【2025.1.6 report】
OSDI’20: Fast RDMA-based Ordered Key-Value Store using Remote Learned Cache
Xingda Wei, Rong Chen, Haibo Chen
概述:提出了一种混合 learned index 和 B+ tree 索引架构的 RDMA-based ordered kvstore
1. 背景:Learned Index
SIGMOD’18: The Case for Learned Index Structures 开山之作
提出:可以通过机器学习模型替代范围索引(如B+树)。
为什么可以替代?
索引本身即可视为预测模型。通过索引确定数据位置,可以看做是一个预测过程:key值 → 位置pos
B树:
key👉B树👉叶节点(误差范围),然后再在叶节点中进行精确查找获取位置。
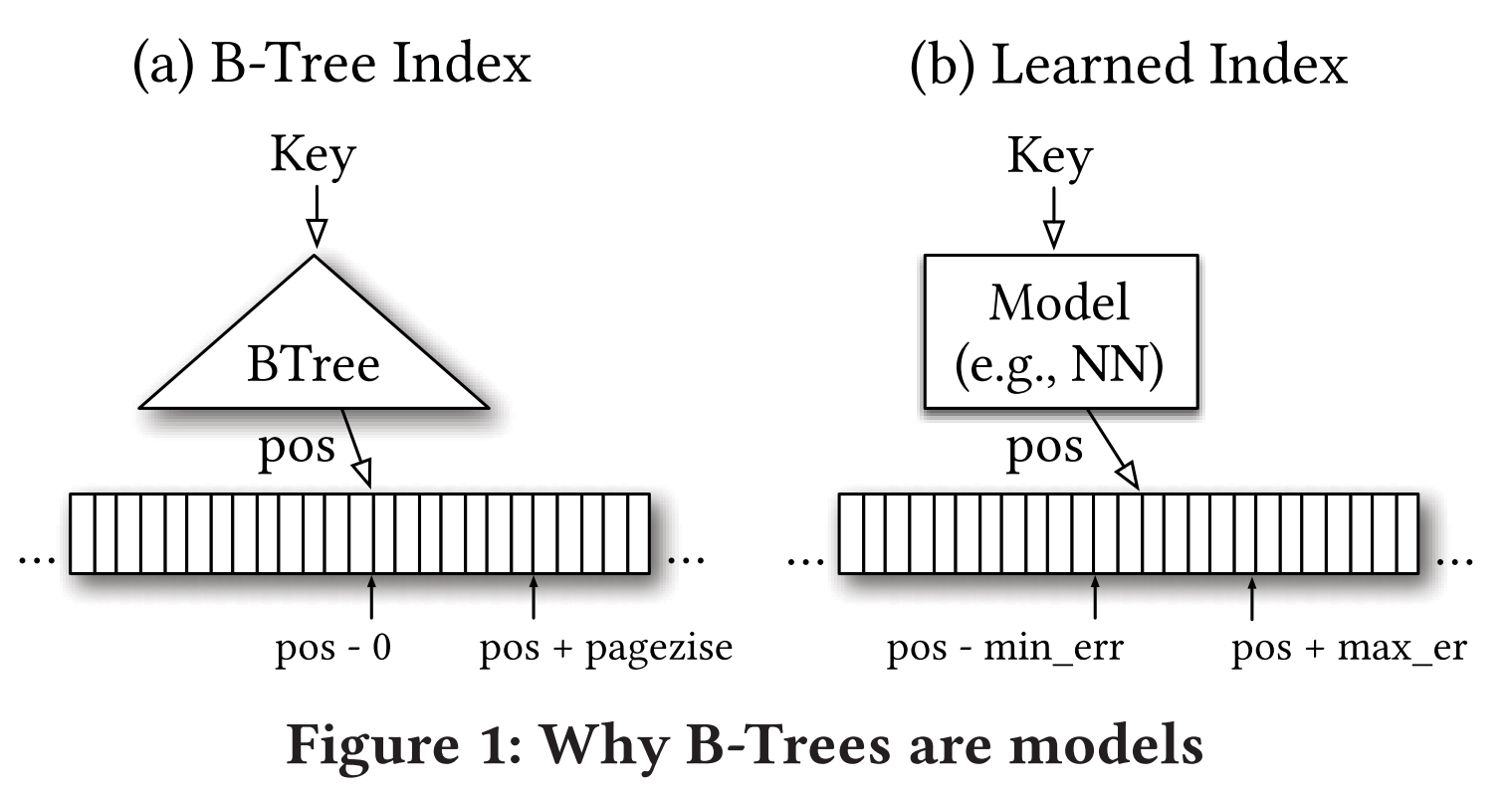
如何替代?
- 训练模型:① dataset:key array,② 获取训练过程中的最大最小误差:max_err,min_err
- Workflow: key👉ML Model👉pos👉[pos - min_err, pos + max_err],读取该范围内所有数据精确查找
range index,数据有序
