述单词,基本符号就是字母;用于描述句子,基本符号就是单词
文法的形式化定义


由于可以从它们推出其他语法成分,故而称之为非终结符


还真是最大的语法成分
产生式

符号约定



文法符号串应该就是指既包含终结符也包含非终结符的,也可能是空串的串。
注意终结符号串也包括空串。
语言

这部分就是要讲怎么看一个串是否满足文法规则,那么我们就需要先从什么样的串是满足文法规则的串开始说起,也即引入“语言”的概念。
推导与归约

然后也分为最左推导和最右推导,对应最右归约和最左归约。

故而,如果从开始符号可以推导(派生)出该句子,或者从该句子可以归约到开始符号,那么该句子就是该语言的句子。
句子与句型

句型就是可以有非终结符,句子就是只能有终结符
语言

文法解决了无穷语言的有穷表示问题。


emm,就是好像没有∩运算

有正则那味了
乔姆斯基文法体系

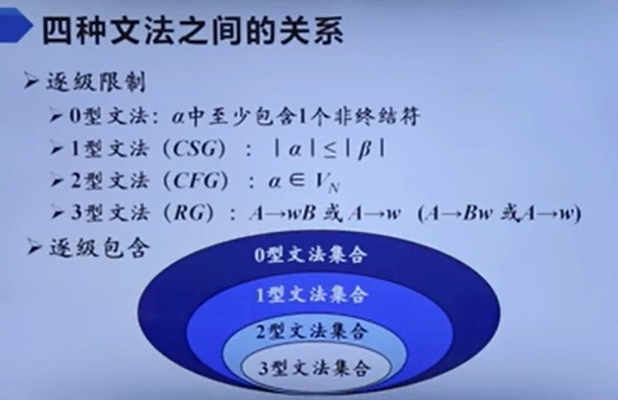
0型

1型

之所以是上下文有关,是因为只有A的上下文为a1和a2时才能替换为β【666666,第一次懂】
CSG不包含空产生式。
2型

左部只能是一个非终结符。
3型

产生式右部最多只有一个非终结符,且要在同一侧
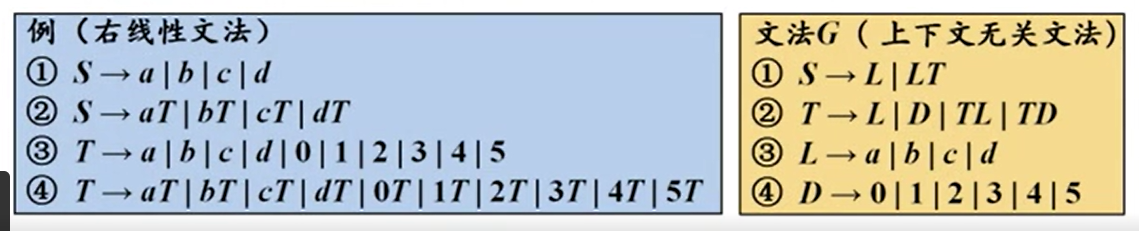
看起来还能转(是的,自动机教的已经全忘了())
CFG
正则文法用于判定大多数标识,但是无法判断句子构造。
- 分析树
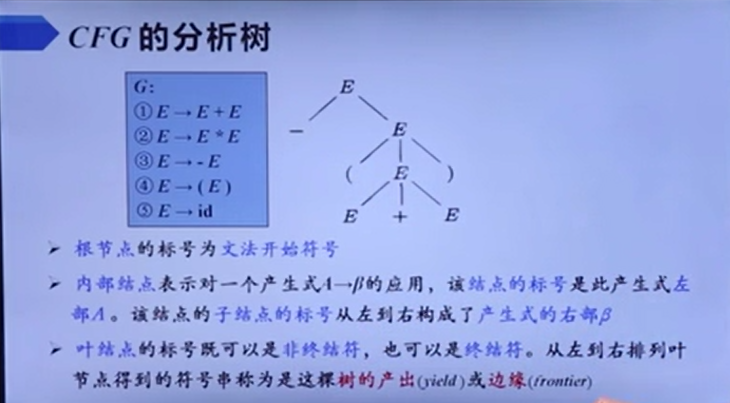

也就是说,每个句型都有自己对应的分析树。那么接下来就介绍什么是句型的短语
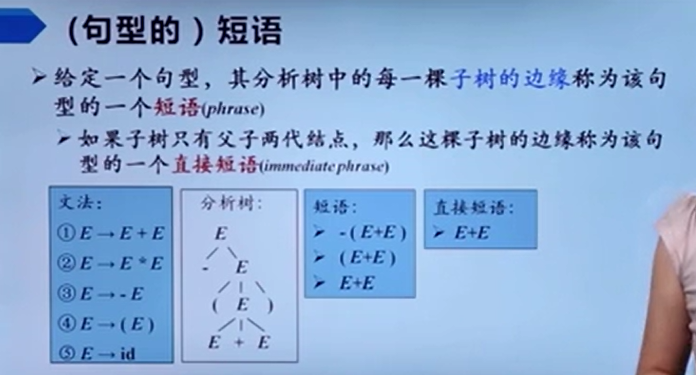
意思就是直接短语是高度为2的子树的边缘,直接短语一定是某个产生式的右部,但是产生式右部不一定是给定句型的直接短语(因为有可能给定句型的推导用不到那个产生式)
- 二义性文法
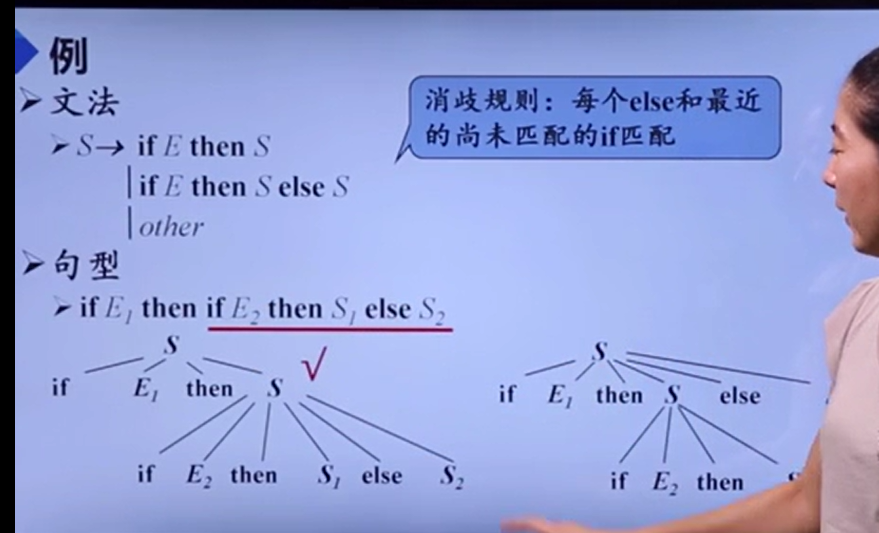
通过自定义规则消除歧义

第三章 词法分析
正则语言
正则表达式



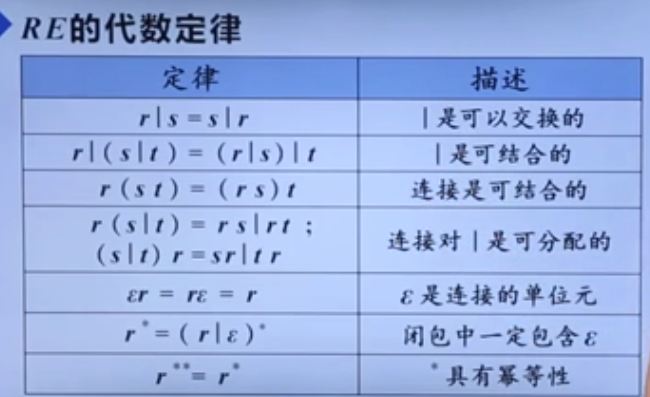
最后两条值得注意

正则定义



有穷自动机
概述
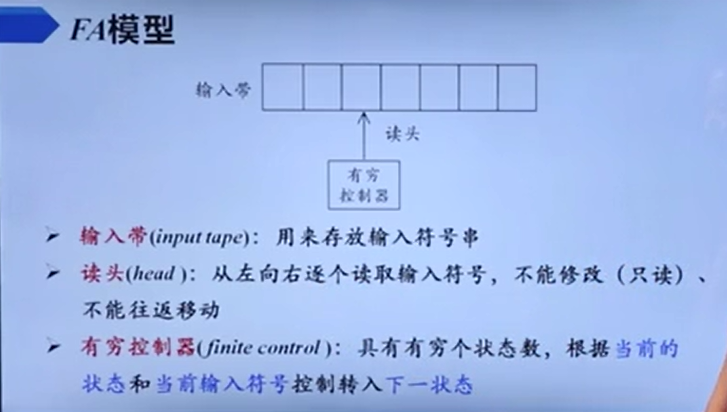
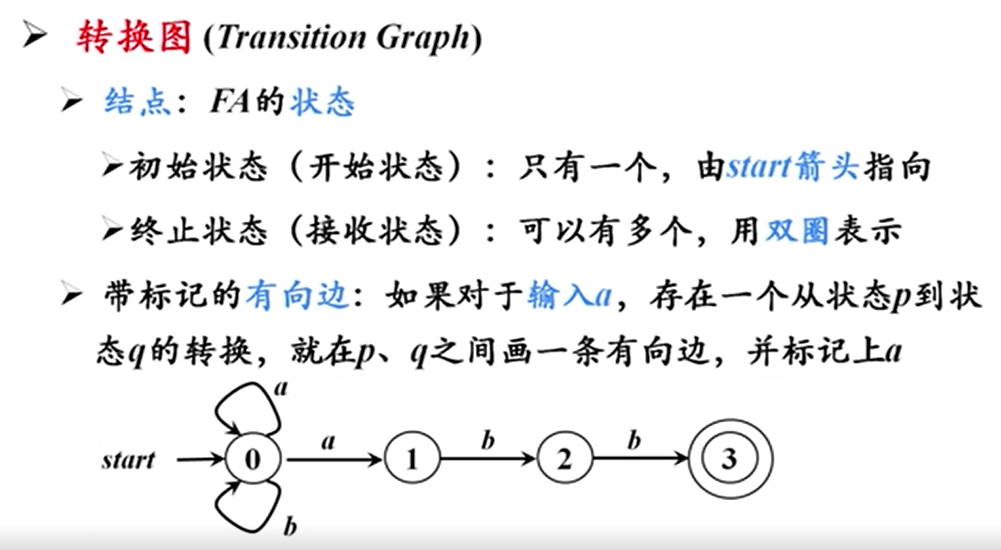

所以真正的终止是输入带到末尾并且指向终态
分类
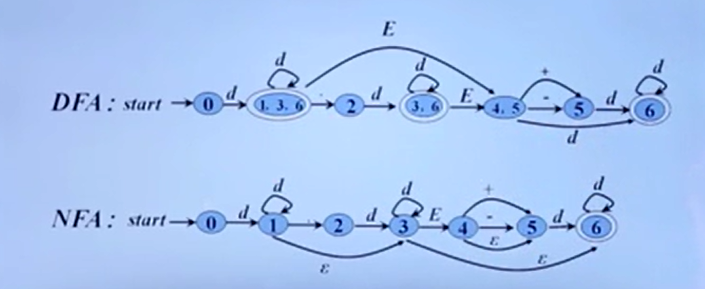
DFA

NFA

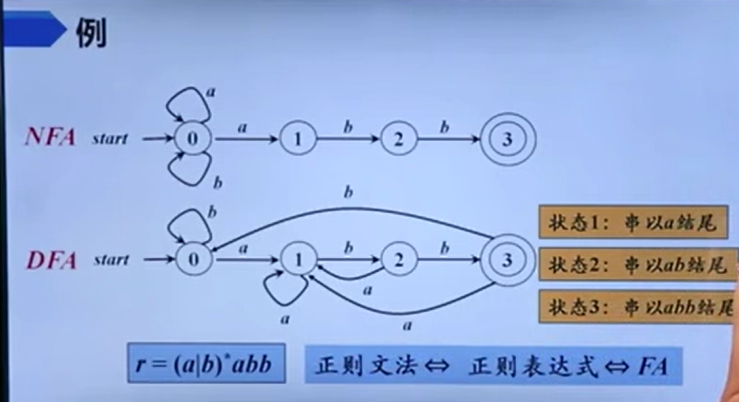
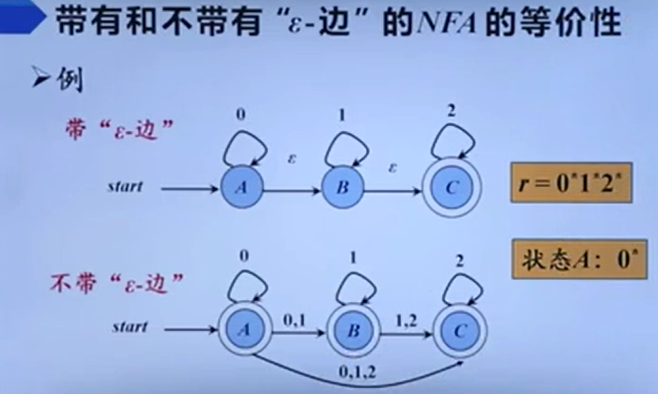
NFA与DFA转化

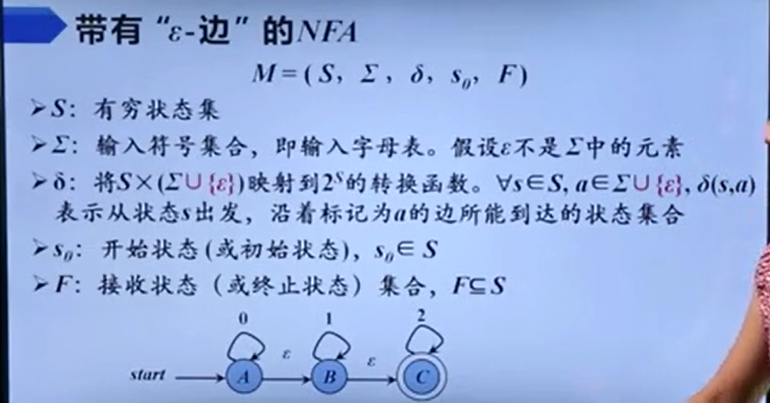
e-NFA
e-NFA与NFA转化
词法分析相关
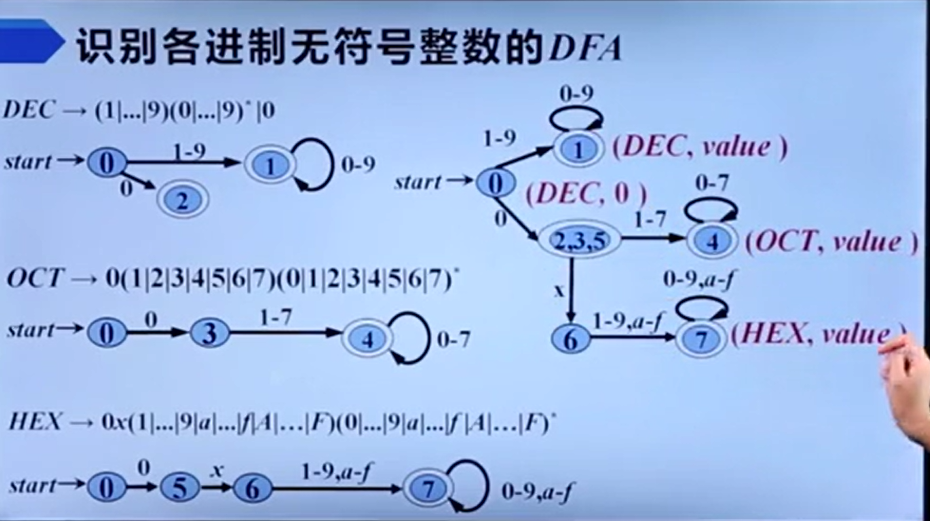
识别单词的DFA
数字

66666,还能这么捏起来
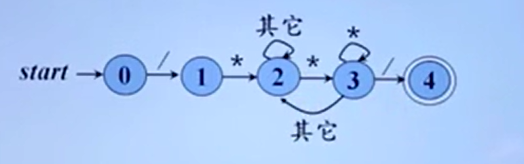
注释
识别token
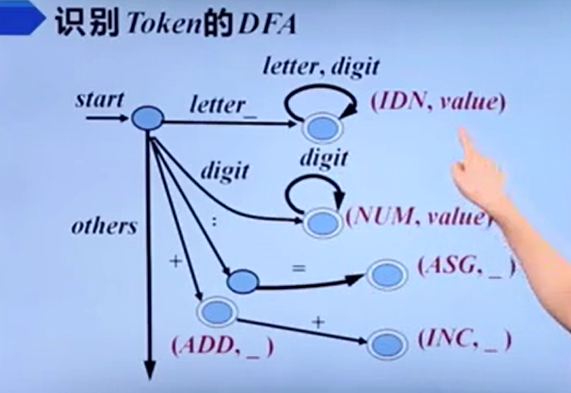
关键字是在识别完标识符之后进行查表识别的
scanner的错误处理
说实话没太看懂



第四章 语法分析
根据给定文法,识别各类短语,构造分析树。所以关键就是怎么构建分析树
自顶向下LL(1)
概念
可以看做是推导(派生)的过程。
如果同一非终结符的各个产生式的可选集互不相交,就可以进行确定的自顶向下分析:

这两个分析也是我们的分析方法需要解决的。


也就是说,在自顶向下分析时,采用的是最左推导;在自底向上分析时,最左归约和最右推导才是正道!
通用算法
例子
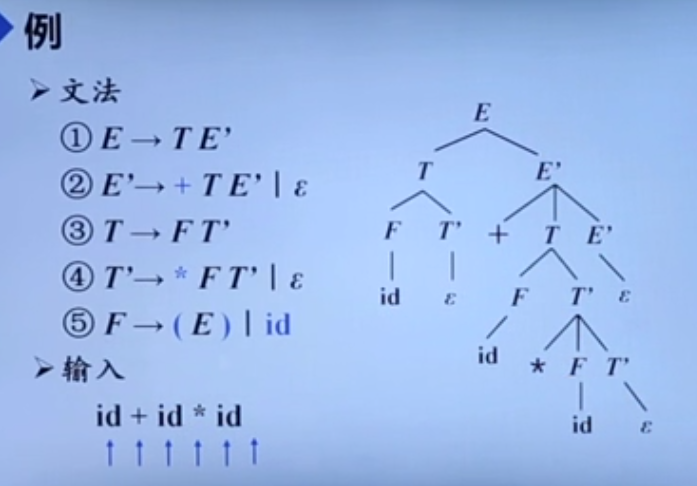
大概流程应该是,有产生式就展开,然后当产生式右部有多个候选式的时候再根据输入决定。
递归下降分析

如果有多个以输入终结符打头的右部候选,那就需要逐一尝试错了再回溯,因而效率较低。
预测分析

66666,这其实就可以类似于动态规划了吧
【感觉这里也能窥见一些算法设计的思想。
仔细想想,我们在引入动态规划时,也是这个说辞:对于一些回溯问题,回溯效率太低,所以我们就可以提前通过动态规划的思想构造一个状态转移表,到时候只需从零开始按照表进行状态转移即可。
仔细想想,这不就是这里这个预测分析提出的思想吗!真的牛逼,6666
我记得KMP算法一开始也是这个思想,感觉十分神奇】
文法转换
什么情况需要改造


消除左递归
直接左递归

这个左递归及其消除方法解释得很形象
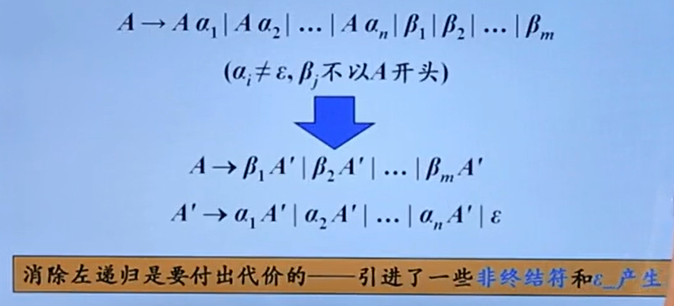
间接左递归

先转化为直接左递归
消除回溯

666666这个解读可以,感觉这个就跟:

这个“向前看”有异曲同工之妙了。
LL(1)文法
LL(1)文法才能使用预测分析技术。判断是否是LL文法就得看具有相同左部的产生式的select集是否相交。
S_文法

S文法不包含空产生式
q_文法

也就是说,B的Follow集为{b,c},只有当输入符号为b/c时才能使用空产生式。

first集和follow集不交。
这下总算知道这两个是什么玩意了。也就是这样:
输入符号与B的First集元素匹配
直接用那个产生式
否则,看输入符号是否与Follow集元素匹配
是
若B无空产生式,报错;否则,使用B的空产生式(相当于消了一个符号但不变输入带指针)
否
报错

这个感觉跟first集有点像,相当于是右部只能以终结符开始的形式,所以下面的LL文法会增强定义。
当该非终结符对应的所有SELECT集不相交,就可以进行确定的自顶向下语法分析。这个思想也将贯穿下面的LL文法

LL(1)文法


最后,如果同一非终结符的各个产生式的可选集互不相交,就可以进行确定的自顶向下分析:


总结
这几个推理下来,真是让人感觉酣畅淋漓!
确定的自顶向下分析的核心就是,给定一个当前所处的非终结符和一个输入字符[E, a],我们可以唯一确定一个产生式P用于构建语法分析树。

也即,同一个非终结符的所有产生式的SELECT集必须是不交的【才能确保选择产生式的唯一性】。因而,问题就转化为了如何让SELECT集不交。
我们需要对空产生式和正常产生式的SELECT集计算做一个分类讨论。
空产生式
由于可以推导出空,相当于把该符号啥了去读下一个符号,因此我们的问题就转化为输入字符a是否能够跟该符号后面紧跟着的字符相匹配。而紧跟着的字符集我们将其成为FOLLOW集,如果a在follow集中,那么就可以接受,否则不行。
对于LL(1)文法,相当于是进一步处理了简介推出空的串:
由于α串->*空,则α串必定仅由非终结符构成。那么它能推导出的所有可能即为SELECT集。故而为
First(α)∪Follow(α)非空产生式
很简单,就是其First集。
故而,只需要让这些计算出来的First集合不交,就能进行确定的自顶向下语法分析,构造确定的语法分析树。不得不说真的牛逼。
感觉其“预测分析”的“预测”主要体现在对空产生式的处理上。
总算懂了为什么LL(1)能够解决这个回溯效率太低的问题了,太牛逼。不过问题是怎么转化为LL(1)呢()上面的消除回溯和左递归只是一部分而已吧。
预测分析法

这个消除二义性是啥玩意?二轮的时候看看PPT怎么讲的
递归的预测分析


66666,它这个计算follow集的方法就很直观
declistn有个空产生式,那么我们看得看②,而②的declistn排在最后,也就是说declistn的follow集就是其左部declist的follow集【6666】,所以我们看①,可以发现declist后面为:。
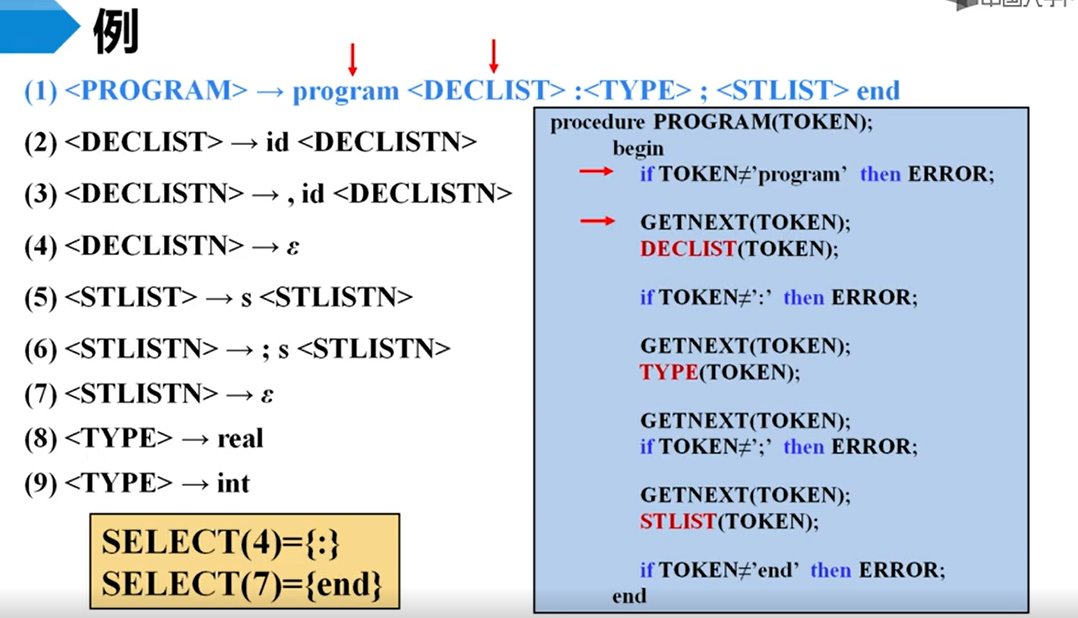
如果是终结符,就直接==比较;非终结符,就把token传入到其对应的过程。
非递归的预测分析
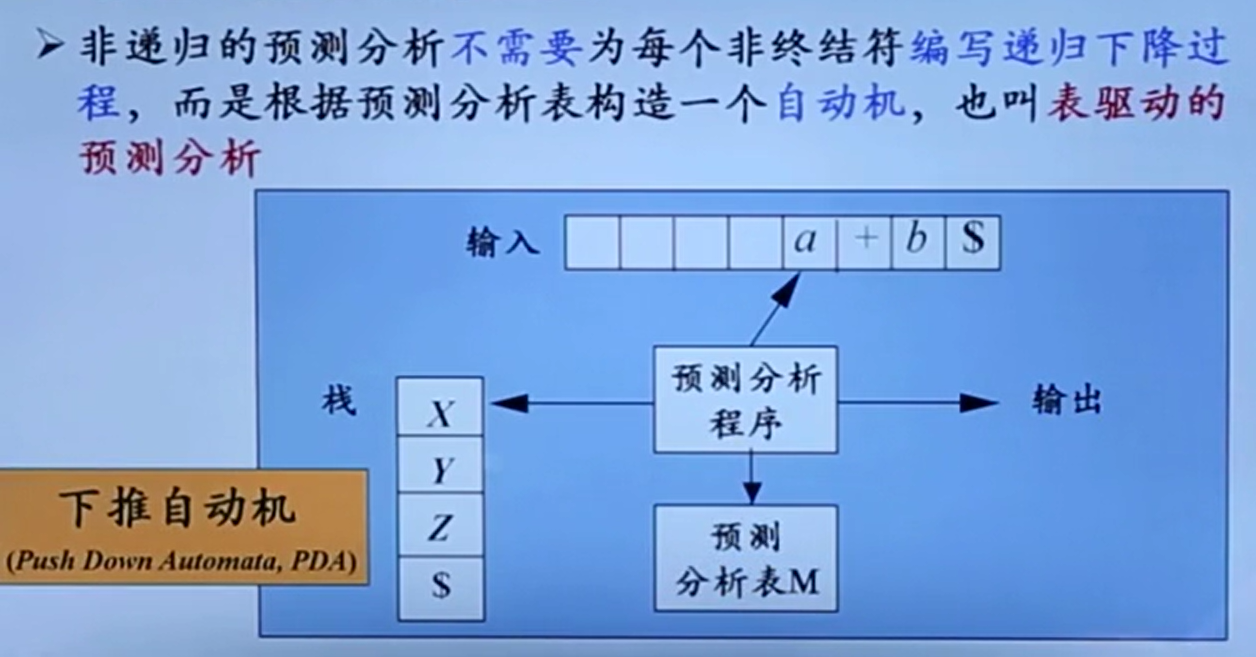
66666
感觉从中又能窥见动态规划的同样思想了。下推自动机其实感觉就像是递归思想(或者说顺序模拟递归,因为它甚至有一个栈,出栈相当于达成条件递归return),动态规划的话可能有点像是把每个不同状态以及不同状态时的栈顶元素整成一个2x2的表,所以感觉思想类似。
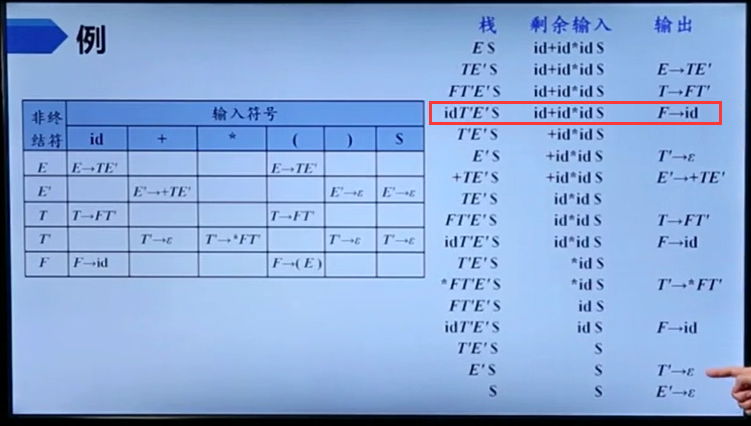
注意,是栈顶跟输入一样都是非终结符才会移动指针和出栈
值得注意的是,输出的产生式序列就对应了一个最左推导。

错误处理


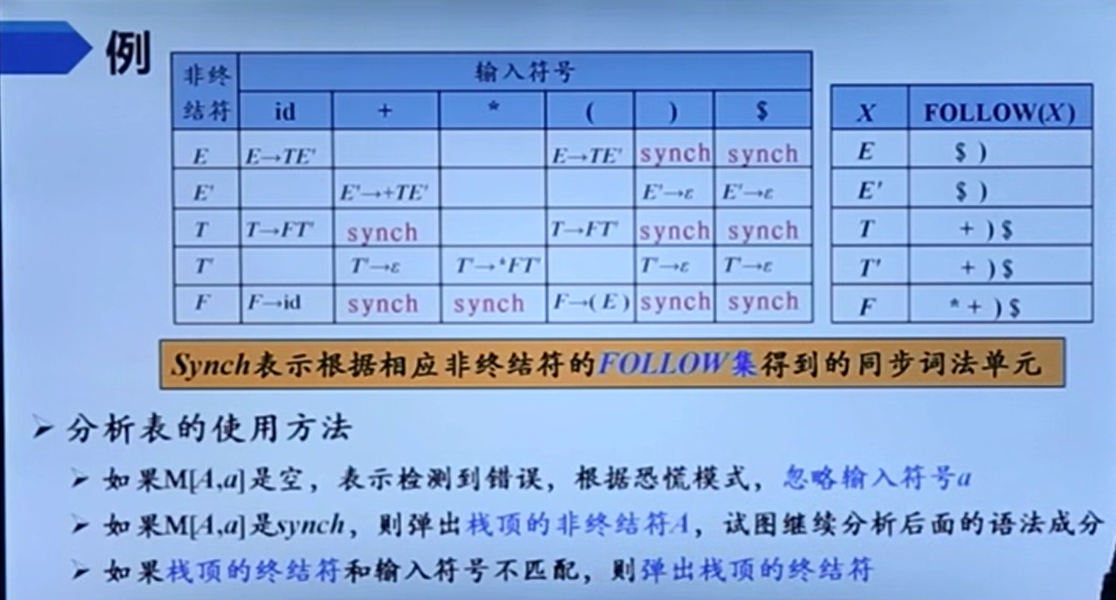
其实也挺有道理,栈顶是非终结符,但是输入是它的follow集,那我们自然而然可以想到把这b赶跑,看看下面有没有真的它的follow集在嗷嗷待哺。
自底向上语法分析
概述
正确识别句柄是一个关键问题。
句柄:当前句型的最左直接短语。【最左、子树高度为2】
自底向上

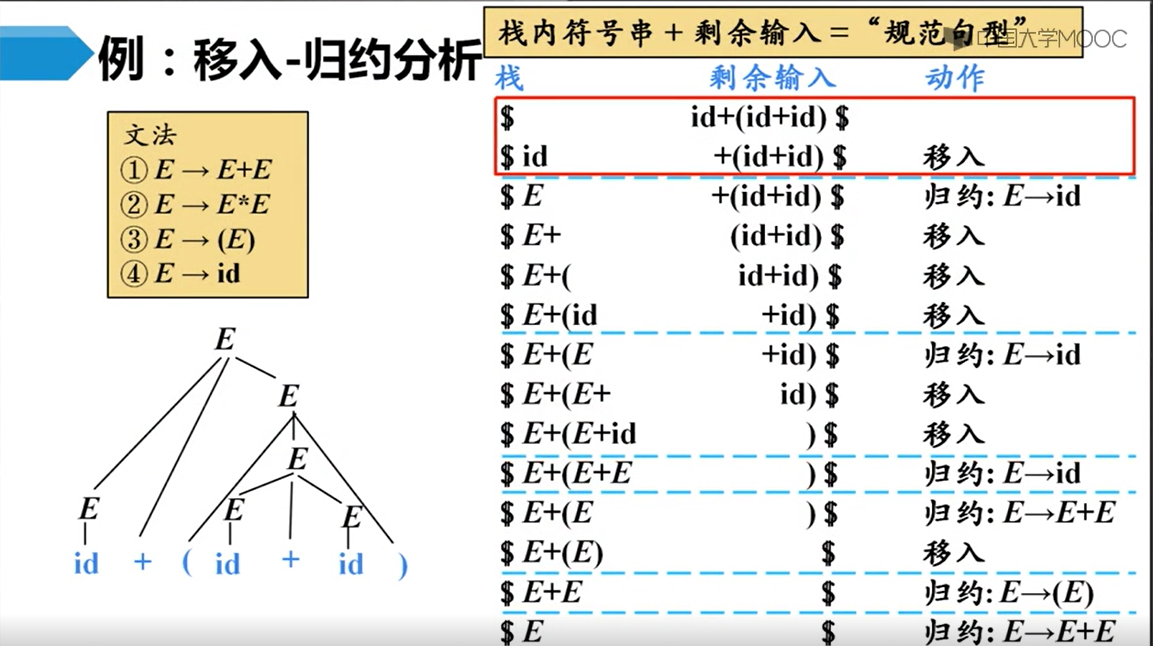
每次句柄形成就将它归约,因而保证一直是最左归约(recall that,句柄一定是某个产生式的右部,并且每次最左句柄一旦形成就归约)

正如上面的LL分析,每次推导要选择哪个产生式是一个问题;这里的LR分析,每次归约要选择哪个产生式,也即正确识别句柄,也是一个关键问题。
所以,我们应该把句柄定义为当前句型的最左直接短语。
如下图所示,左下角是当前句型(画红线部分)的语法分析树,红字为在栈中的部分,蓝字为输入符号串剩余部分。当前句型的直接短语(相当于根节点的高度为二的子树,或者说子树前两层)有两个,一个是以<IDS>为根节点的<IDS> , iB,另一个是<T>为根节点的real。
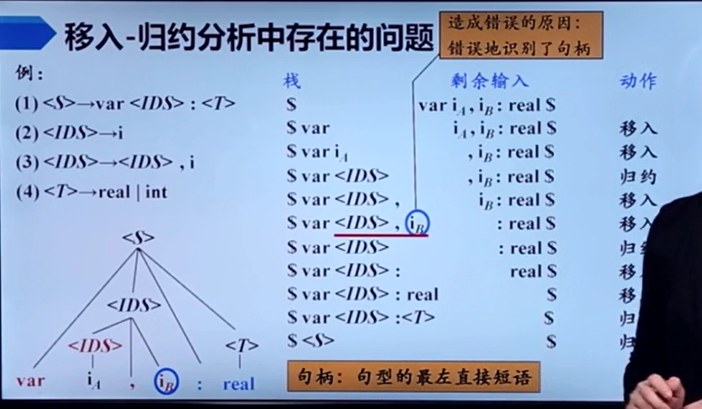
而LR分析技术的核心就是正确地识别了句柄。
LR文法

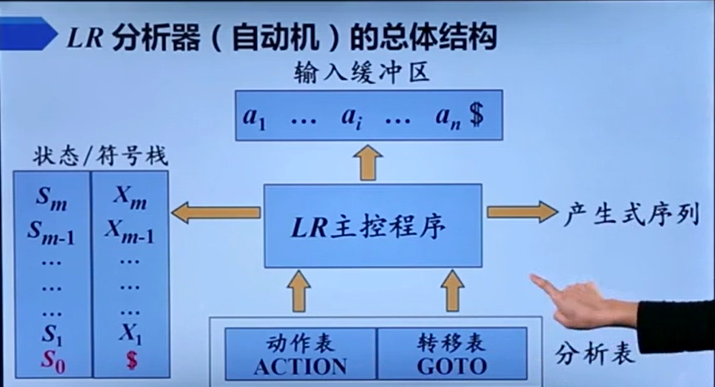
也就是说LR技术就是用来识别句柄的,识别完了句柄就可以构建类似自顶向下的预测分析那样的自动机表来进行转移。

移进状态
·后为终结符
待约状态
·后为非终结符
归约状态
·后为空
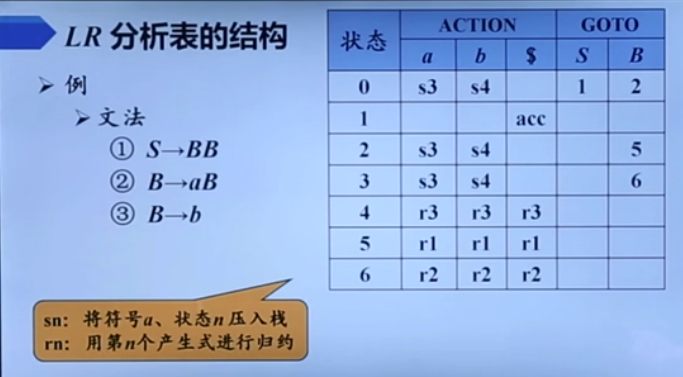
以前感觉一直很难理解GOTO表的作用,现在感觉稍微明白了点了,你想想,归约之后的那个结果是不是有可能是另一个产生式的右部成分之一,也即一个新的句柄?并且这个也是由你栈顶刚归约好的那个左部和下面的输入符号决定的。那么你自然而然需要切换一下当前状态,以便之后遇到那个产生式的时候能发现到了。
那么,剩下的问题就是如何构造LR分析表了:

算符分析

也就是它会整一个终结符之间的优先级关系。。。


也就是说:
a=b
相邻
a<b
也即在A->aB时,b在FIRSTOP(B)中(理解一下,这个First指在前面。。。)
a>b
也即在A->Bb时,a在LASTOP(B)中(理解一下,这个LAST指在后面。。。)


我服了

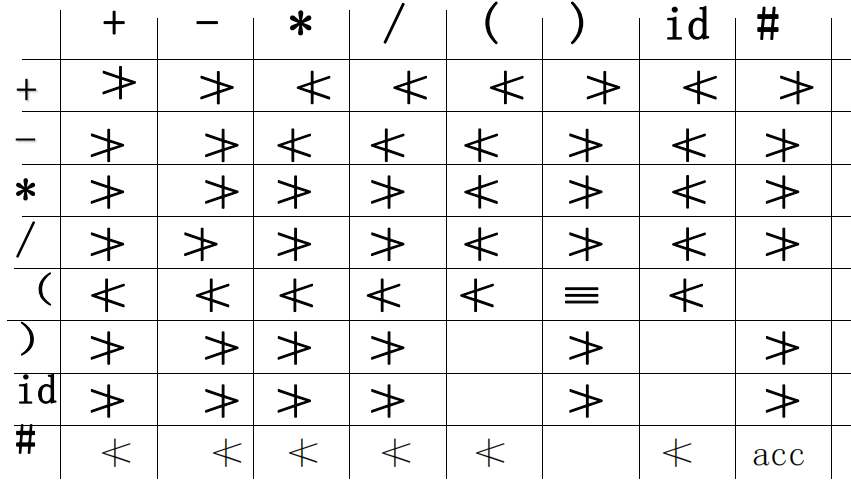
好像#这个固定都是,横的为左,竖的为右
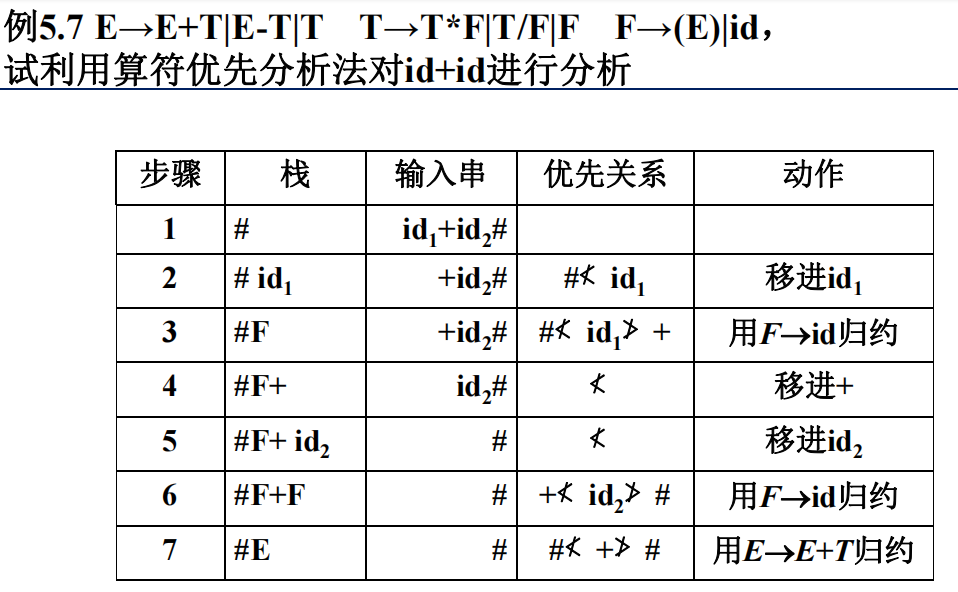
根据优先关系来判断移入和归约

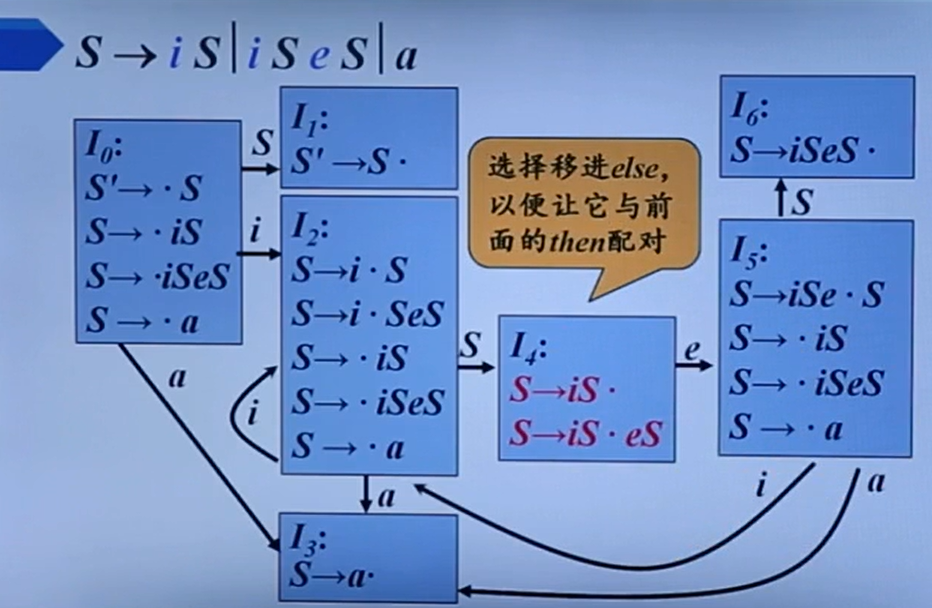
LR分析
LR(0)
每个分析方法其实都对应着一种构造LR分析表的方法。
LR(0)通过构造规范LR0项集族,从而构造LR分析表,从而构造LR0 DFA来最终进行语法分析。
每一个项目都对应着句柄识别的一个状态。
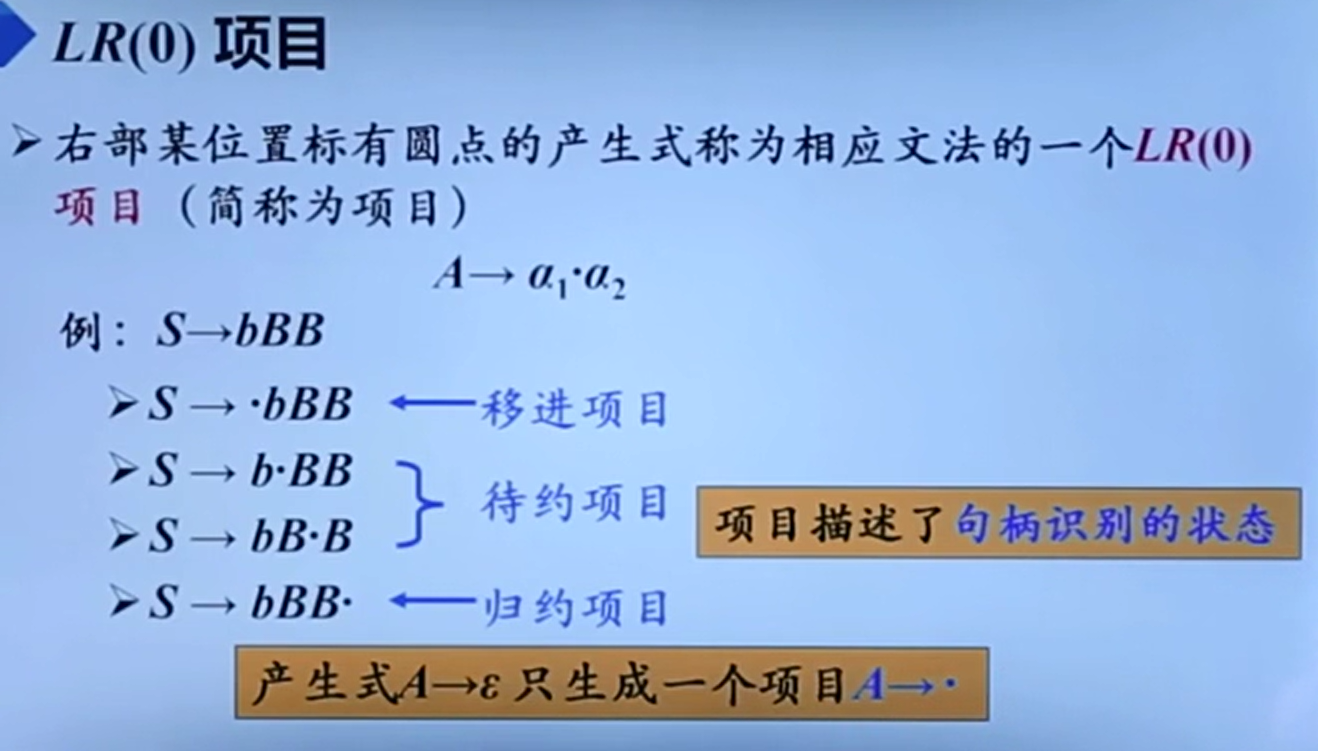



而肯定不可能整那么多个状态,所以我们需要进行状态合并。(这样也就很容易理解LR的状态族构建了。)

它这里也很直观解释了为什么点遇到非终结符就需要加入其对应的所有产生式,因为在等待该非终结符就相当于在等待它的对应产生式的第一个字母。
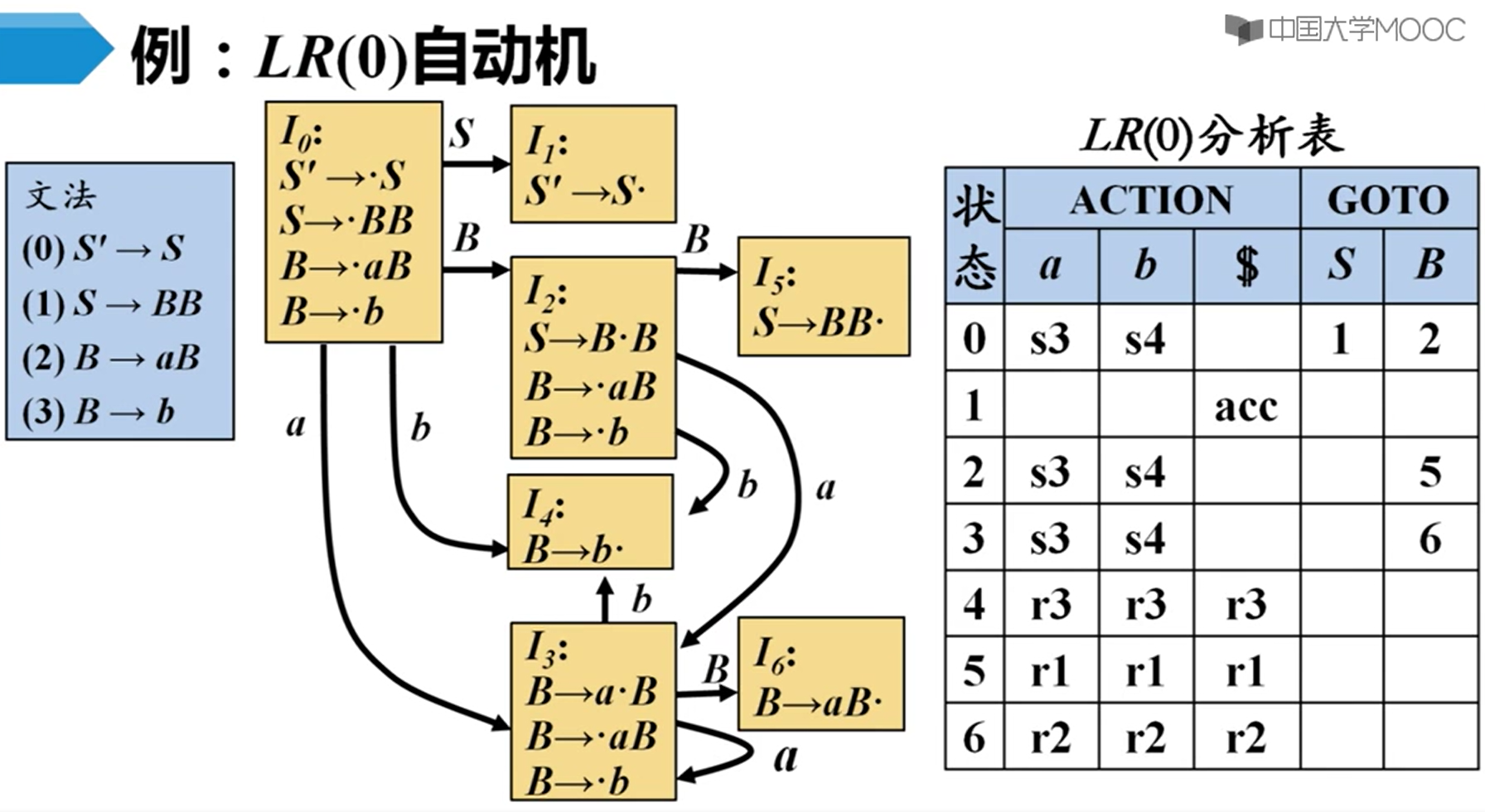

上面这东西就是这个所谓的规范LR(0)项集族了。


但是会产生移进归约冲突:
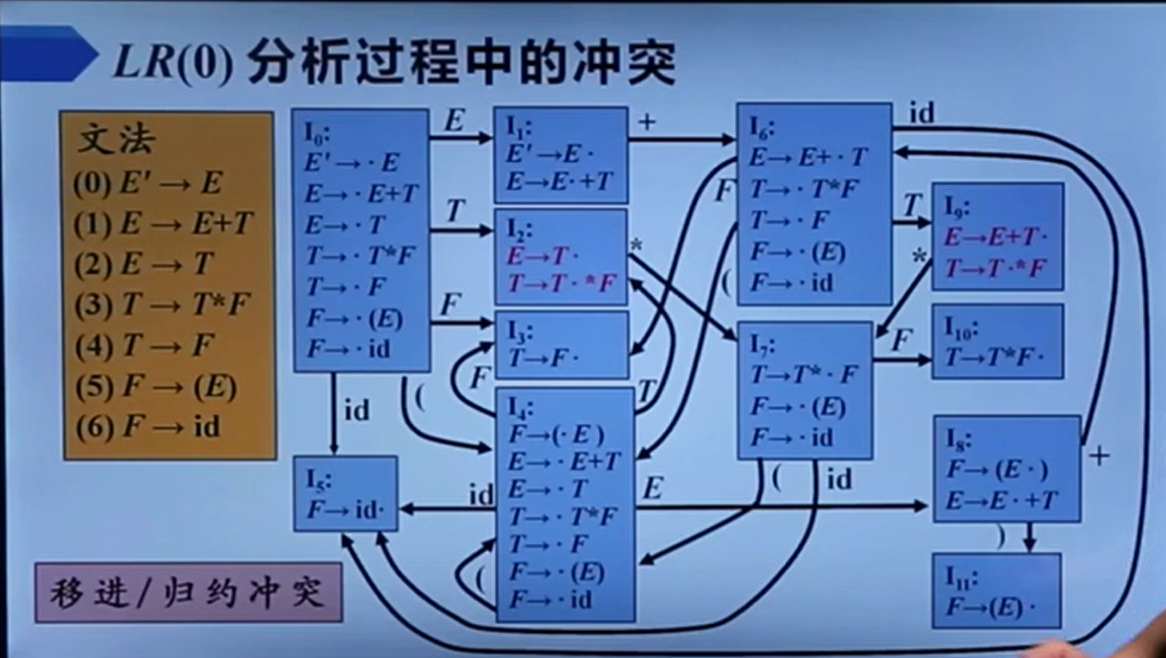
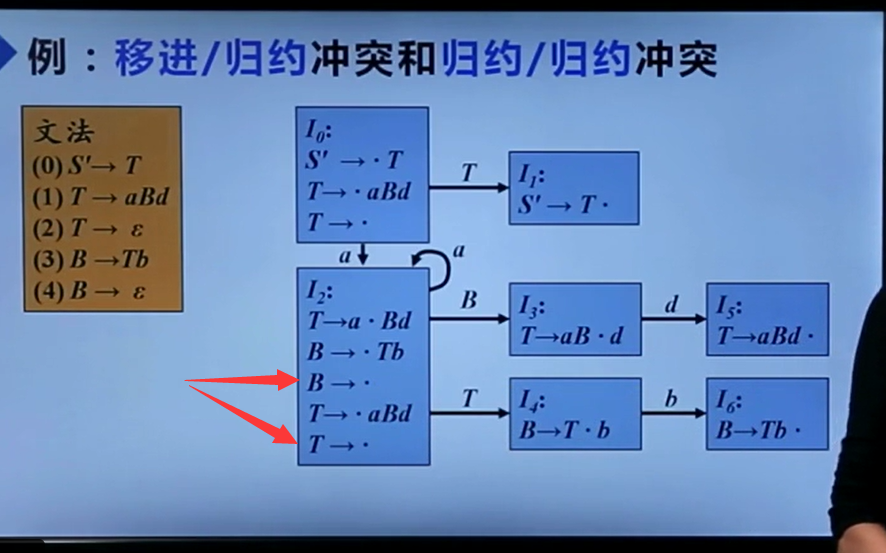
还有归约归约冲突:
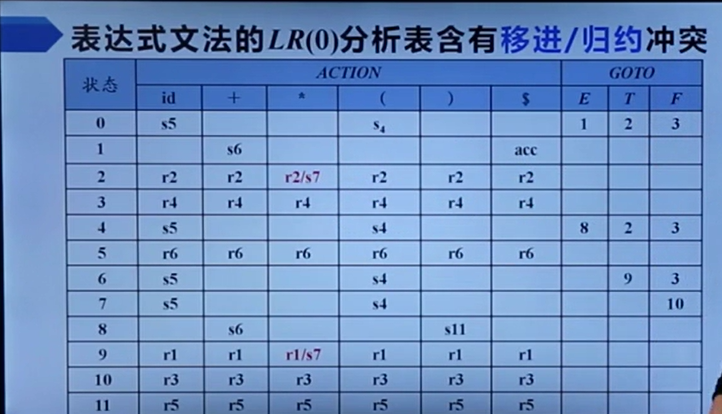
所以我们就把没有冲突的叫LR(0)文法。

感觉上述两个问题都是因为有公共前缀【包括空产生式勉强也能算是这个情况】,导致信息不足无法判断应该怎么做,多读入一个字符(也即LR(1))应该可以有效解决该问题。
SLR分析
其实本质还是识别句柄问题,也即此时是归约还是移入,得看是不是句柄。故而LR0信息已经不能帮我们识别句柄了。
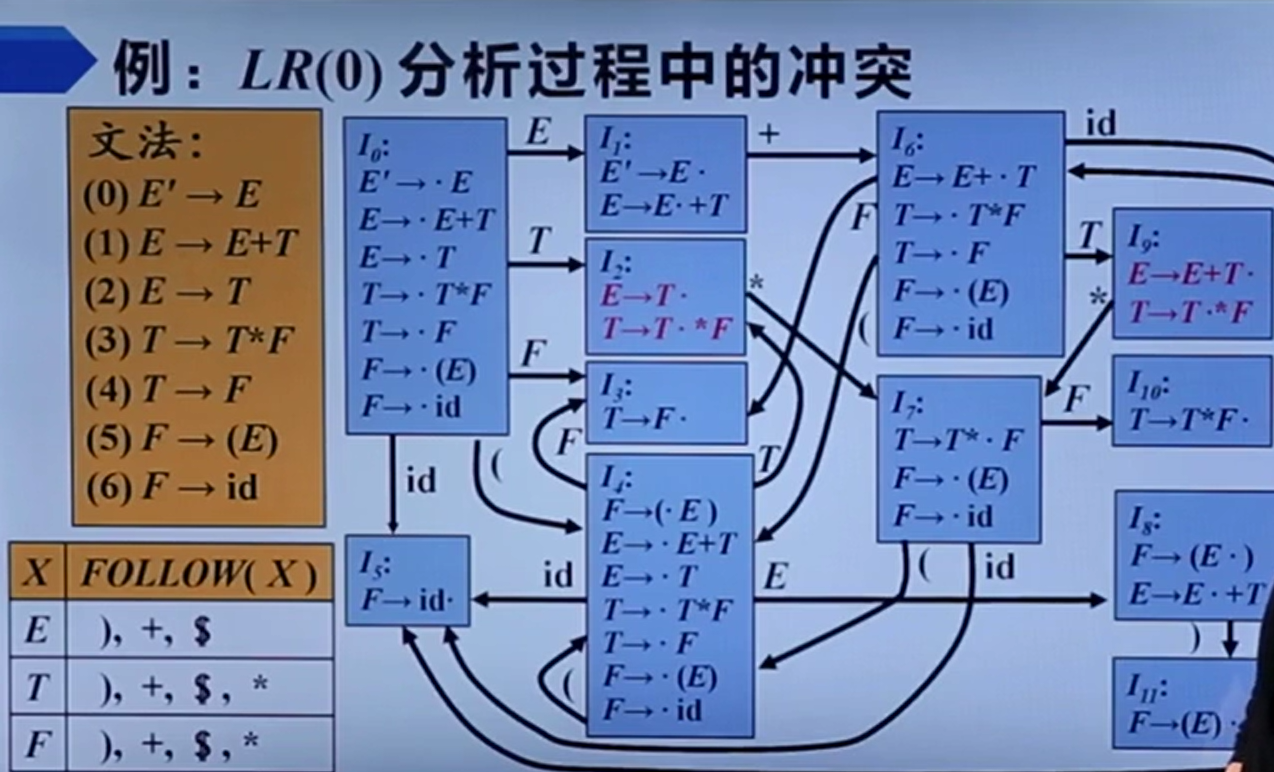
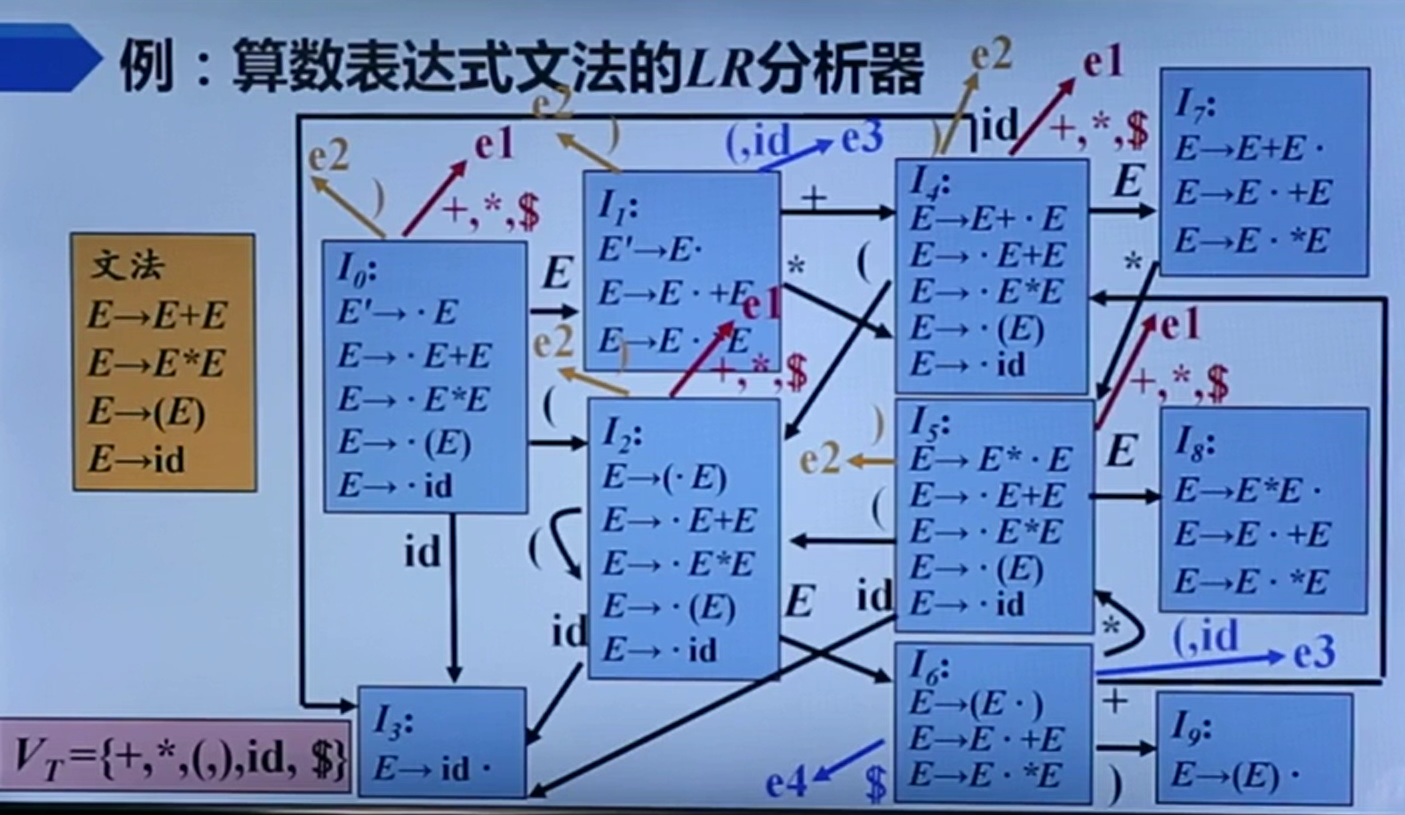
Follow集可以帮助我们判断。由该状态I2可知,输入一个*应该跳转到I7。如果在I2把T归约为一个E,由Follow集可知E后面不可能有一个*,也就说明在这里进行归约是错误的,应该进行移入。
这种依靠Follow集和下一个符号判断的思想,就会运用在SLR分析中。

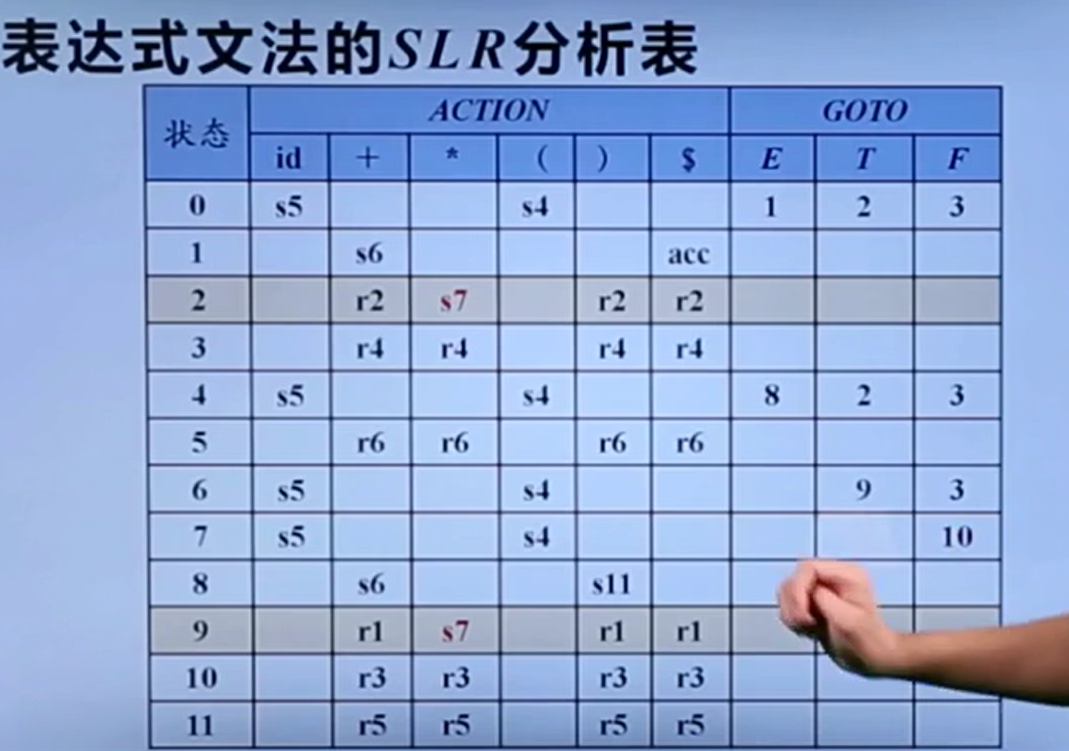

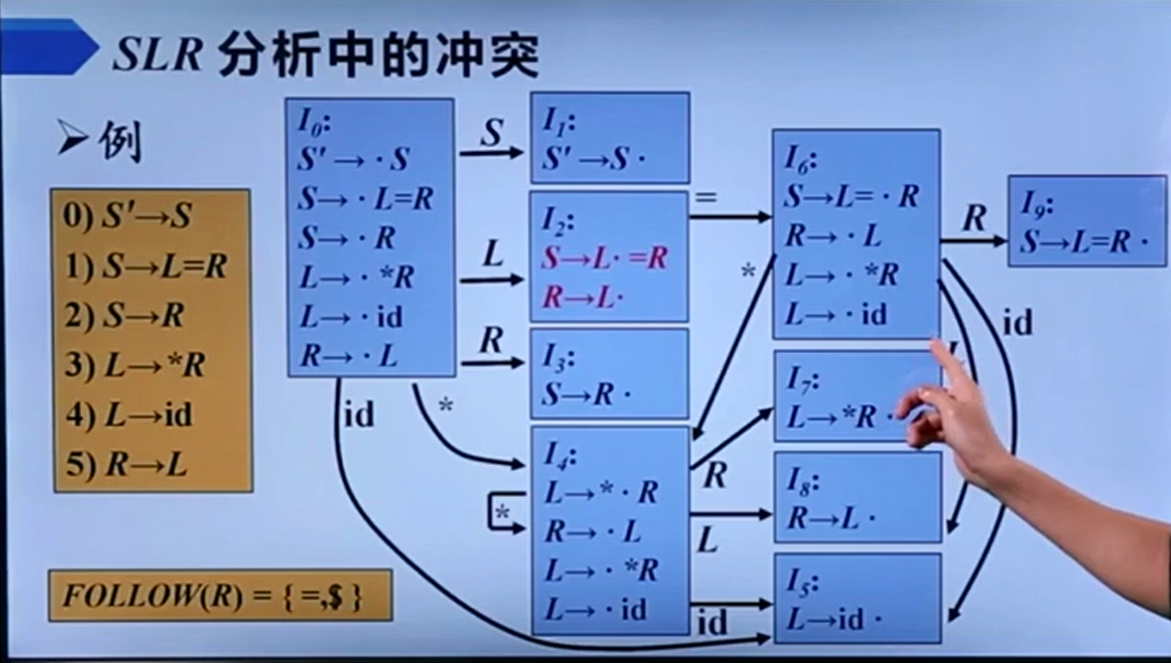
但值得注意的是SLR分析的条件还是相对更严苛,它要求移进项目和归约项目的Follow集不相交,所以它也会产生像下图这样的冲突:
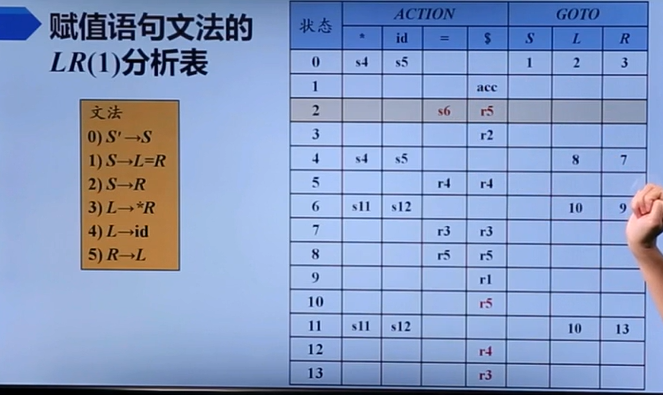
LR(1)
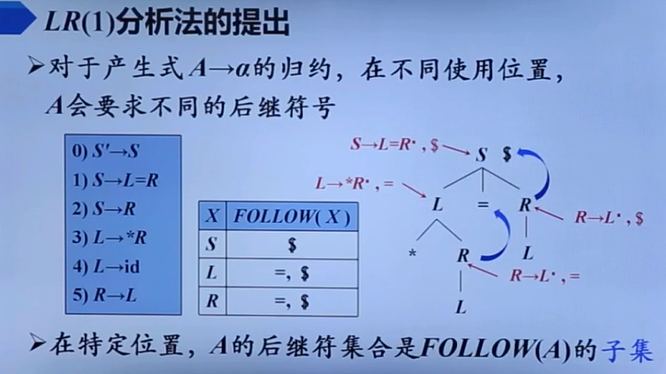
SLR将子集扩大到了全集,显然进行了概念扩大。
含义为只有当下一个输入符号是XX时,才能运用这个产生式归约。这个XX是产生式左部非终结符的Follow子集。

这玩意只有归约时会用到,这个很显然,毕竟前面提到的LR0的问题就是归约冲突。
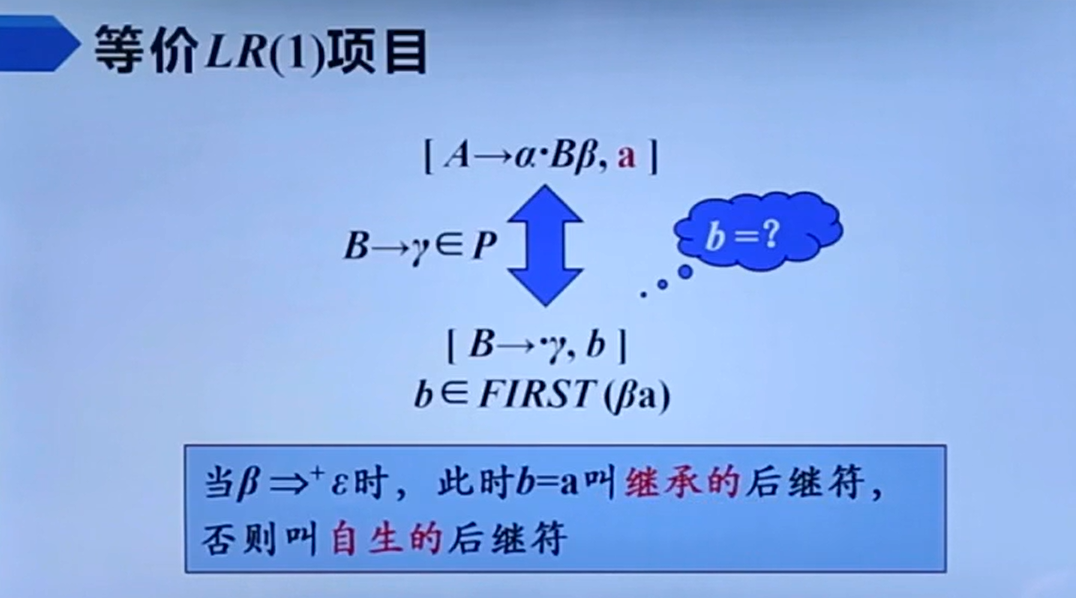
对了,值得注意的是这个FIRST(βa),它表示的并不是FIRST(a)∪FIRST(β),里面的βa应该取连接意,也即,当β为非空时这玩意等于FIRST(β),当β空时这玩意等于FIRST(a)。
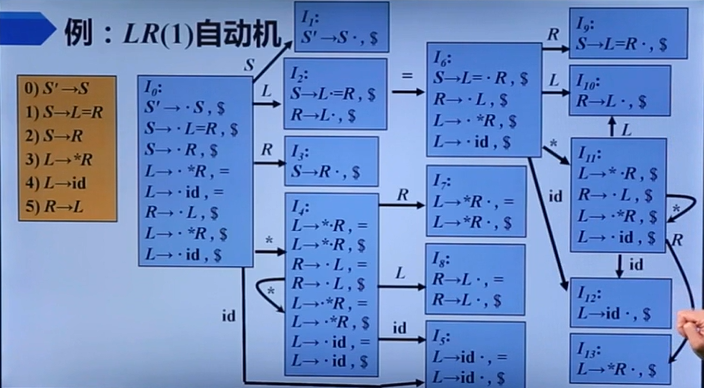
刚刚老师对着这个状态转移图进行了一番强大的看图写话操作,我感觉还是十分地牛逼。她从这个图触发,讲述了状态I2为什么不能对R->L进行归约。
假如我们进行了归约,那么我们就需要弹出状态I2回到I0,压入符号R,I0遇到符号R进入了I3,I3继续归约回到I0,I0遇到符号S到状态I1,但1是接收状态,下一个符号是=不是$,所以错了。
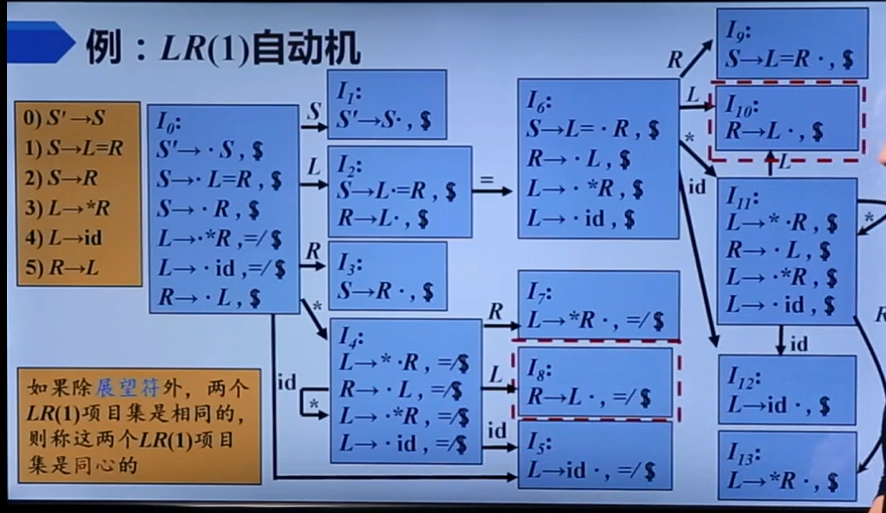
比如说I8和I10就是同心的。左边的那个实际上是LR0项目集,所以这里的心指的是LR0。

LALR分析
然而,LR(1)会导致状态急剧膨胀,影响效率,所以又提出了个LALR分析。

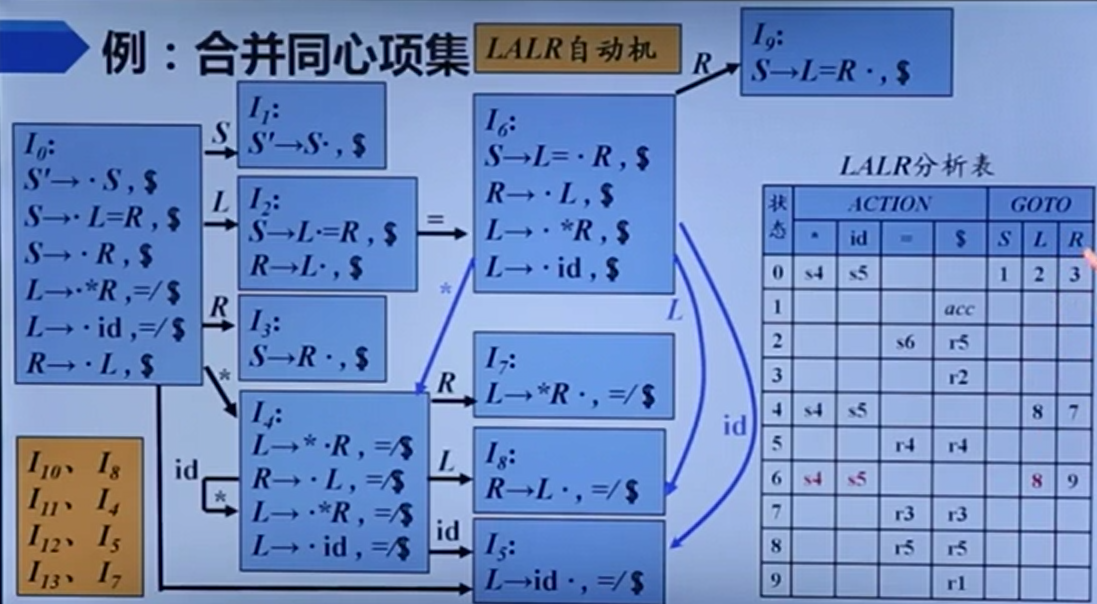
跟前面的SLR对比可以发现,相当于它就是多了个逗号后面的条件。但是这是可以瞎合的吗?不会出啥问题不。。。
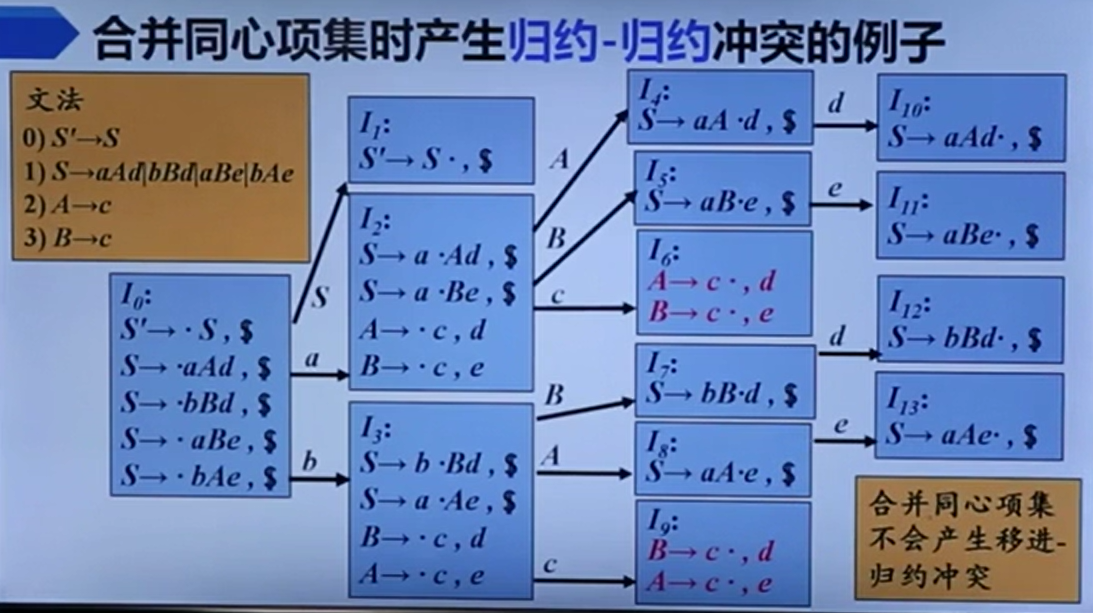
好吧问题这就来了,LALR可能会产生归约归约冲突。但值得注意的是,它不可能出现归约移入冲突,因为LR1没有这个东西,而LALR只是修改右边的符号,所以也不会有这个。
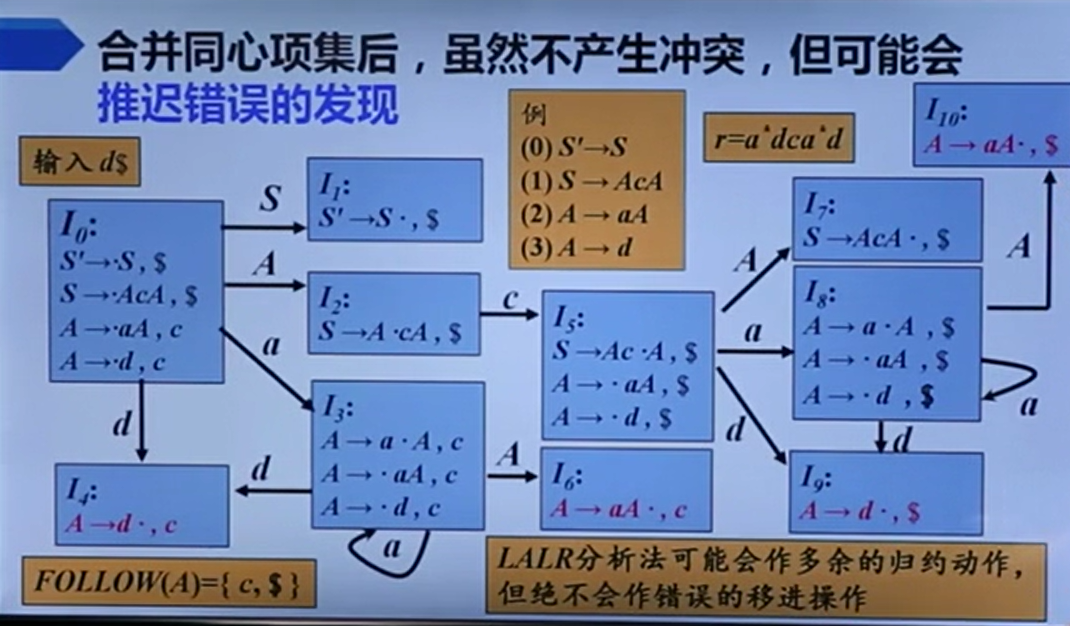
因为LALR实际上是合并了展望符集合,这东西与移进没有关系,所以只会影响归约,不会影响移进。

LALR可能会产生归约归约冲突。但值得注意的是,它不可能出现归约移入冲突,因为LR1没有这个东西,而LALR只是修改右边的符号,所以也不会有这个。
它有可能做多余的归约动作,从而推迟错误的发现。
形式上与LR1相同;大小上与LR0/SLR相当;分析能力介于SLR和LR1之间;展望集仍为Follow集的子集。
总结
感觉一路看下来,思路还是很流畅的。LR0会产生归约移进冲突和归约归约冲突,所以我们在归约时根据下一个符号是在移进符号还是在Follow集中来判断是要归约还是要移进。但是SLR条件严苛,对于那些移进符号集和Follow集有交的不适用,并且这种情况其实很普遍。加之,出于这个motivation:其实不应该用整个Follow集判断,而是应该用其真子集,所以我们开发出来个LR1文法。然后LR1文法虽然效果好但是状态太多了,所以我们再次折中一下,造出来个效果没有那么好但是状态少的LALR文法。
二义性文法的LR

所以我们可以用LR对二义性文法进行分析
我们可以通过自定义规则来消除二义性文法的归约移入冲突
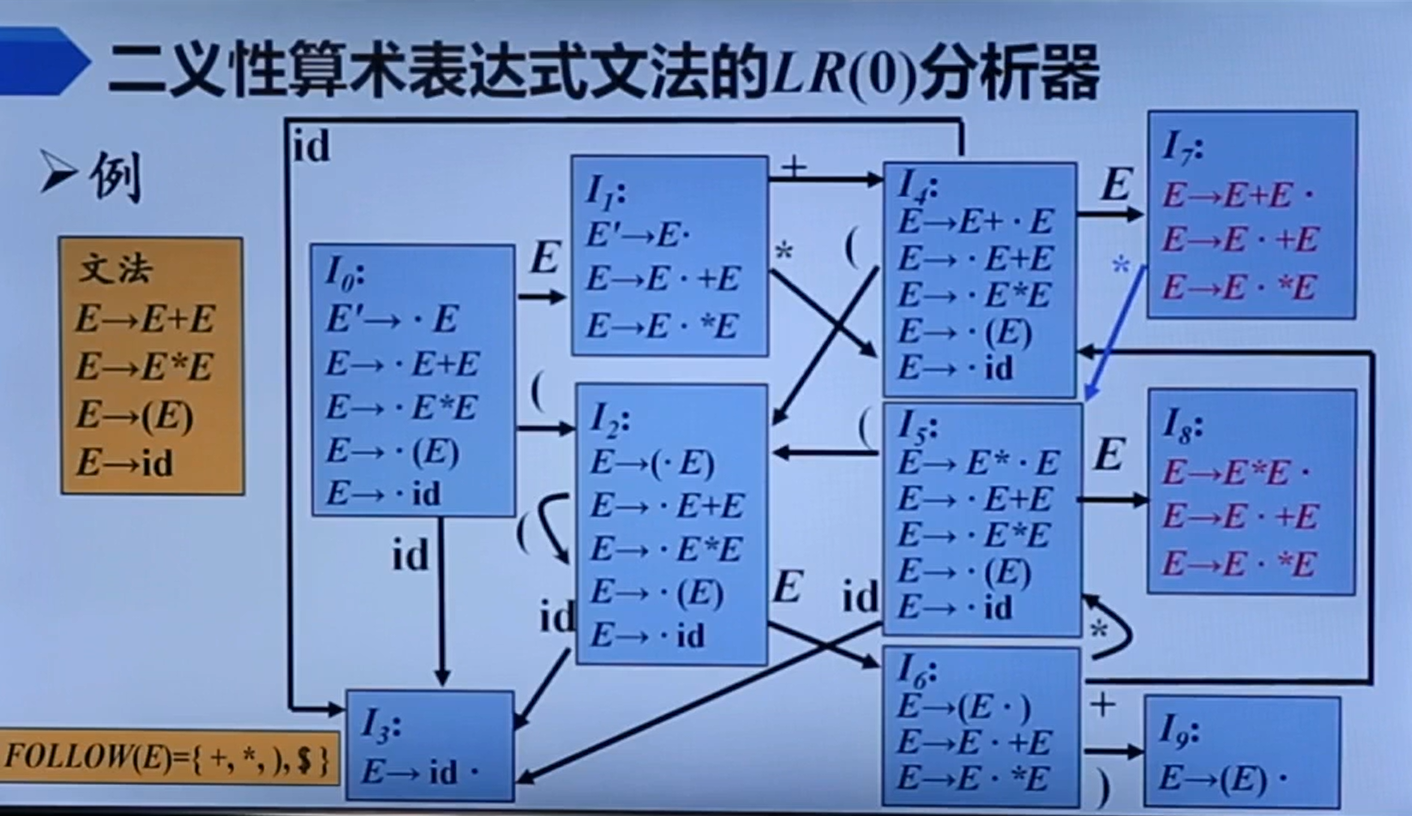
对于状态7,此时输入+ or *会面临归约移入冲突。由于有E->E+E归约式子,可以知道此时栈中为E+E。当输入*,由于*运算优先级更高,所以我们在此时进行移入动作转移到I5;当输入+,由于同运算先执行左结合,所以我们此时可以安全归约。
对于状态8,由于*运算比+优先级高,且左结合,所以始终进行归约。
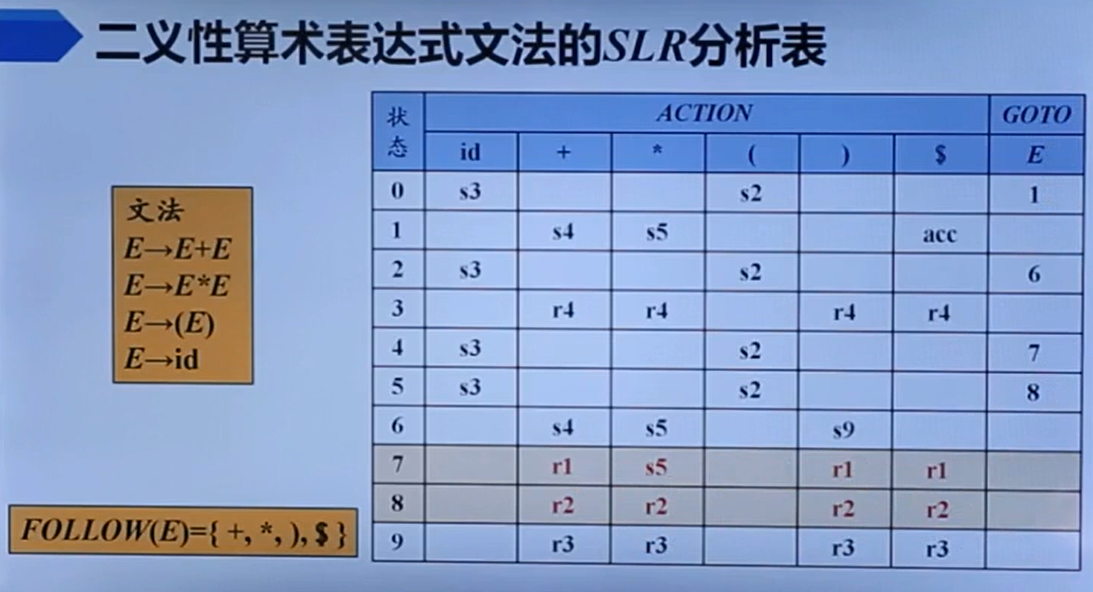


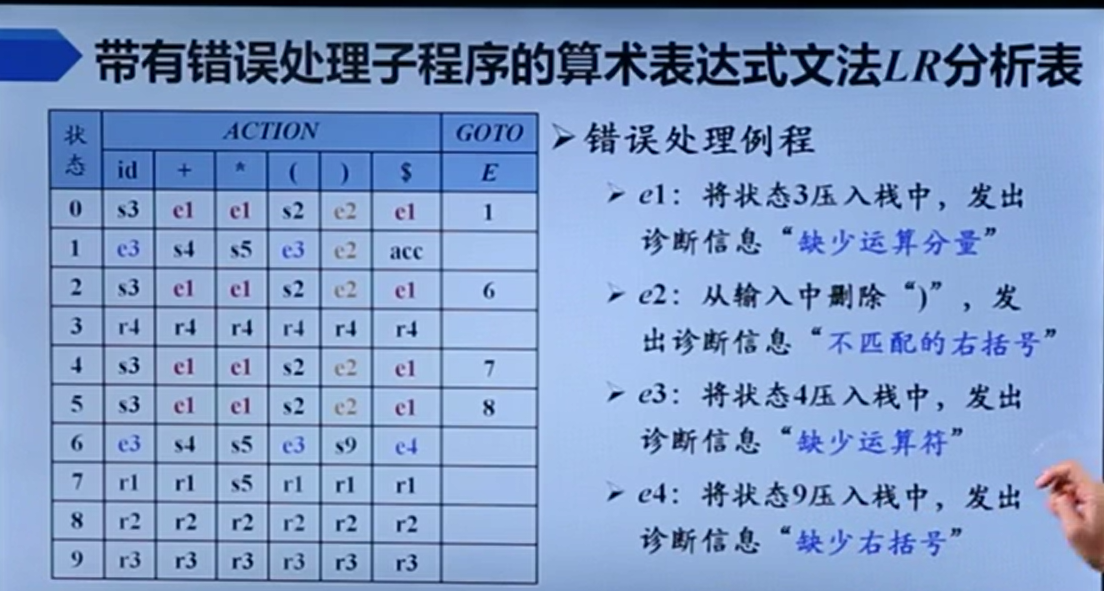
错误检测


它这个意思大概就是,符号栈和状态栈都一直pop,直到pop到一个状态,GOTO[符号栈顶,状态栈顶]有值【注意,始终保持符号栈元素+1 == 状态栈元素数+1】。然后,一直不断丢弃输入符号,直到输入符号在A的Follow集中。此时,就将GOTO值压入栈中继续分析。
【这其实也很有道理。如果输入符号在A的Follow集,说明A之后很有可能可以消耗这个输入符号。】
第五章 语义分析
注意:
- 语义翻译包含语义分析和中间代码生成
- 这笔包含了语法分析、语义分析、中间代码生成
思想:
- 通过为文法符号设置语义属性,来表达语义信息
- 通过与产生式(语法规则)相关联的语义规则来计算符号的语义属性值
也可能是先入为主吧,感觉用实验的方法来理解语义分析比较便利。语义分析相当于定义一连串事件,附加在每个产生式上。当该产生式进行归约的时候,就执行对应的语义事件。而由于执行语义分析时需要的符号在语法分析栈中,所以我们也同样需要维护一个语义分析栈,在移进时也需要进栈。
SDD/SDT概念
语义分析一般与语法分析一同实现,这一技术成为语法制导翻译。


SDD

可以回忆一下实验,相当于对每个产生式进行一个switch-case,然后依照产生式的类别和代码规则进行出栈入栈来计算属性值。
SDT


SDD

概念
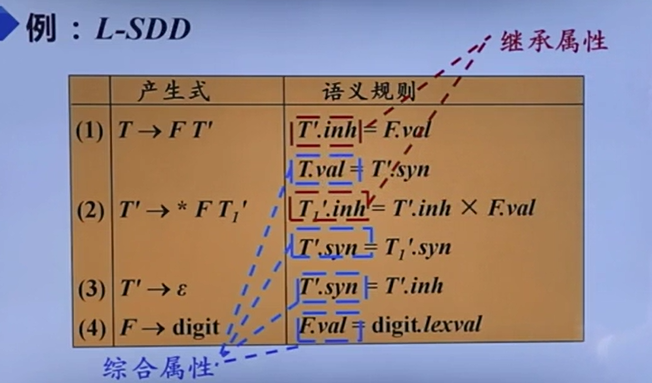
一个很简单区分综合属性和继承属性的方法,就是如果定义的是产生式左部的属性,那就是综合属性;右部,那就是继承属性
综合属性

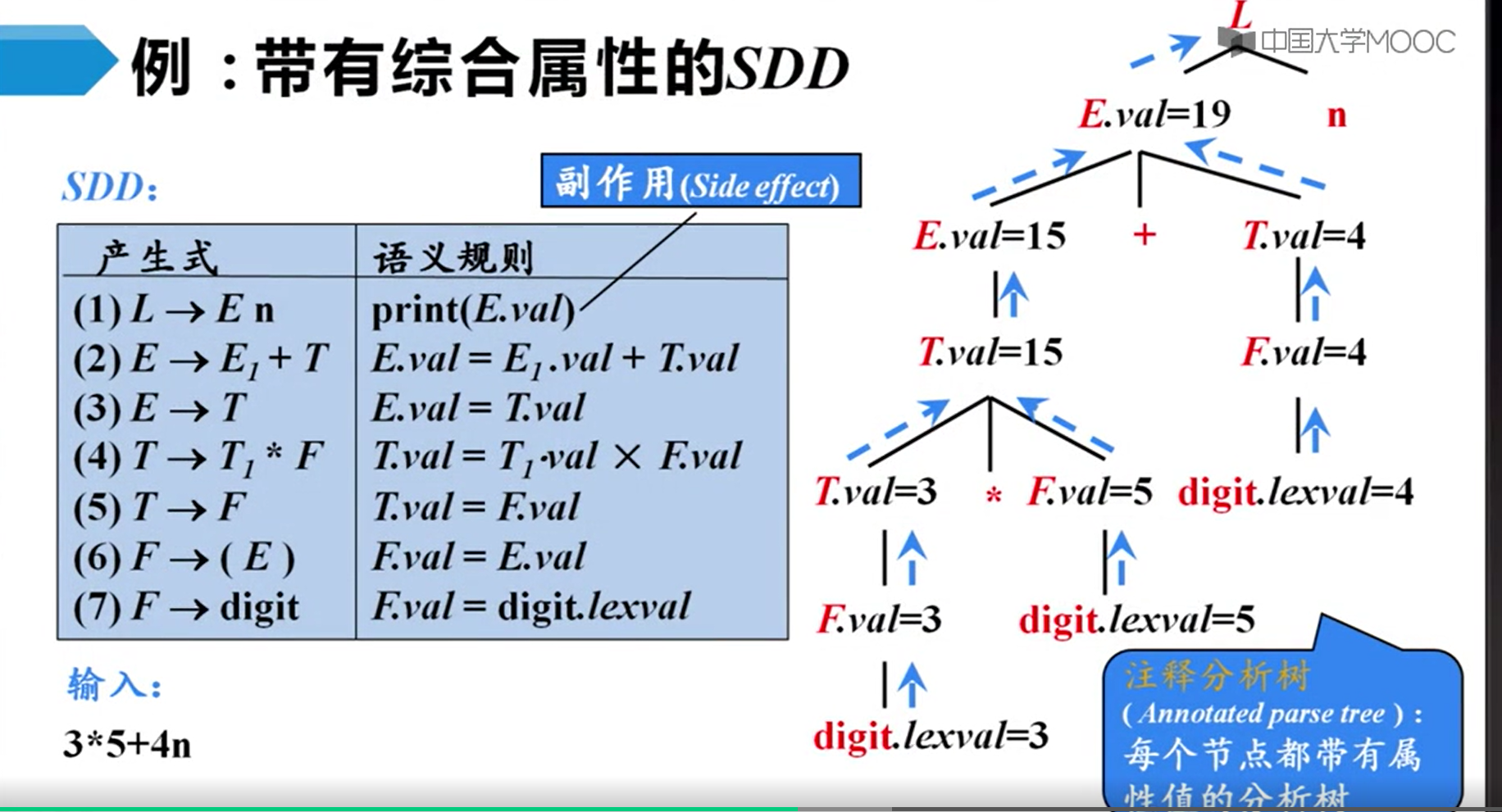
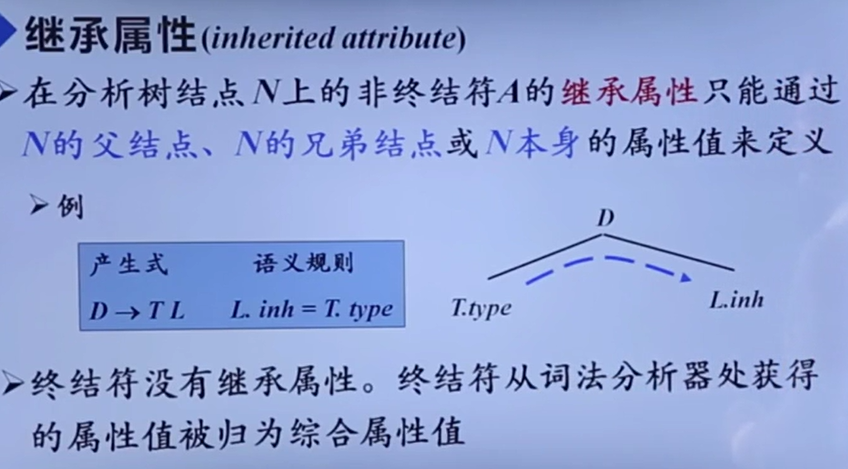
继承属性
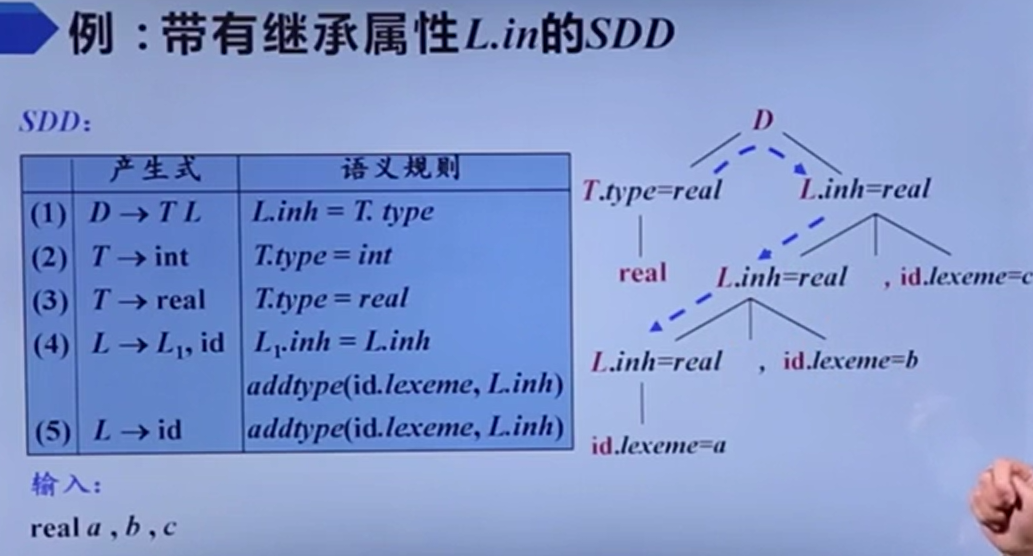
这个东西就是我们实验里写的,副作用也是更新符号表。
属性文法
没有副作用的SDD称为属性文法。
求值顺序

而感觉语法分析这个过程的产生式归约顺序就能一定程度上表示了这个求值顺序
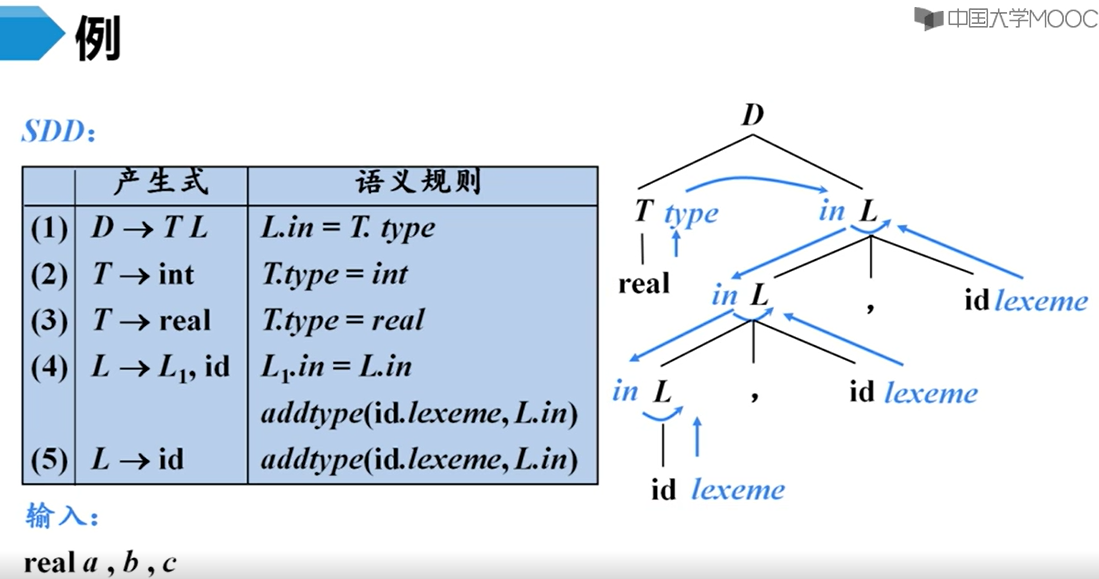
- 继承属性放在结点左边,综合属性放在结点右边
- 如果属性值A依赖于属性值B,那么就有一条从B到A的箭头【B决定A】
- 对于副作用,我们将其看作一个虚综合属性【注意是综合的,虽然它看起来既由兄弟结点决定也由子节点决定】
- 可行的求值序列就是拓扑排序

蛤?这不是你自己规则设计有问题吗,关我屁事

其实我还是不大理解,因为这个规则不是user定义的吗?所以产生环不也是它的事,难道说自顶向下或者自底向上分析还能优化SDD定义??
感觉它意思应该是这样的,有一个方法能绝对不产生循环依赖环,也即将自底向上/自顶向下语法分析与语义分析结合的这个方法。这个方法就是它说的真子集。
所以我们接下来要研究的就是什么样的语义分析可以用自顶向下or自底向上语法分析一起制导。
S-SDD

那确实,你自底向上想要计算继承属性好像也不大可能
L-SDD


对应了自顶向下的最左推导顺序
S-SDD包含于L-SDD
SDT

S-SDD -> SDT


当归约发生时执行对应的语义动作
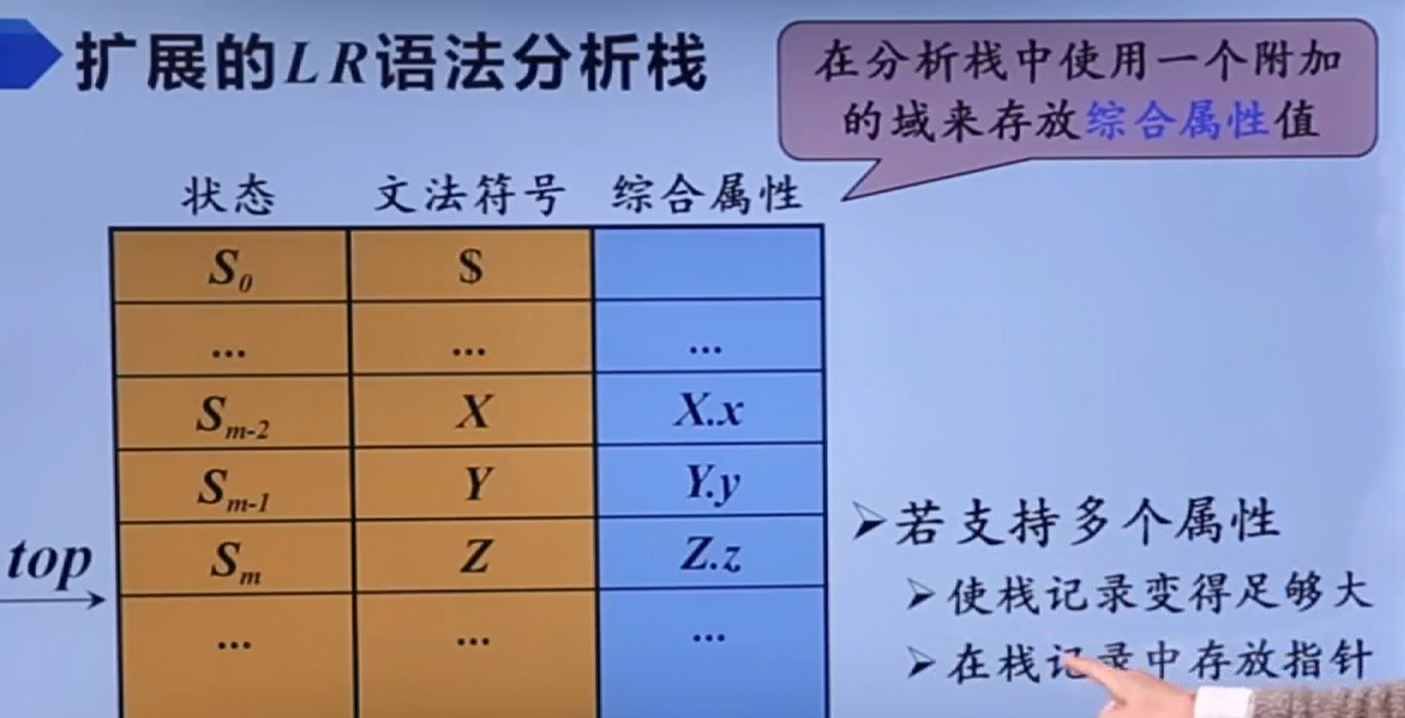
还需要加个属性栈
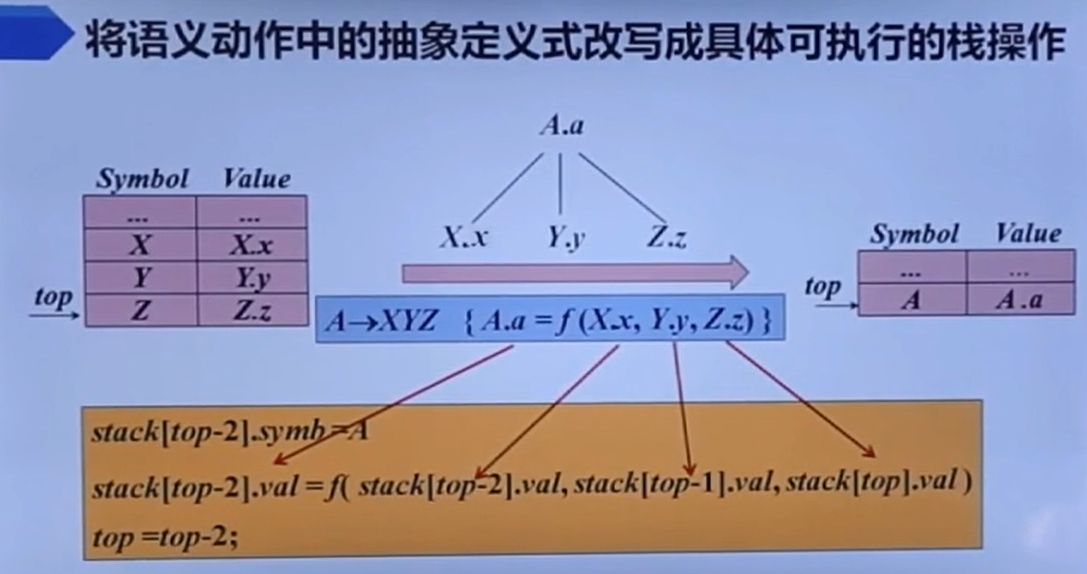
所以S-SDD+自底向上其实很简单,因为只需在归约的时候进行语义分析,在移进的时候push进属性栈就行了。

具体的S-SDD结合语法分析的分析过程可以看视频。
这个例子还算简单的,毕竟只是综合属性的计算而已,只需要加个属性栈,保存值就行了。
我们可以来关注一下这个SDT的设计,也很简单。可以产生式和语义规则分离看待,这也给我们以后设计提供一定的启发。
L-SDD -> SDT



非递归的预测分析
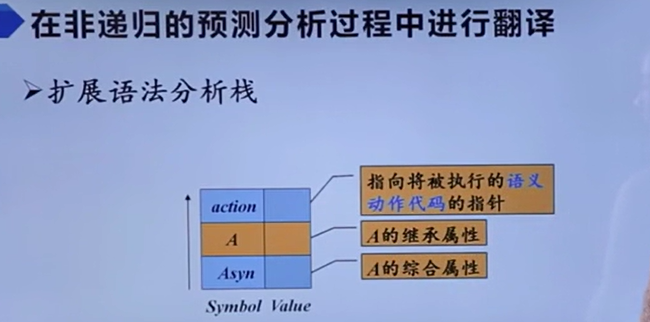
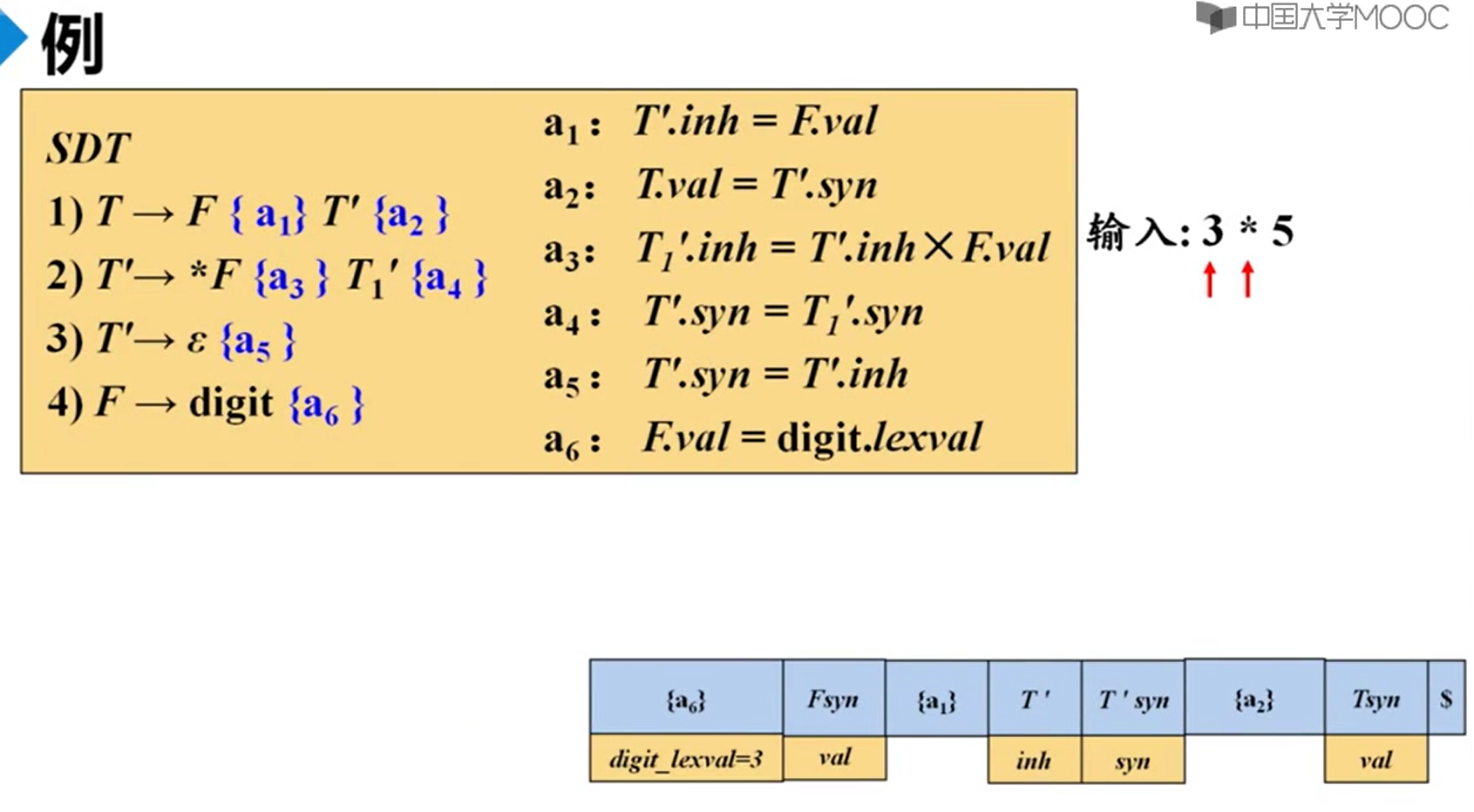
这个是自顶向下的语法分析,本来只用一个栈就行了,现在需要进行扩展。T的综合属性存放在它的右边,继承属性存放在它的平行位置。
当属性值还没计算完时,不能出栈;当综合记录出栈时,它要将属性值借由语义动作复制给特定属性。

然后语义动作也得一起进栈。

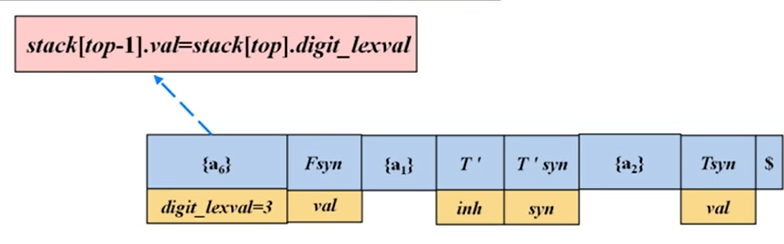
digit是终结符,只有词法分析器提供值
此时,digit跟一个语义动作关联,所以我们需要把它的值复制给它关联的这个语义动作{a6},然后才能出栈。
关联的另一个实例:
此时由于T’.inh还要被a3用到,所以我们就得在T’出栈前把它的这个inh值复制给a3。

当遇到语义动作之后,就执行动作,并且出栈语义动作。
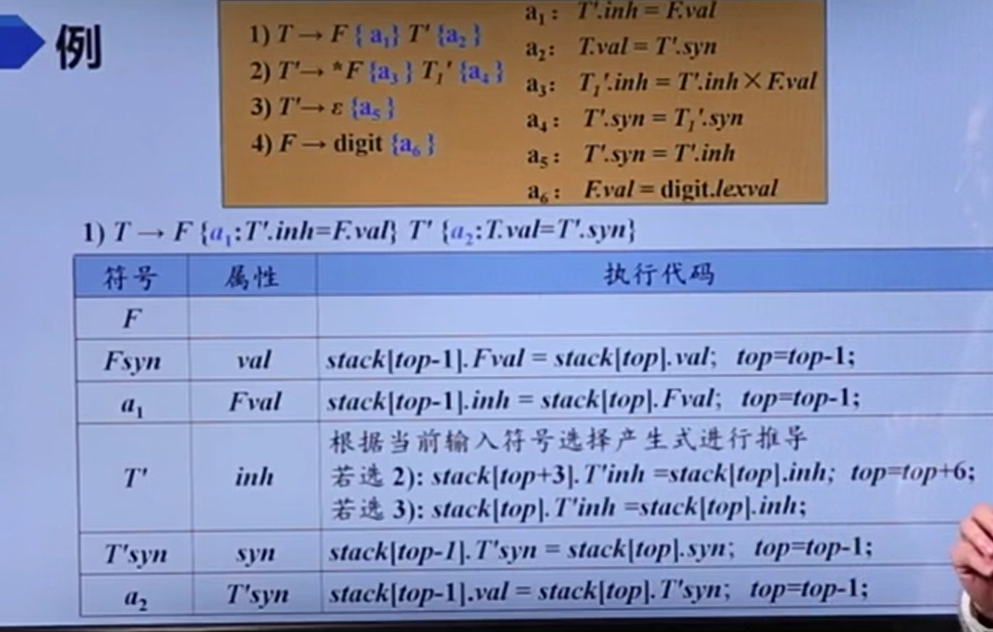
它这意思应该是遇到每个产生式的每个符号要执行什么动作都是确定的,所以代码实现是可能的。
可以看到:
- 语义动作代码就是执行
- 综合属性代码就是赋给关联语义动作
- 非终结符就是选一个它作为左部的产生式,然后看看要不要用到它自身的属性对右部子属性进行复制(体现了继承属性)
递归的预测分析

666666666
感觉这个值得深思,但反正现在的我思不出啥了。。。


LR分析


相当于把L-SDD转化为了个S-SDD。具体是这样,把原式子右边的变量替换为marker的继承属性,结果替换为marker的综合属性。那么新符号继承属性怎么算啊。。。不用担心,因为观察可知要使用的这两个非终结符一定已经在栈中了。
具体分析也看视频就好了。
第六章 中间代码生成
中间代码的形式

逆波兰(后缀)

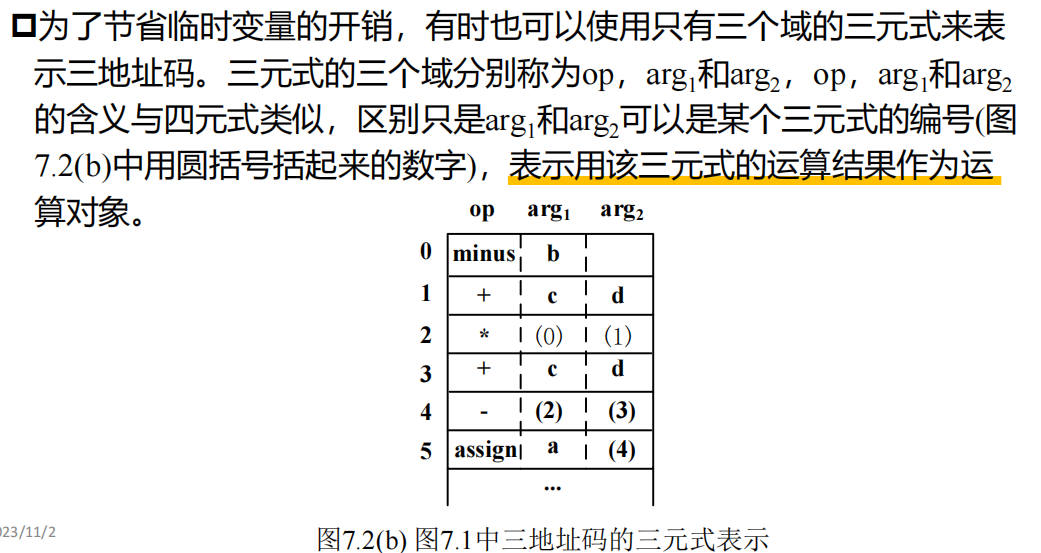
三地址码




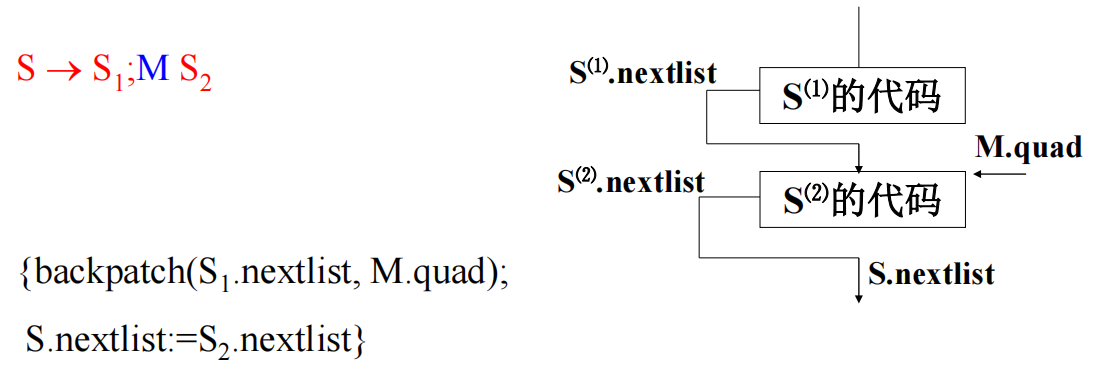
false list就是if失败后的那个goto序号,true list是成功的那个goto序号,s.nextline是整个if的下一条指令

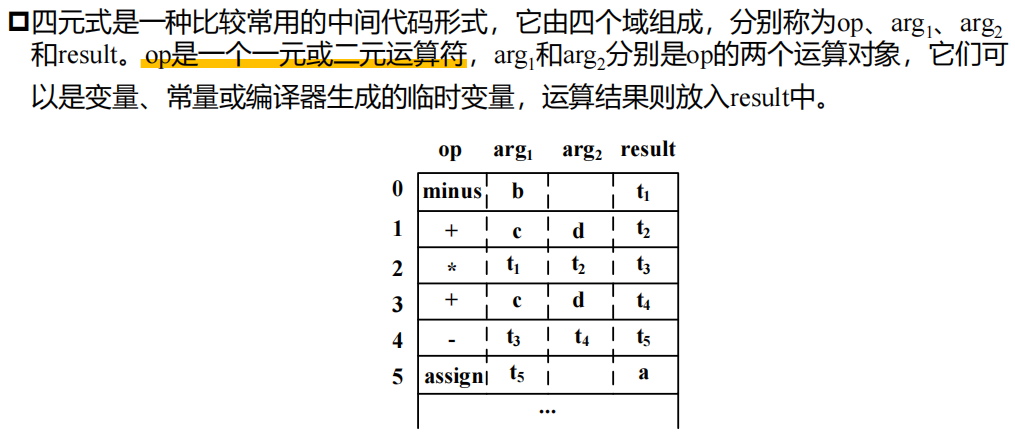
四元式

增量生成
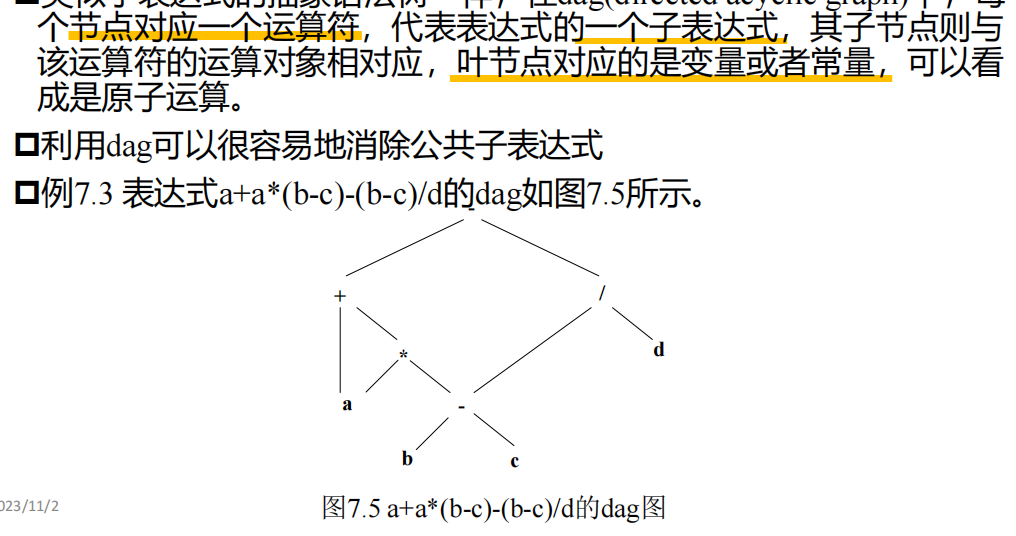
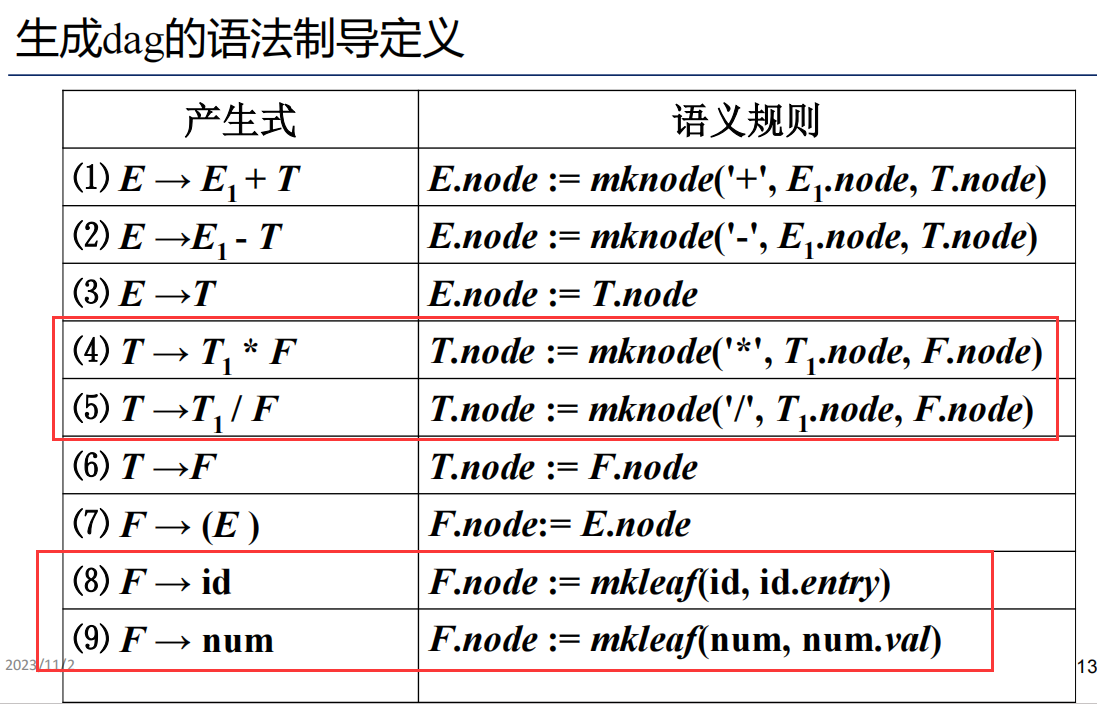
DAG图
声明语句
类型表达式

一般声明
非嵌套



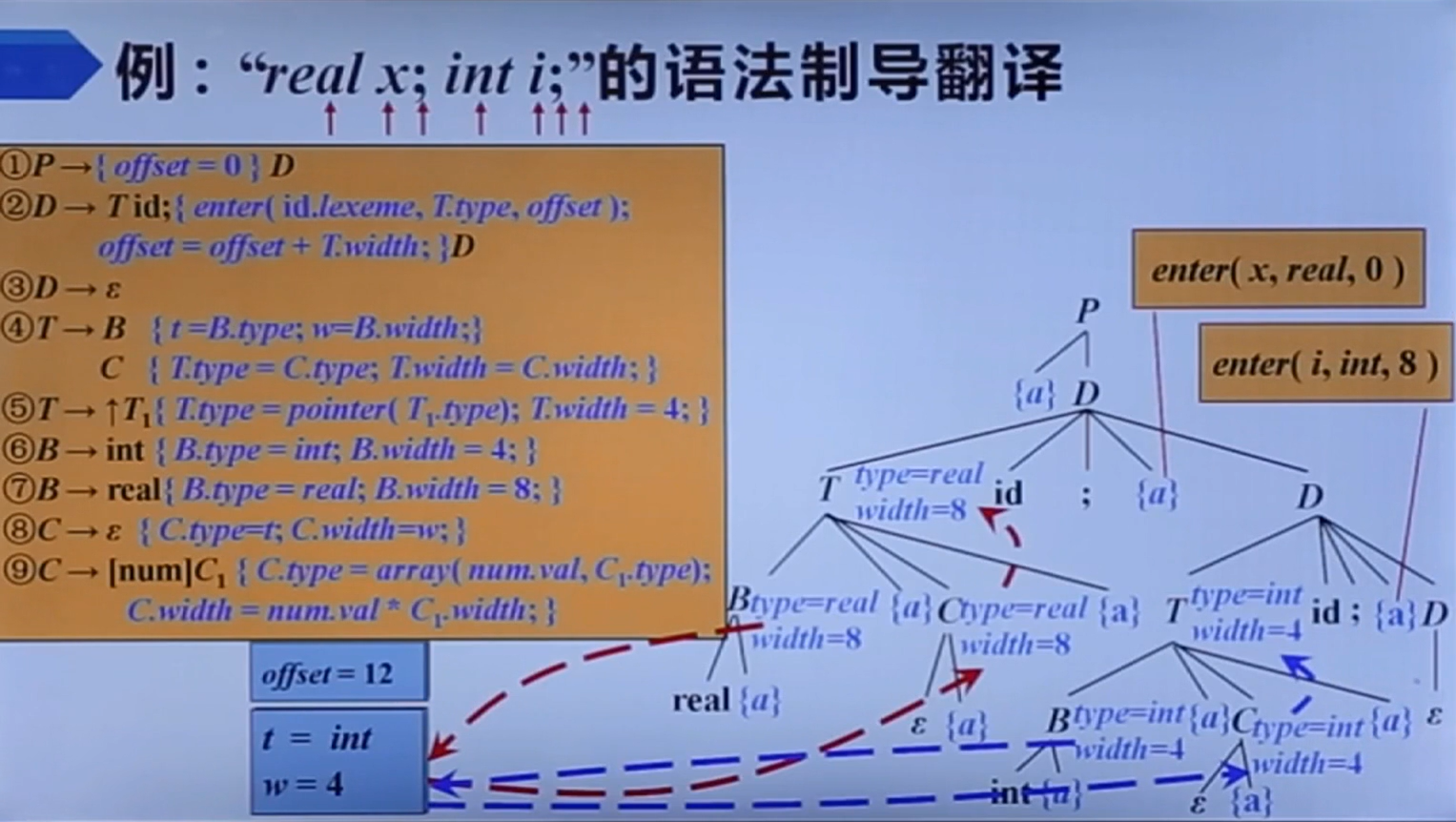
嵌套


它这个相当于是把符号表和offset都整成了一个栈,毕竟确实过程调用就是得用栈结构的

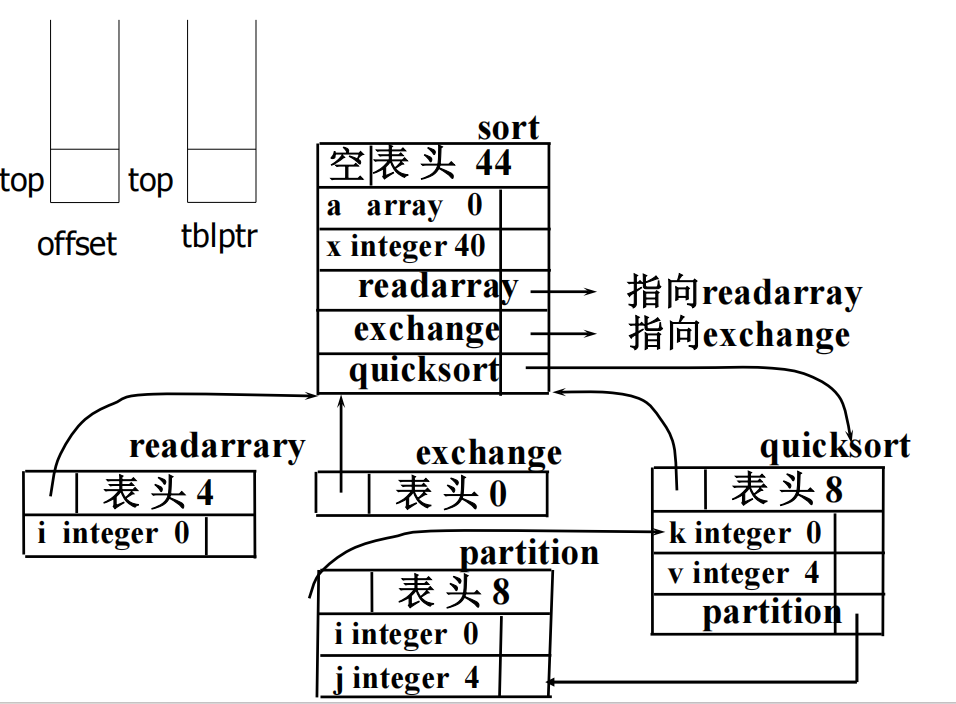
记录


之后用到该记录类型,就指向记录符号表即可。

简单赋值语句
定义
这个就不用填符号表了,所以helper function都是用来产生中间代码的

addr属性需要从符号表中获取

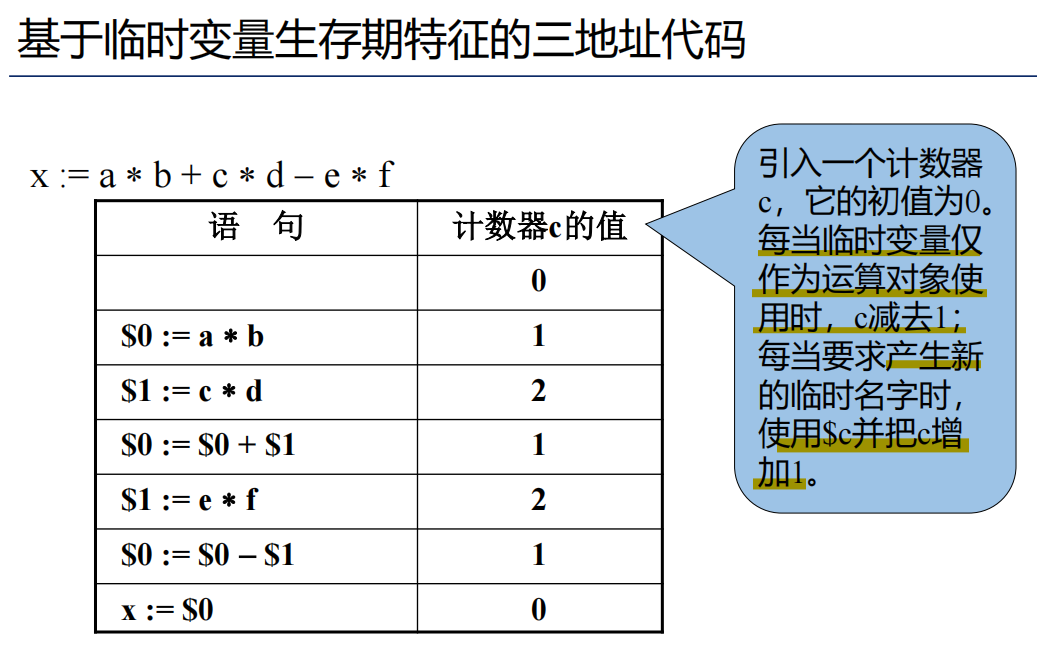
临时变量处理
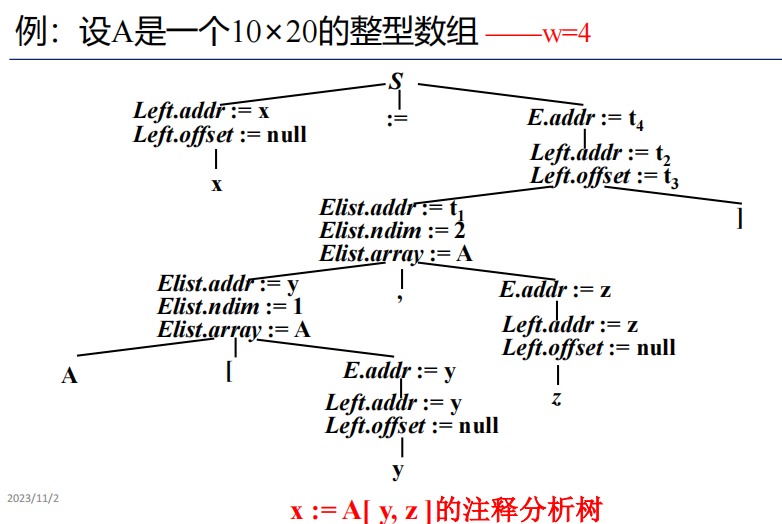
数组元素寻址





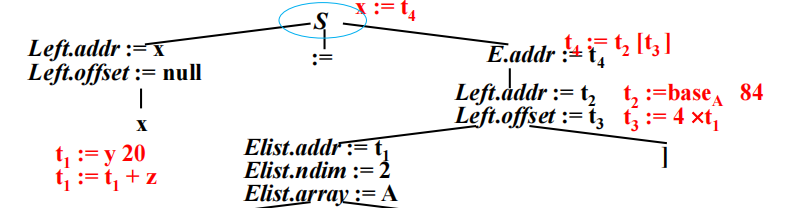
类型检查
规则
看个乐吧

类型转换


在语义动作中实现
控制流语句
简单控制流


反正意思就是用S.next这个继承属性来表示S.code执行完后的下一个三地址码地址。
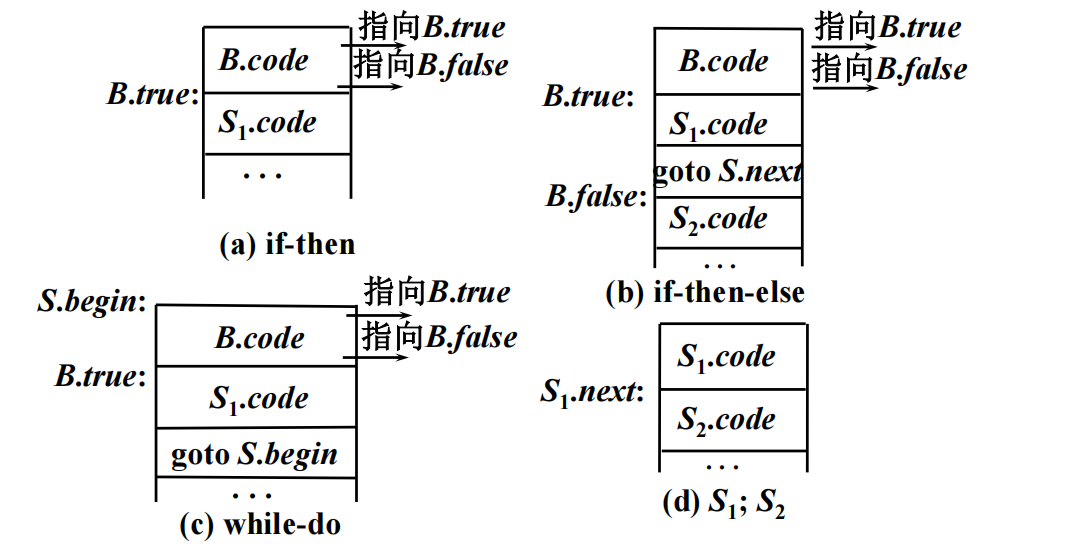
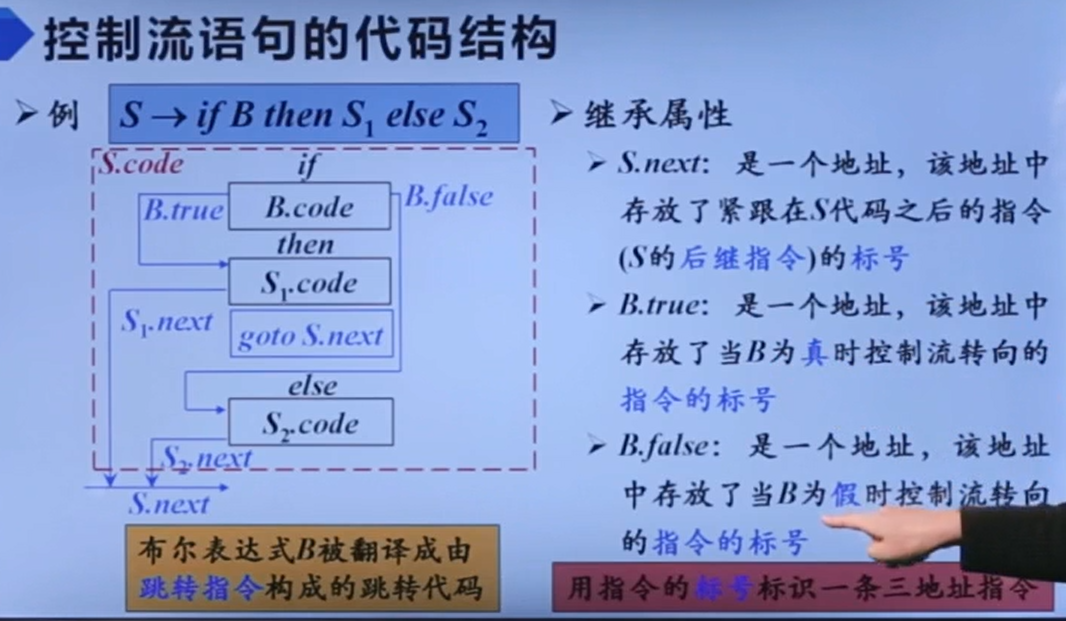
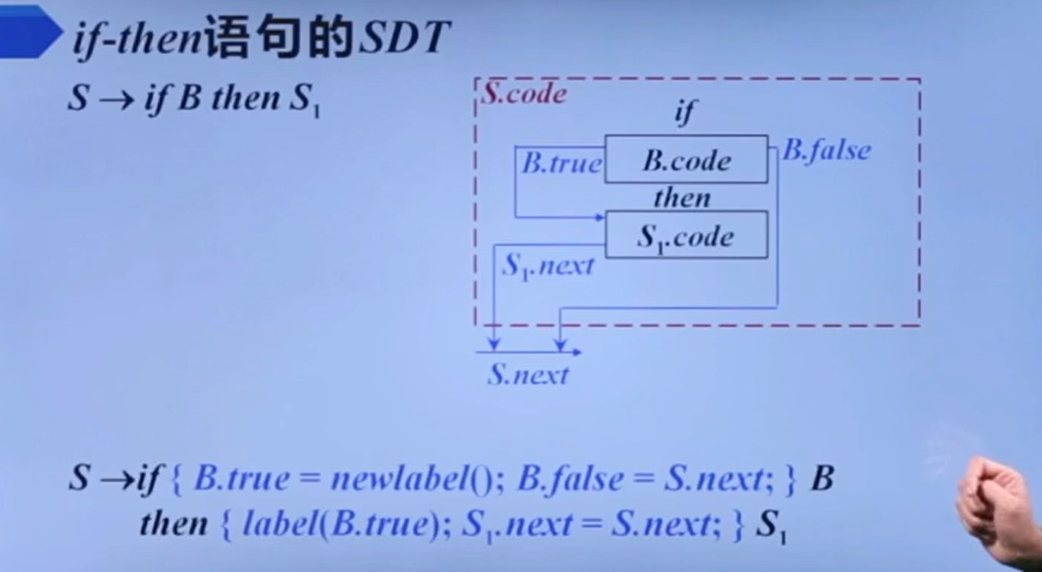
if-then

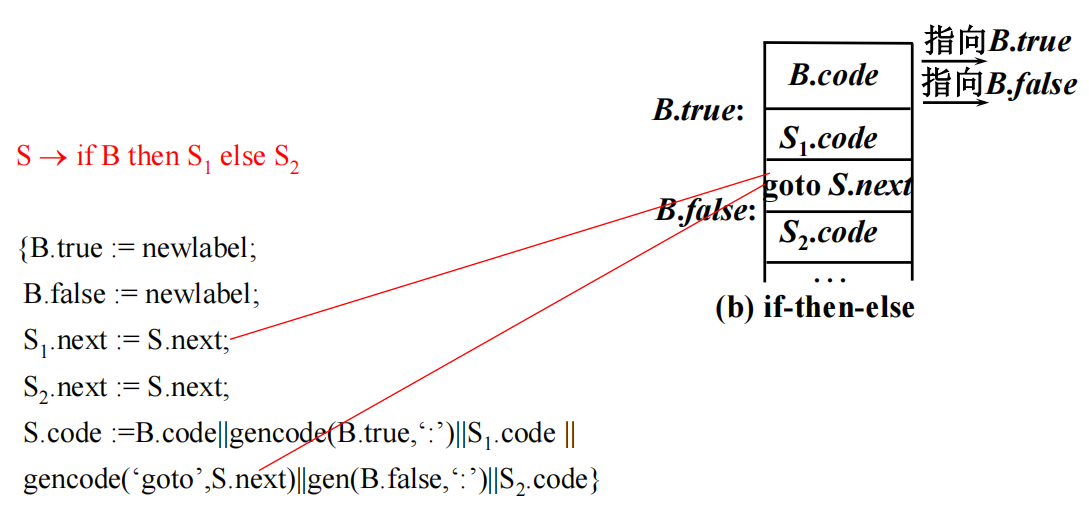
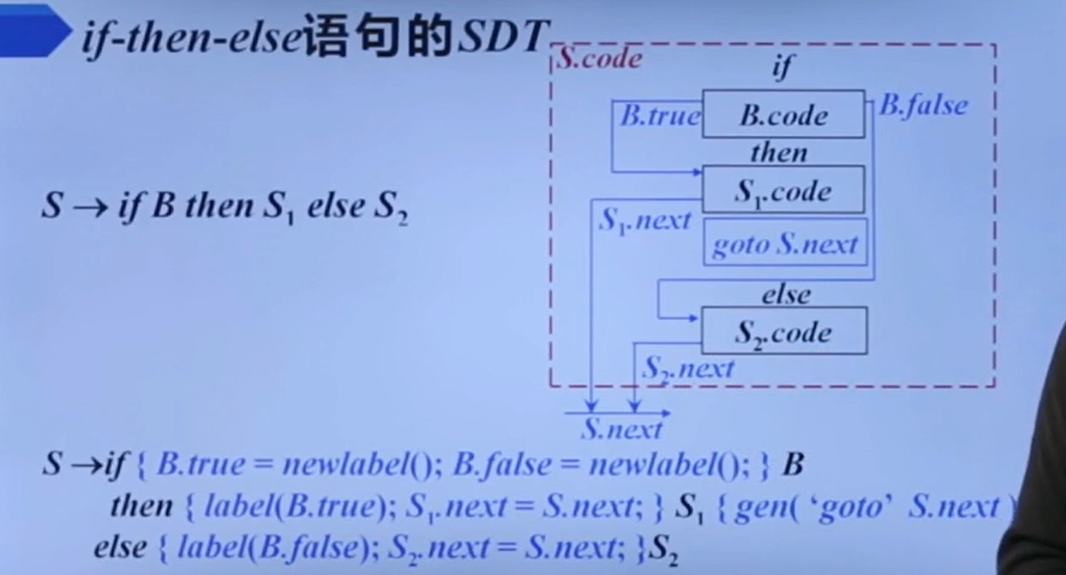
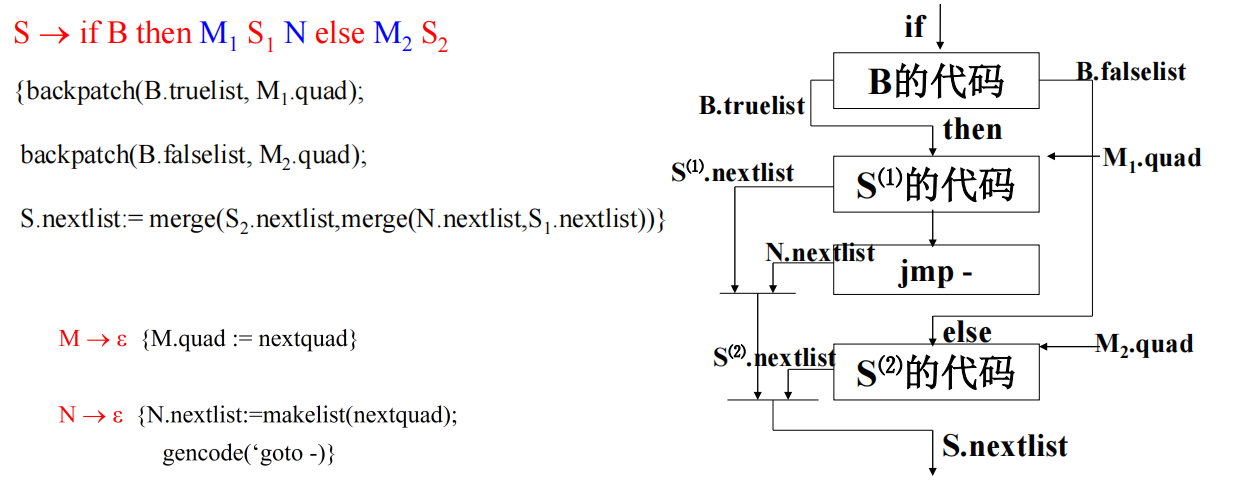
if-then-else
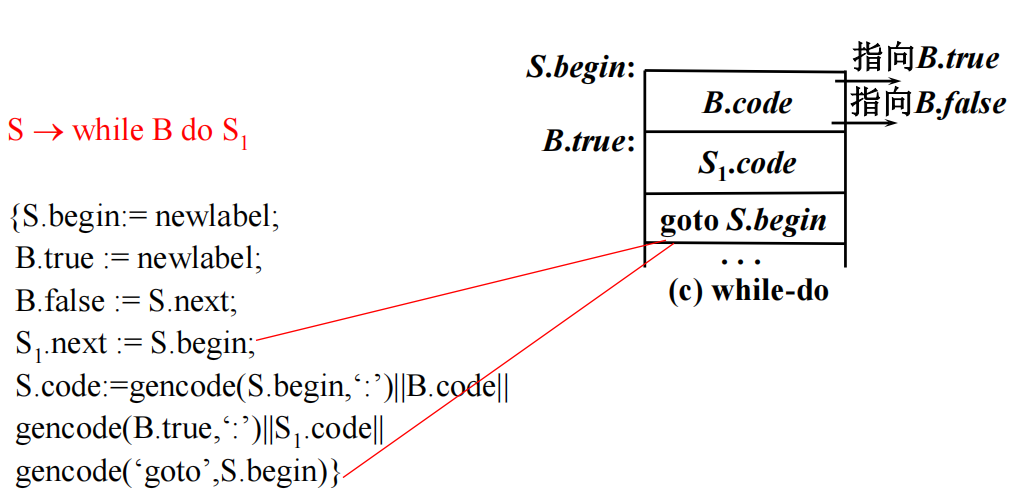
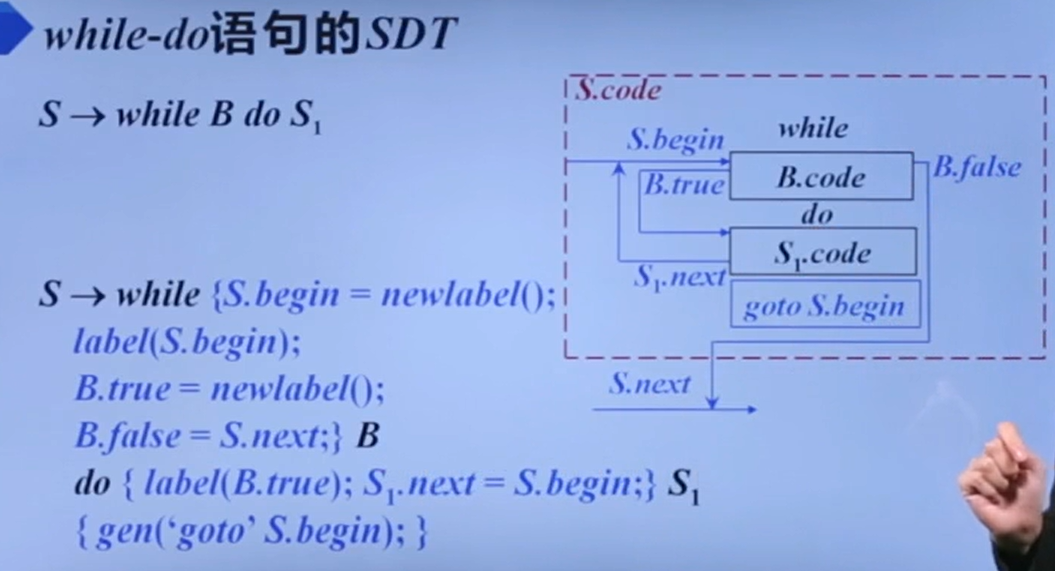
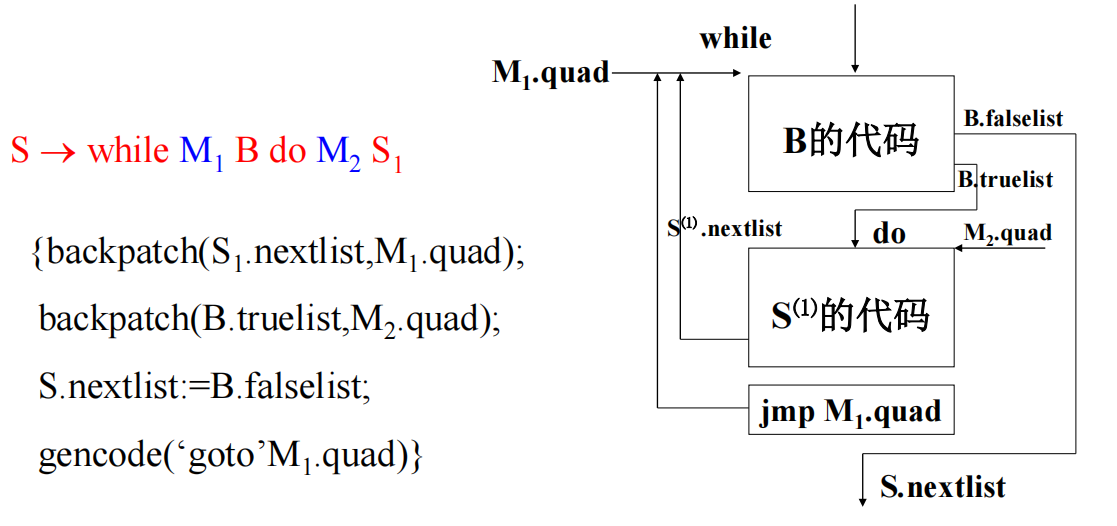
while-do
;
其实不大懂这什么玩意
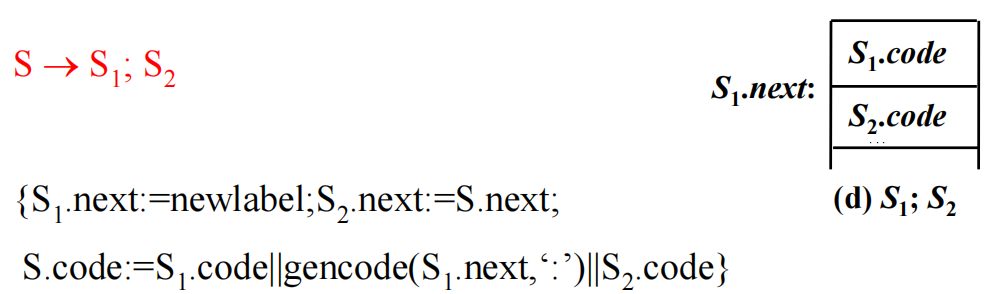

抽象
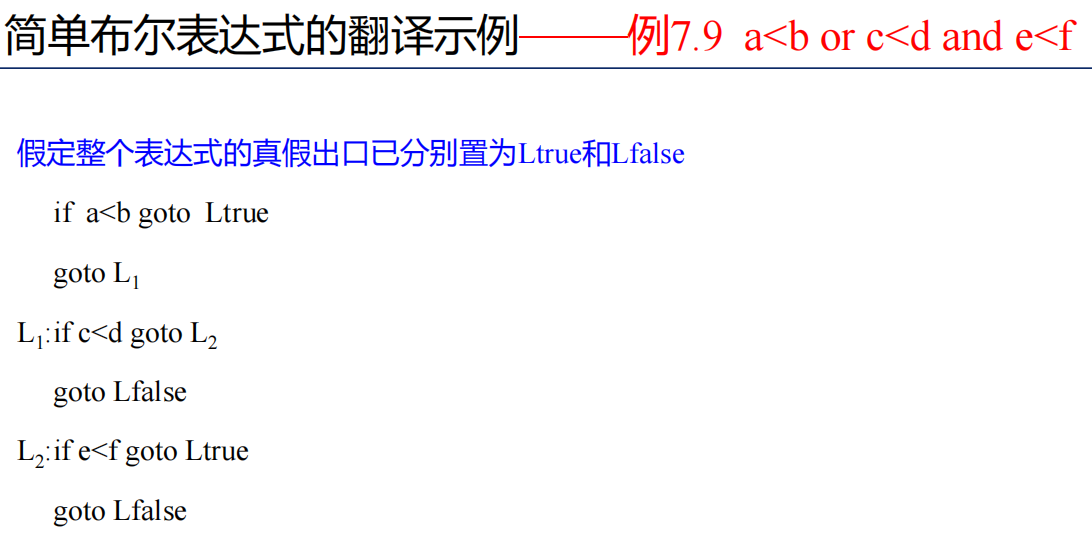
布尔表达式
布尔表达式翻译
基本


数值表示



控制流表示



混合模式布尔表达式



回填
基本



这两个都是综合属性
相当于是一个waiting list
布尔表达式的回填
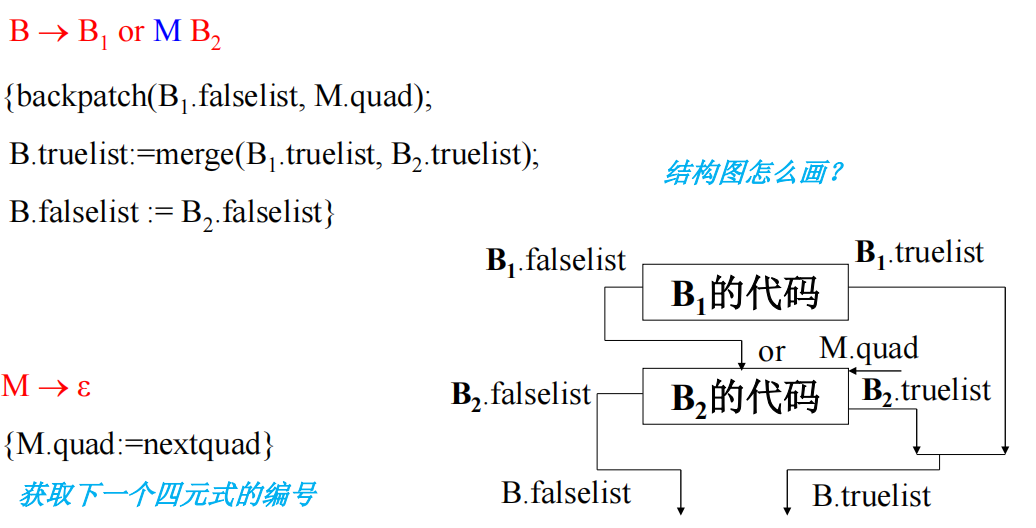
可以理解为,B这个表达式可以分为两种情况,两种情况有一个为真B就为真。那么,B的真回填list相当于也被分为了两种情况,所以要求B的就是把它们合起来。
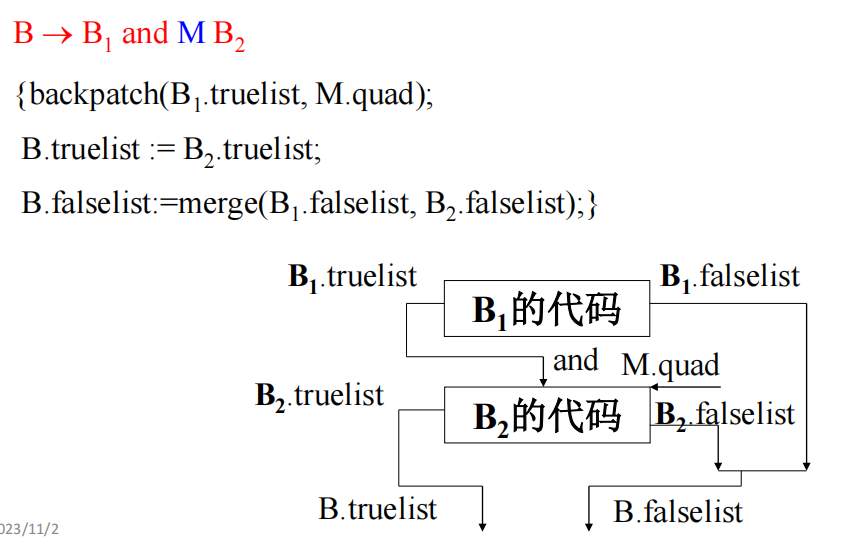



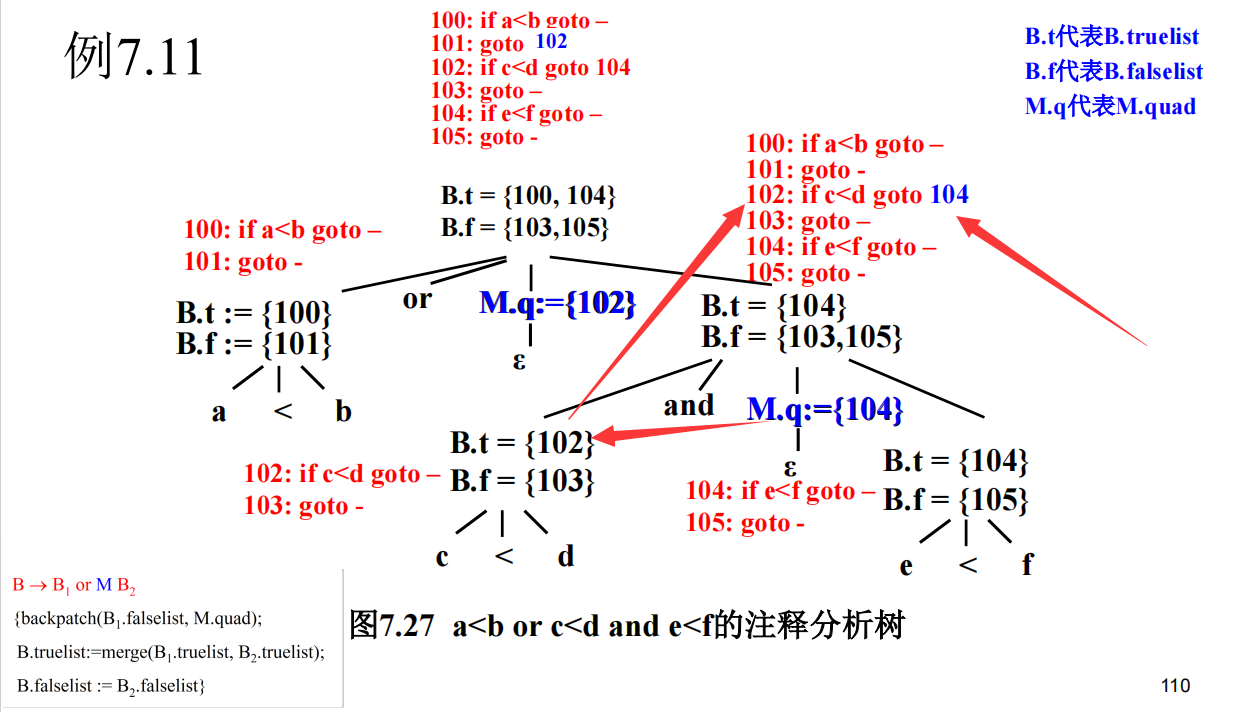
原来回填是这个意思
控制流结构的回填
nextline是一个综合属性
if-then
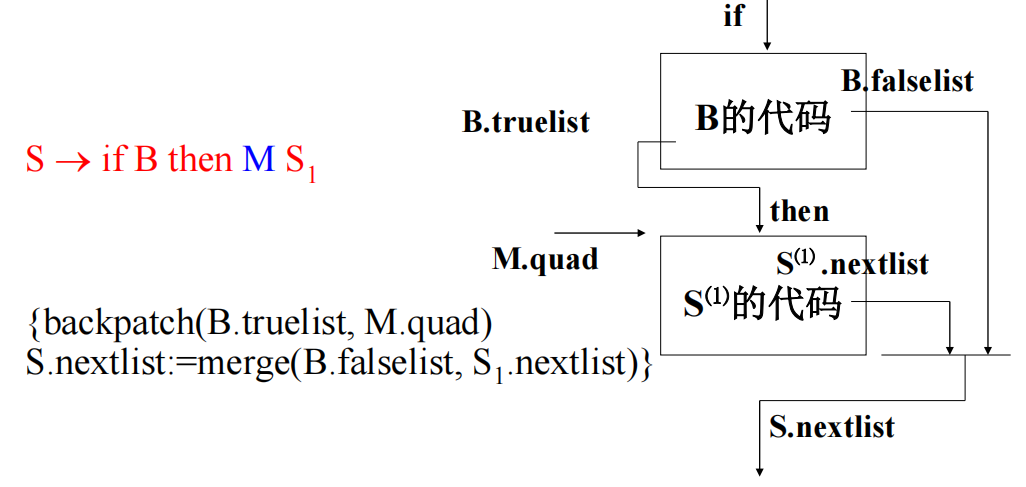
if-then-else
while-do
sequence
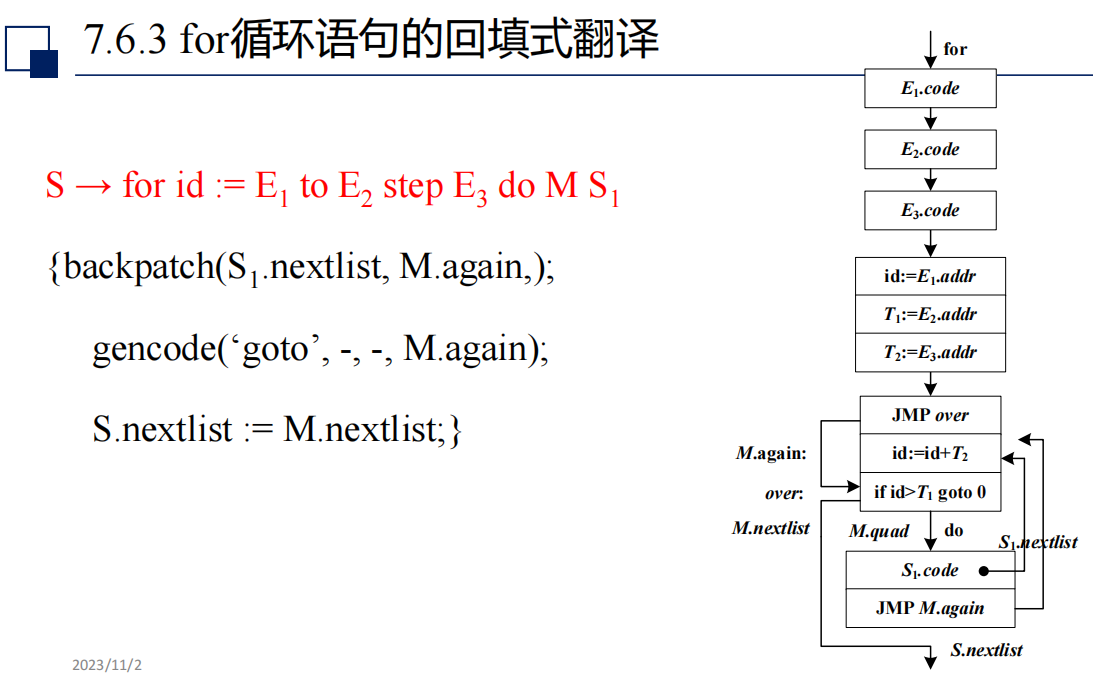
for

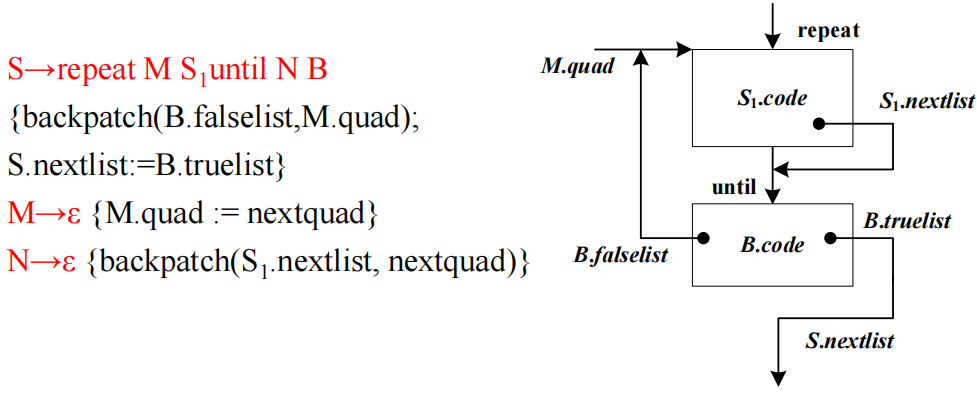
repeat
switch-case
TODO 这笔之后再看。。。。

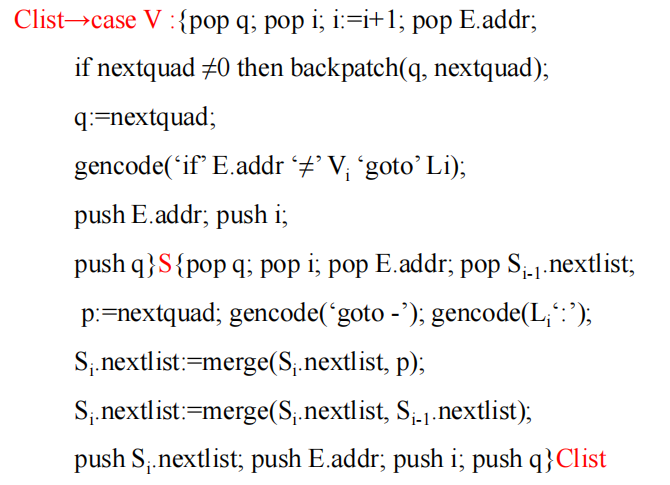

过程调用



输入输出语句
TODO


题型1 四元序列

第七章 运行存储分配
概念
存储组织
活动记录


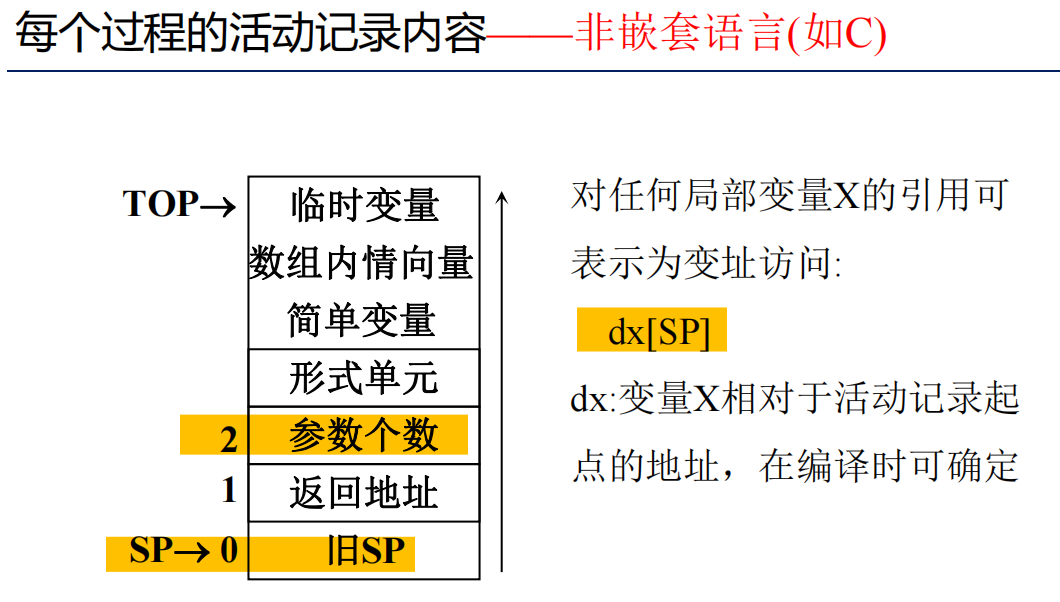

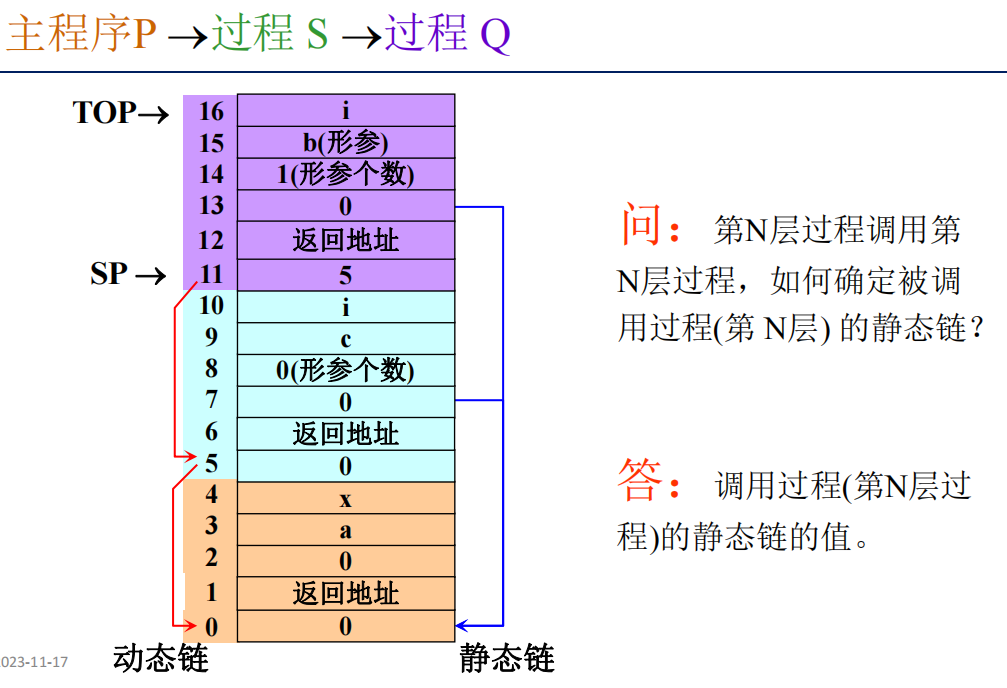
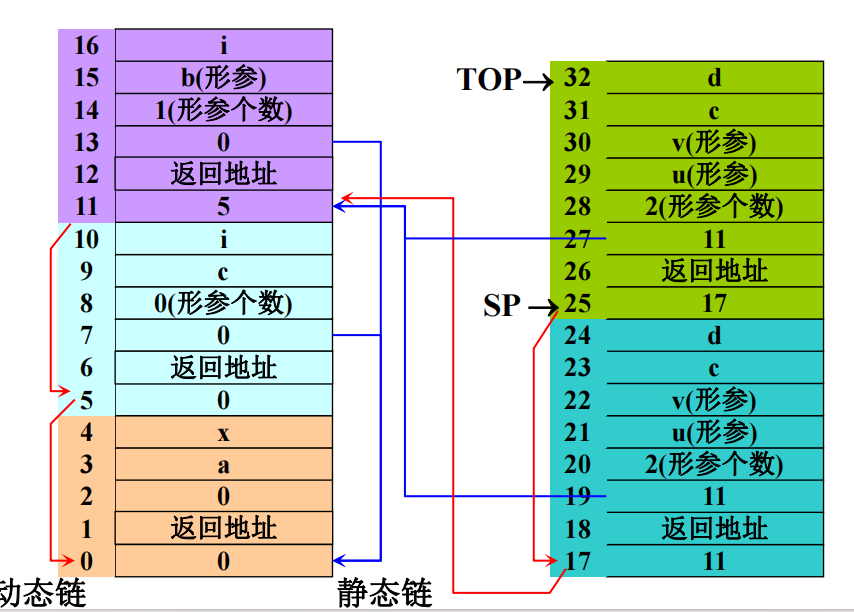
静态/动态链

静态链也被称作访问链,用于访问存放于其他活动记录中的非局部数据。
动态链也被称作控制链,用于指向调用者的活动记录。
内存对齐

作用域


传参方式
传值

传地址

传值结果

反正意思就是既要得到原来的A,又要修改A
传名


静态存储分配


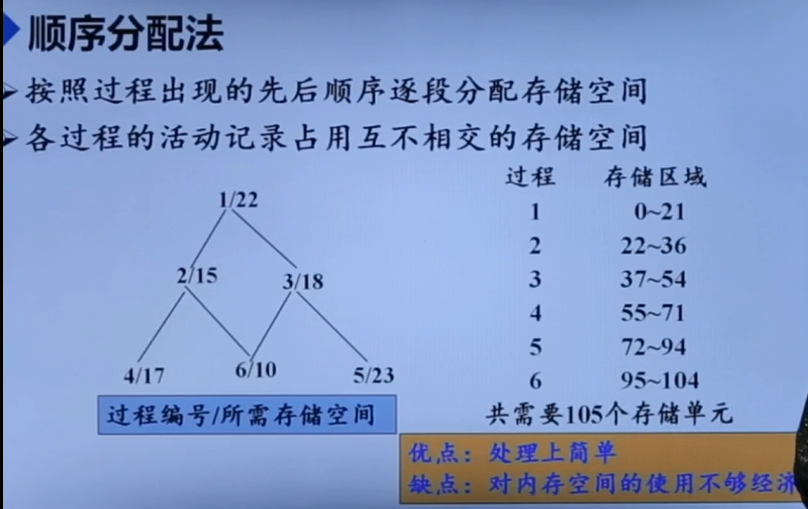
顺序分配法
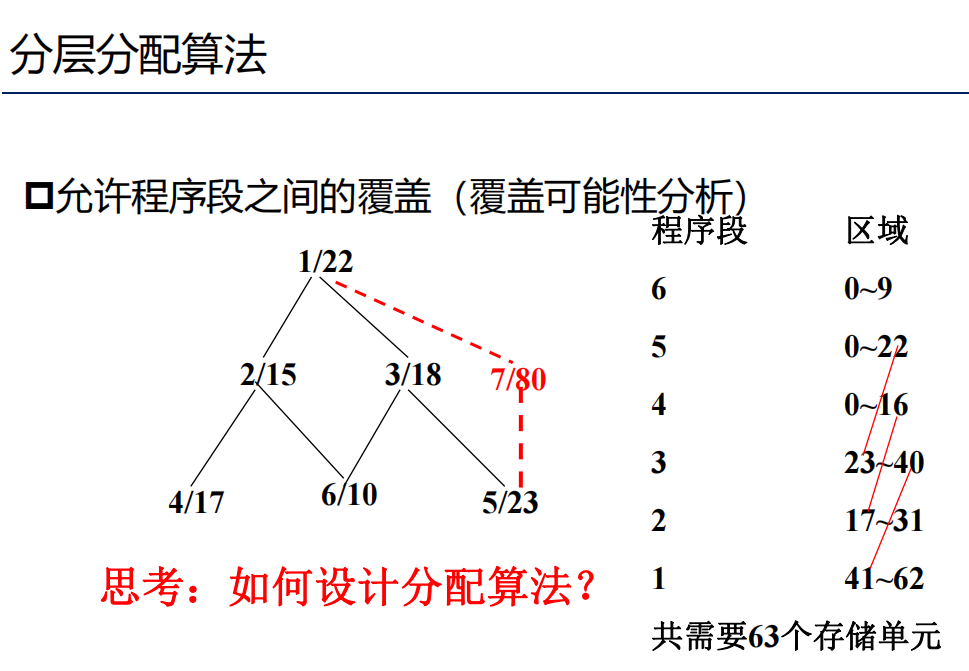
层次分配法
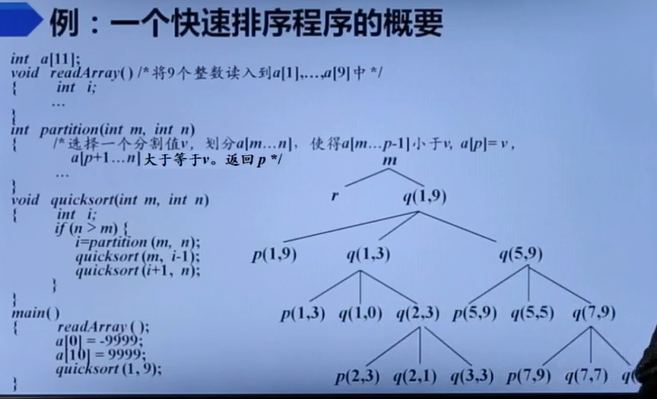
栈式存储分配
概念


也就是说左边及其所有子树全调完了,才能调下一个兄弟的。

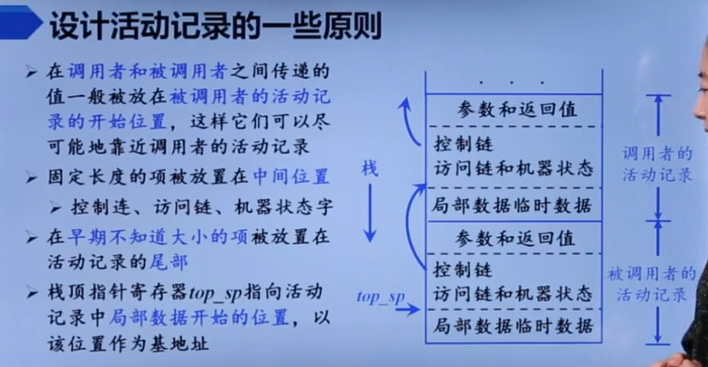
左边这几点设计规则都十分reasonable,很值得注意。
不过我其实挺好奇,参数存在那么后面该咋访问。。。。看xv6,似乎是fp指向前面,sp才指向local,也即用了两个栈指针。
这个控制链也是约定俗成的,具体可以想起来xv6也是类似结构:
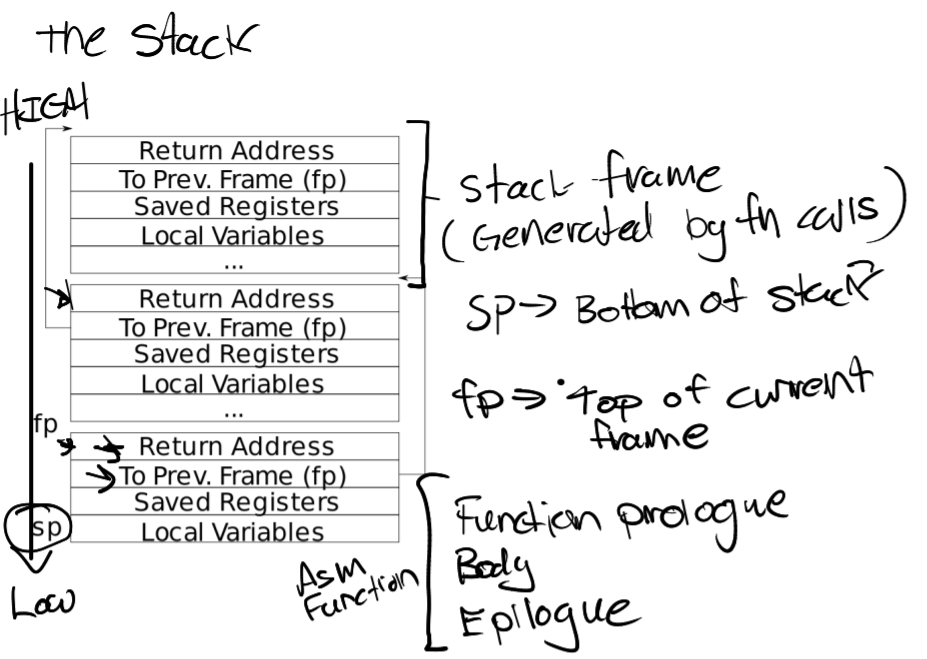
当函数返回的时候,就会进行恢复现场,从而出栈一直到ra,很合理。
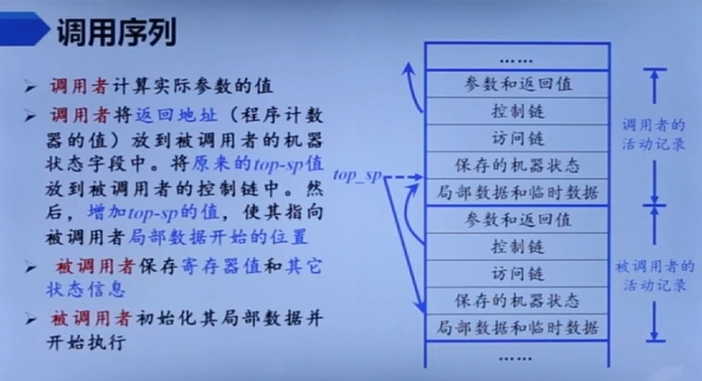
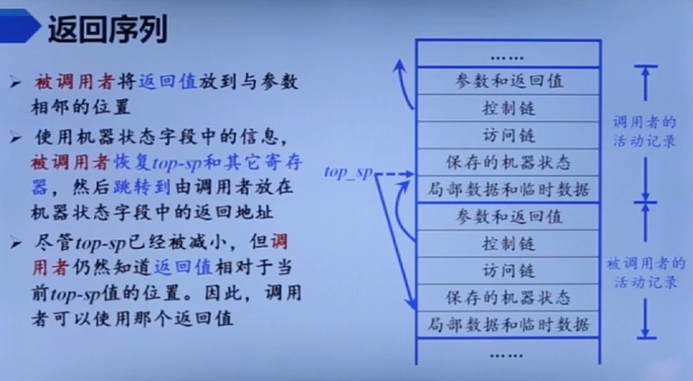
调用/返回序列
是什么

调用序列应该就是设置参数、填写栈帧一类,返回序列就是恢复现场
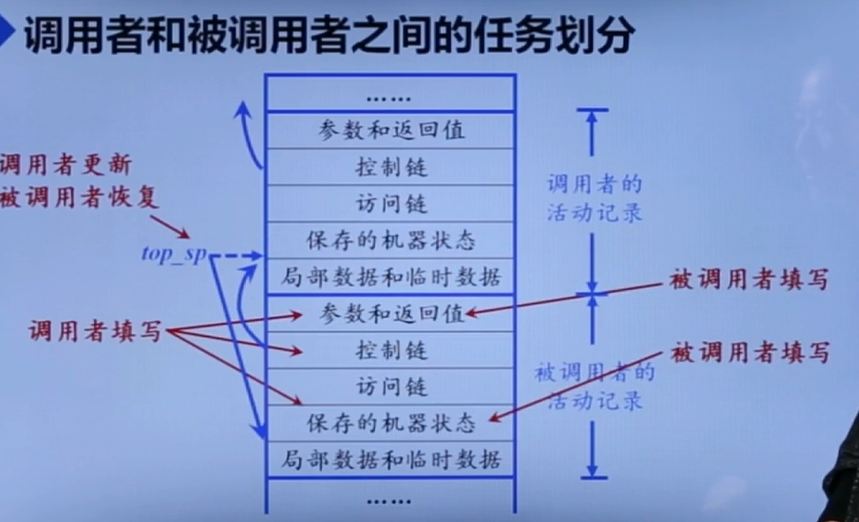


生成代码

调用序列
传变量、改变meta data、改变top和sp指针

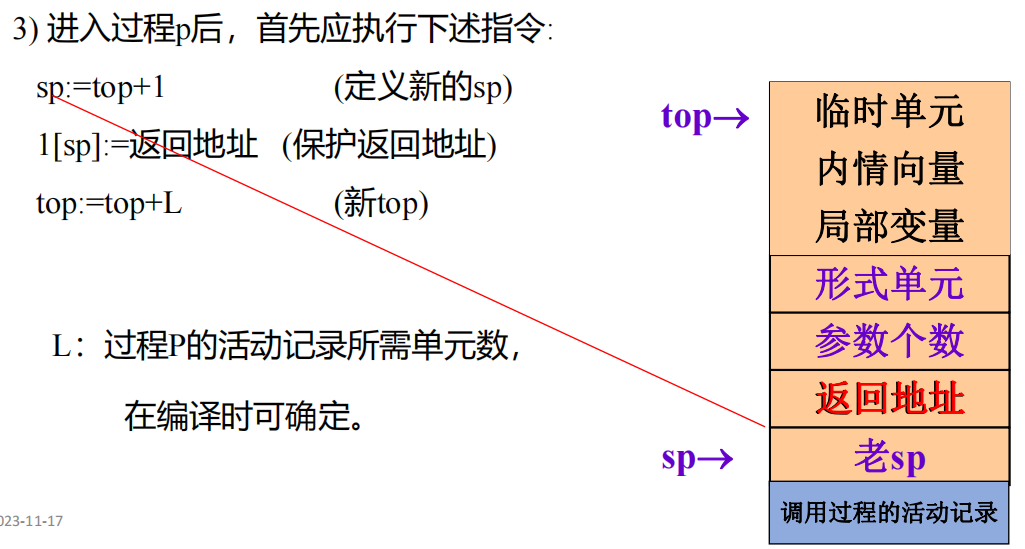
返回序列
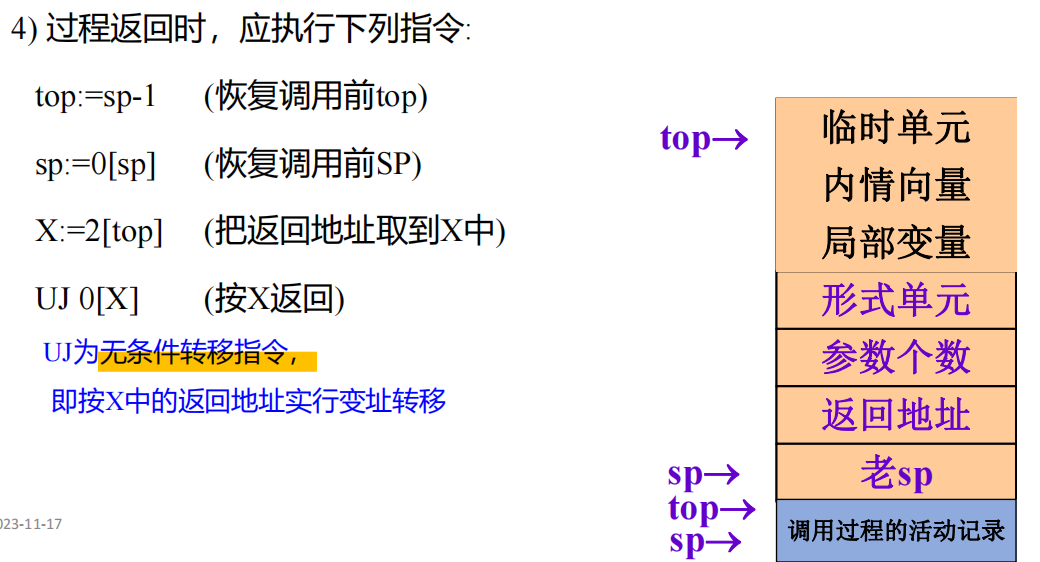
变长数据

这段解释了下为什么不用堆,说得很好
缺点

第二点,比如malloc后不free
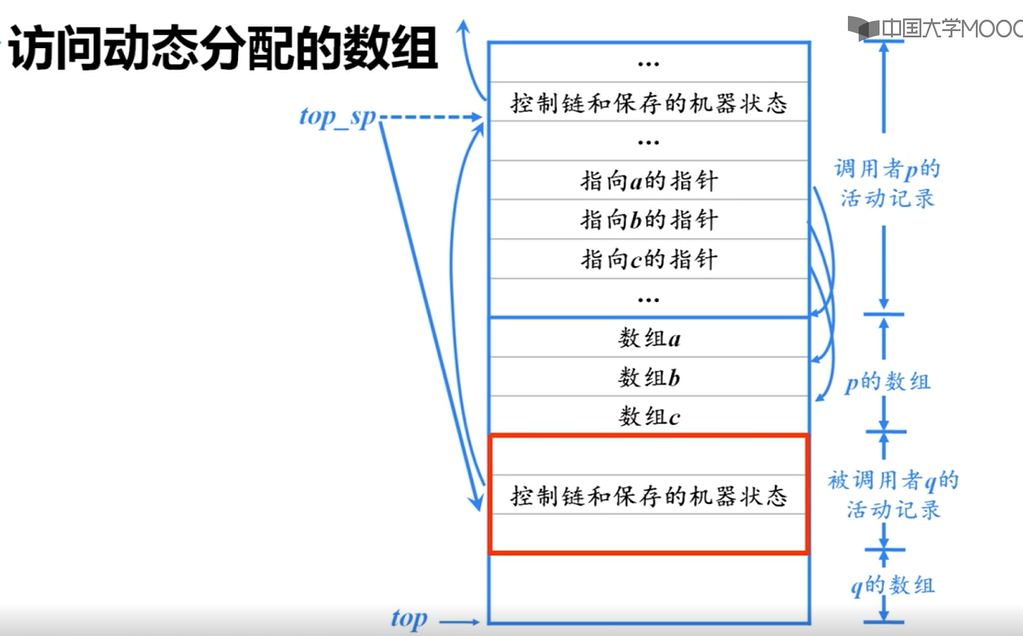
栈中非局部数据的访问

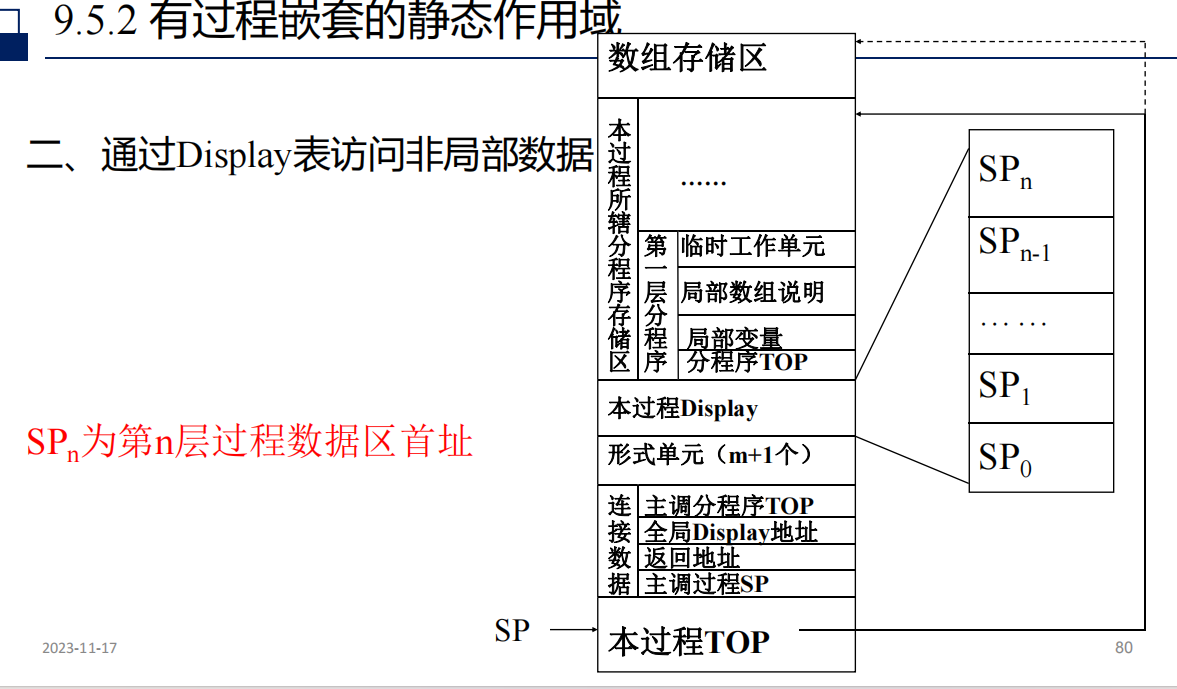
有过程嵌套

静态作用域
访问链

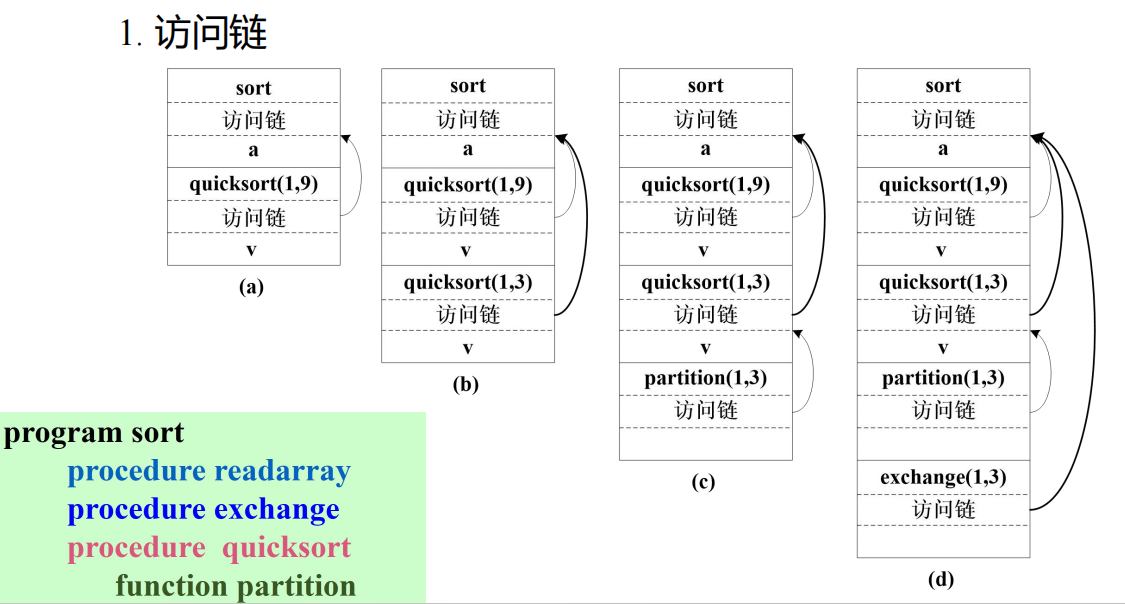


建立访问链



过程参数的访问链

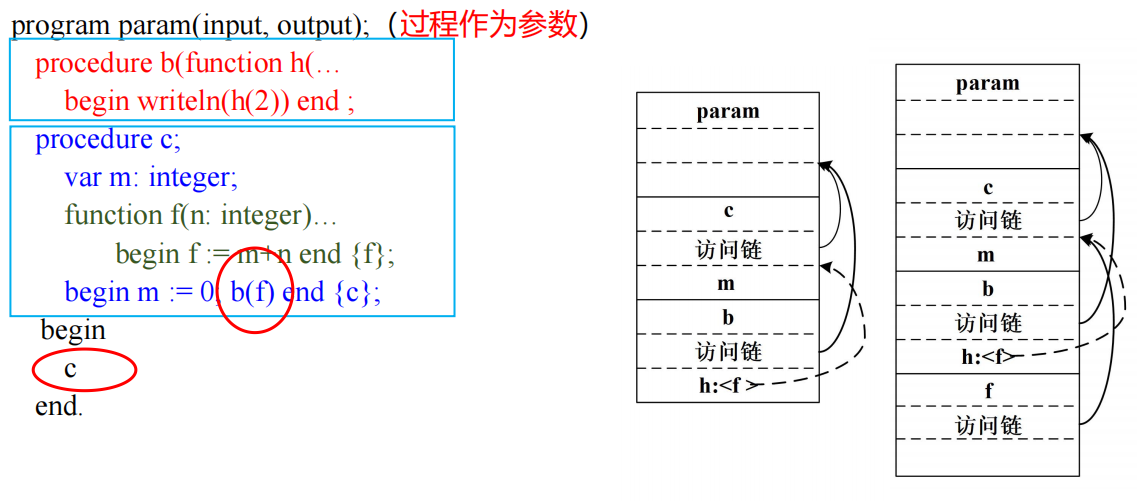
Display表
通俗解释
每一个嵌套深度的分配一个Display位
S嵌套深度1,所以占据d[1];Y和X嵌套深度2,所以占据d[2];Z嵌套深度3,所以占据d[3]。
然后,一开始遇到个S,d1指向S;然后调用Y,d2指向Y;然后Y中调用X,就修改d2指向X;然后调用Z,就修改d3指向Z。
总之显示栈就是这个变换指针的过程。
至于控制栈,要打印这里面的display表,就是看层数。如果d1那就打印当前层,d2就打印的12层,d3就123层【不是纯显示栈,是它自己内部的未变换指针的结果】



结果:SXZ
定义



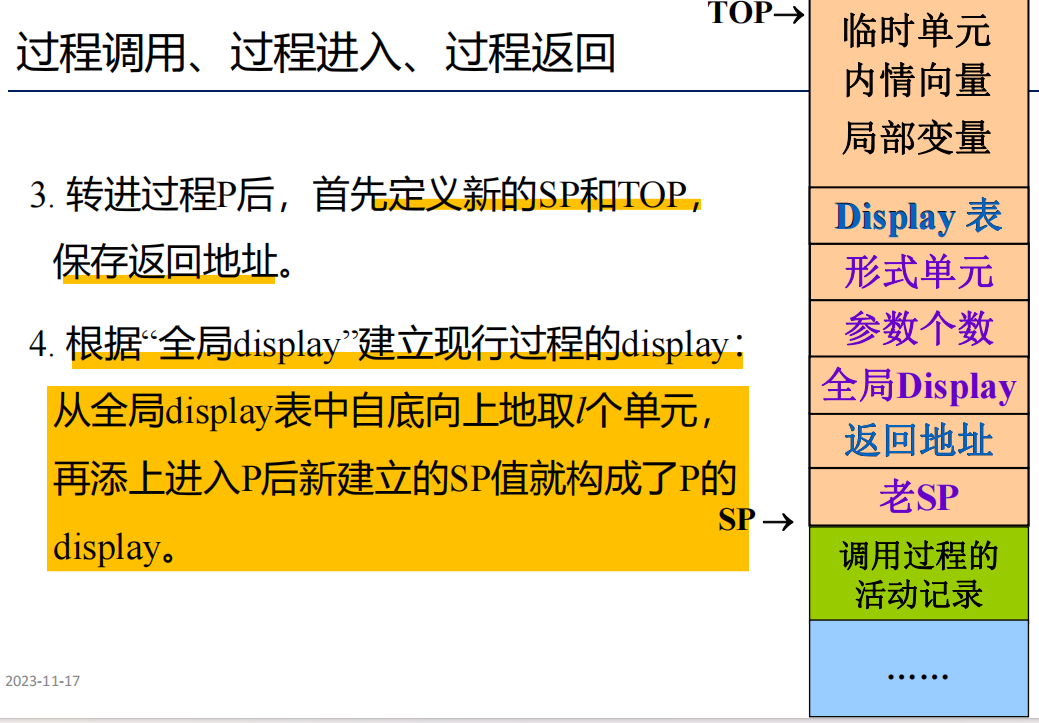
访问流程
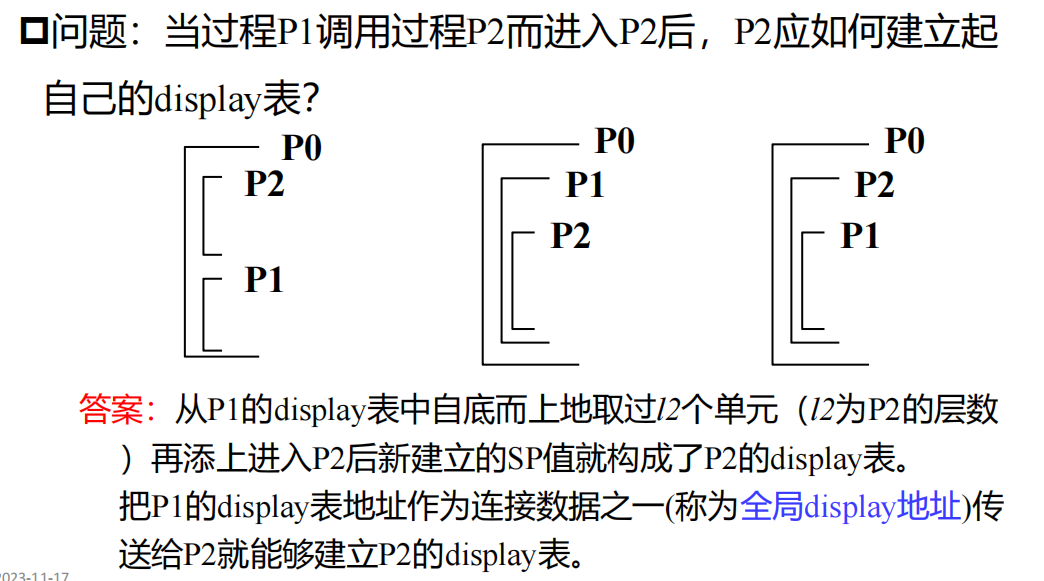

生成代码



动态作用域
静态作用域是空间上就近原则,动态是时间上。


无过程嵌套


也就是说这时候非局部的一定是全局变量或者静态的局部变量。
堆管理

内存管理器
局部性

堆分配算法
人工回收请求
符号表
如题

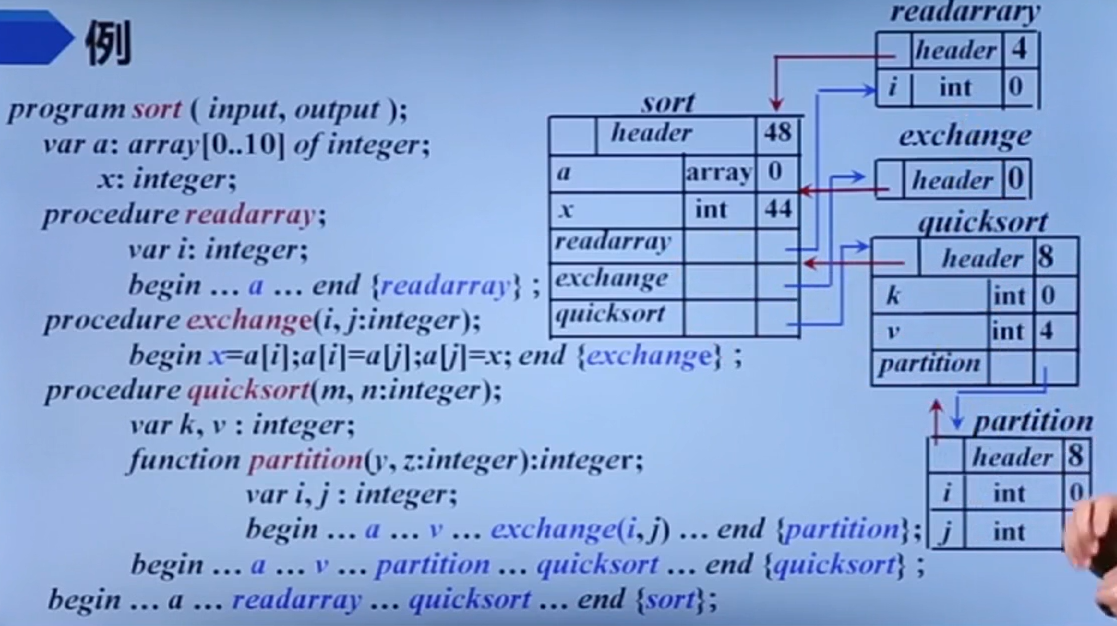
如果是支持过程声明嵌套,顺着符号表就可以找到其父过程/子过程的数据。
符号表也可以用于构造访问链,因为过程名也是一种符号。

符号表的建立

第九章 代码生成
概述

目标代码形式

指令选择

寄存器分配

计算顺序选择

不讨论这个
目标语言
定义

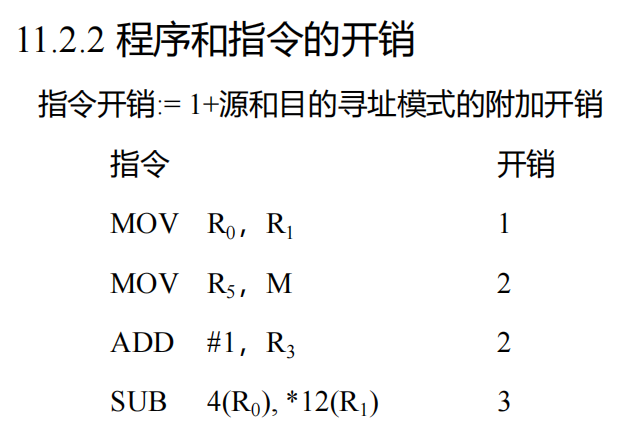
指令开销




运行时刻地址
简单的代码生成器
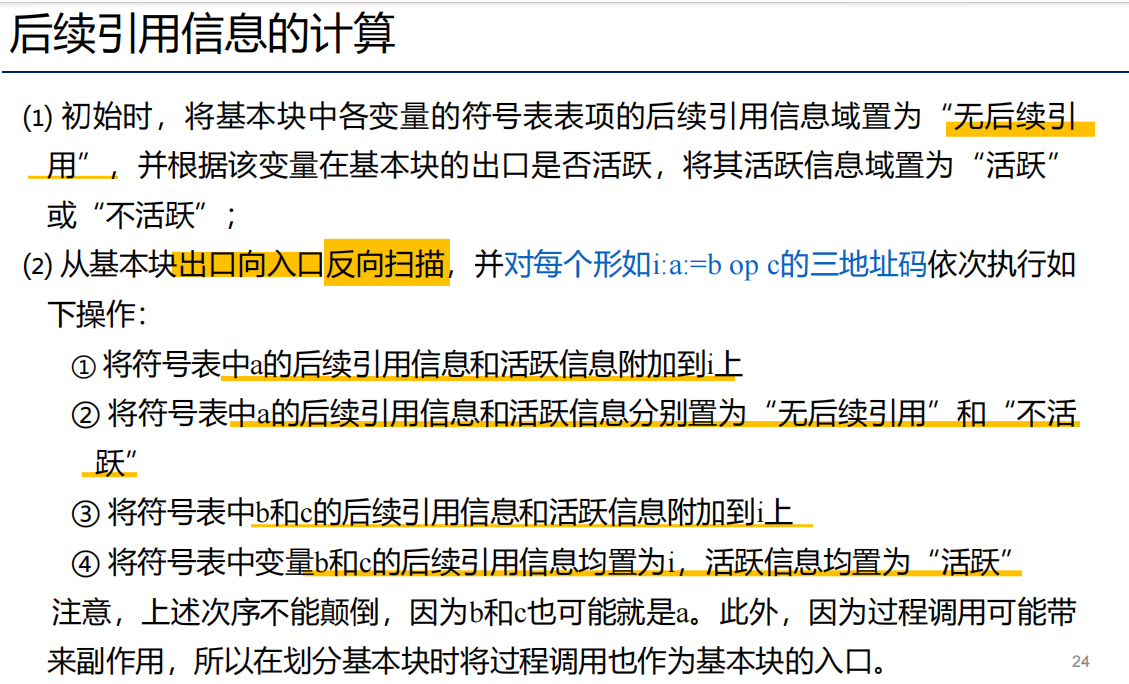
后续引用信息

寄存器与地址描述符

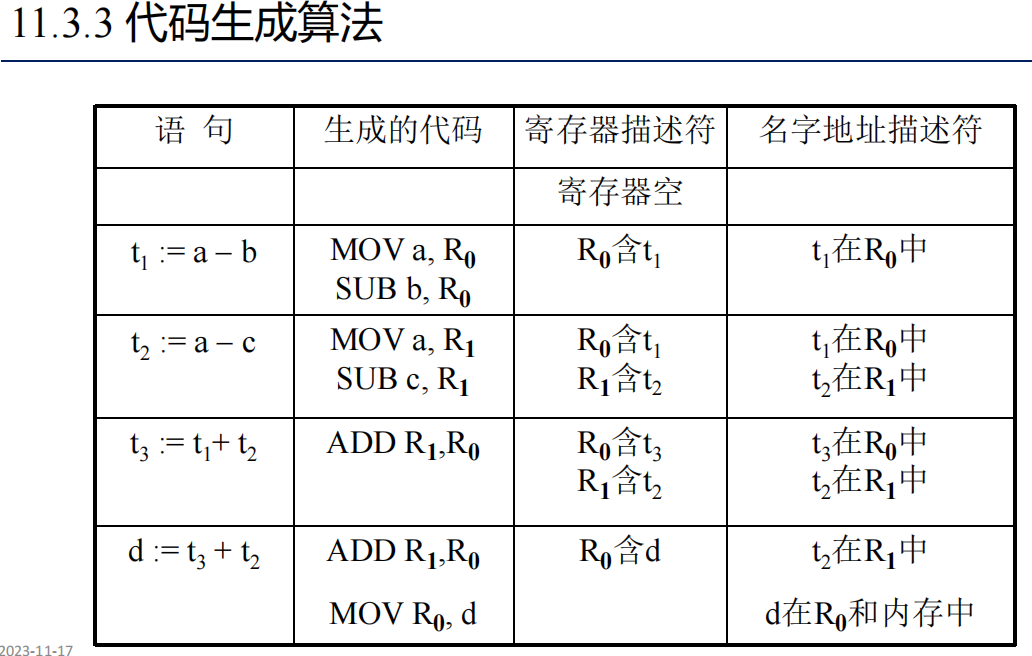
代码生成算法




窥孔优化

冗余指令消除

不可达代码消除

强度削弱

特殊机器指令使用

寄存器分配指派

全局寄存器分配

引用计数


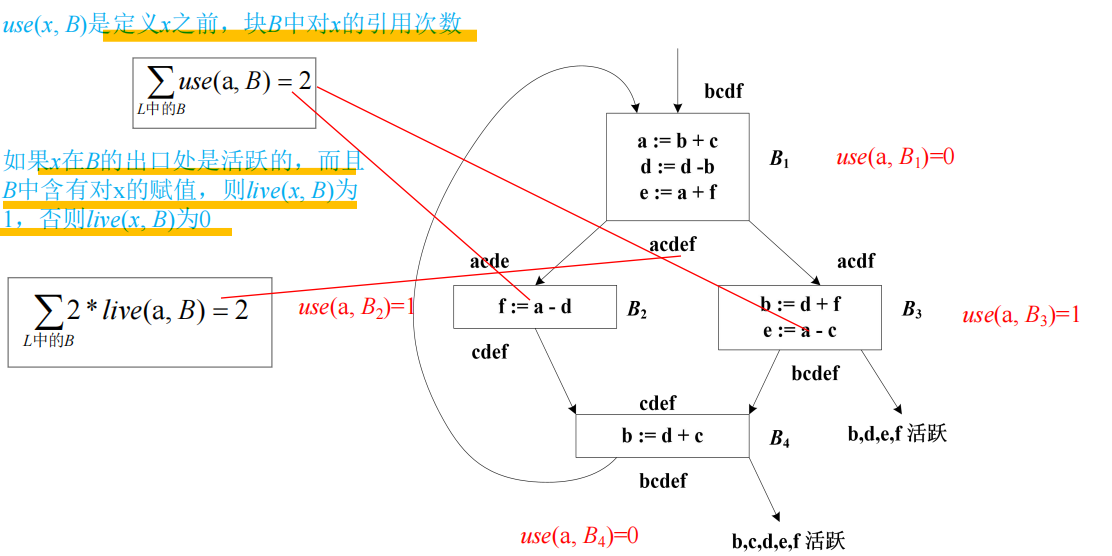

所以这东西是用来决策寄存器分配的
外层循环的寄存器指派


反正类似保护现场恢复现场
拓展阅读
AC自动机
在思考自动机和动态规划的关系时,胡乱搜索看到了AC自动机,于是来了解了一下。
考虑一个问题:给出若干个模式串,如何构建一个DFA,接受所有以任一模式串结尾(称为与该模式串匹配)的文本串?
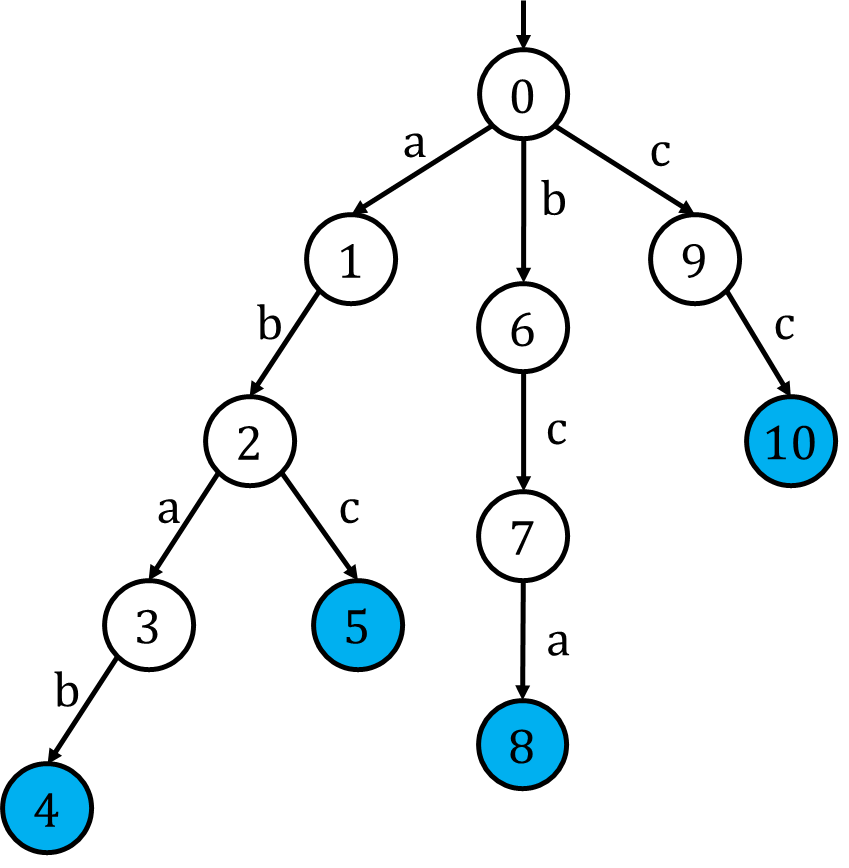
可以先思考一个更简单的问题:如何构建接受所有模式串的DFA?很明显,**字典树**就可以看做符合要求的自动机。例如,有模式串
"abab"、"abc"、"bca"、"cc",我们把它们插入字典树,可以得到:
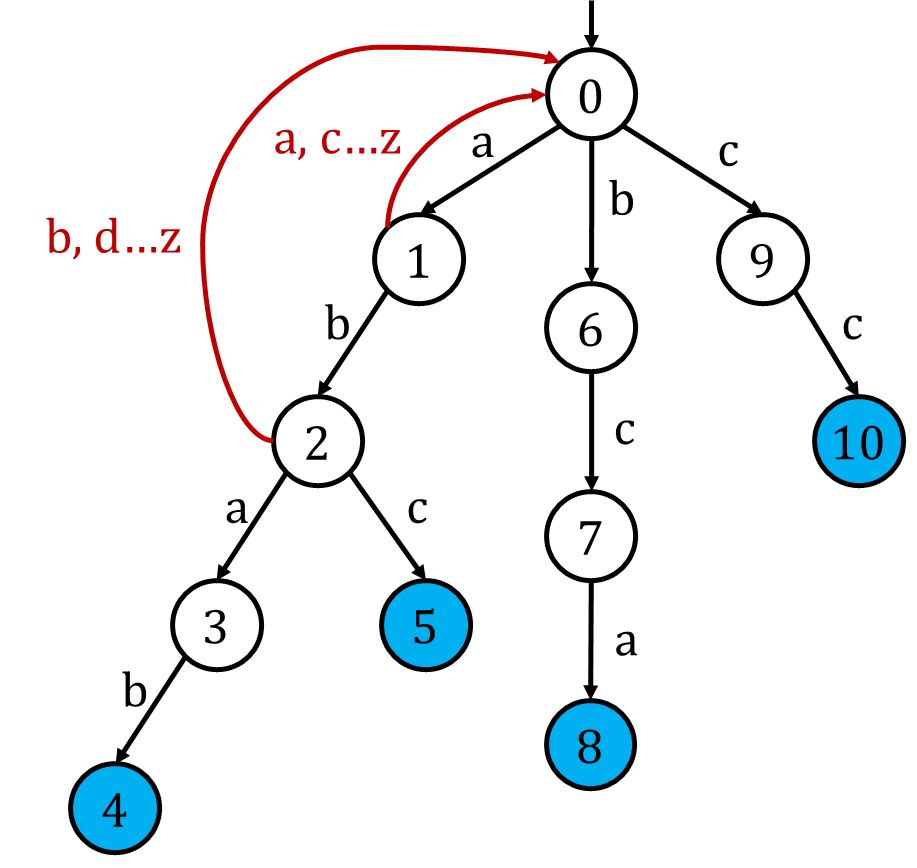
为了使它不仅接受模式串,还接受以模式串结尾的文本串,一个看起来挺正确的改动是,使每个状态接受所有原先不能接受的字符,转移到初始状态(即根节点)。
但是如果我们尝试
"abca",我们会发现我们的自动机并不能接受它。稍加观察发现,我们在状态5接受a应该跳到状态8才对,而不是初始状态。某种意义上来说,状态7是状态5退而求其次的选择,因为状态7在trie上对应的字符串"bc"是状态5对应的字符串"abc"的后缀。既然状态5原本不能接受"a",我们完全可以退而求其次看看状态7是否可以接受。这看起来很像KMP算法,确实,AC自动机常常被人称作trie上KMP。所以我们给每个状态分配一条fail边,它连向的是该状态对应字符串在trie上存在的最长真后缀所对应的状态。我们令所有状态p接受原来不能接受的字符c,转移到 next(fail(p),c) ,特别地,根节点转移到自己。为什么不需要像KMP算法一样,用一个循环不断进行退而求其次的选择呢?因为如果我们用BFS的方式进行上面的重构,我们可以保证 fail(p) 在p重构前已经重构完成了,类似于动态规划。
这样建fail边和重构完成后得到的自动机称为AC自动机(Aho-Corasick Automation)。
我们发现fail边也形成一棵树,所以其实AC自动机包含两棵树:trie树和fail树。一个重要的性质是,如果当前状态 p 在某个终止状态 s 的fail树的子树上,那么当前文本串就与 s 所对应模式串匹配。
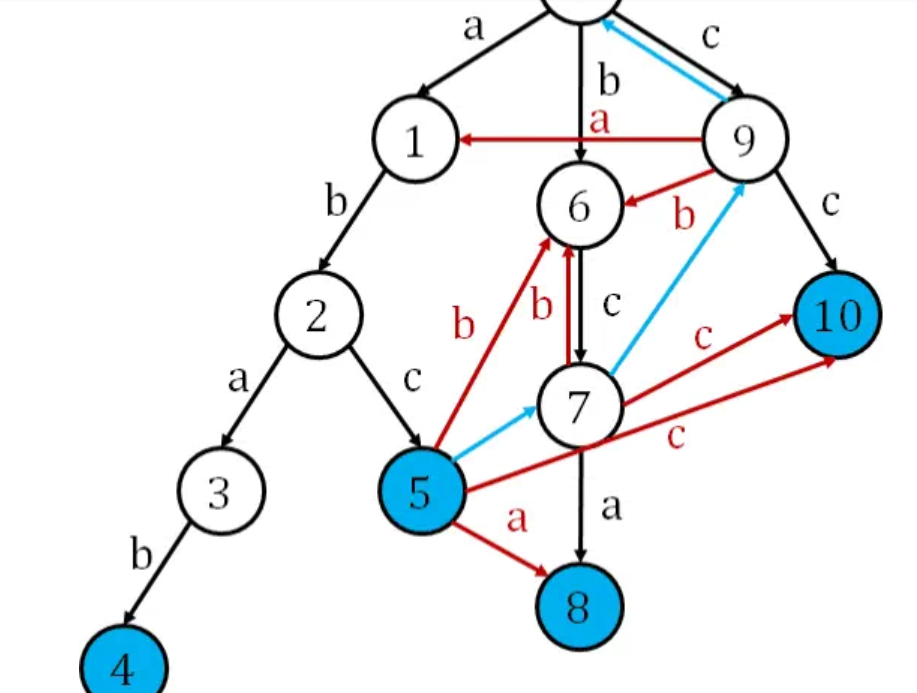
也就是说它的解决方法是加fall边(蓝色)和加新边(红色),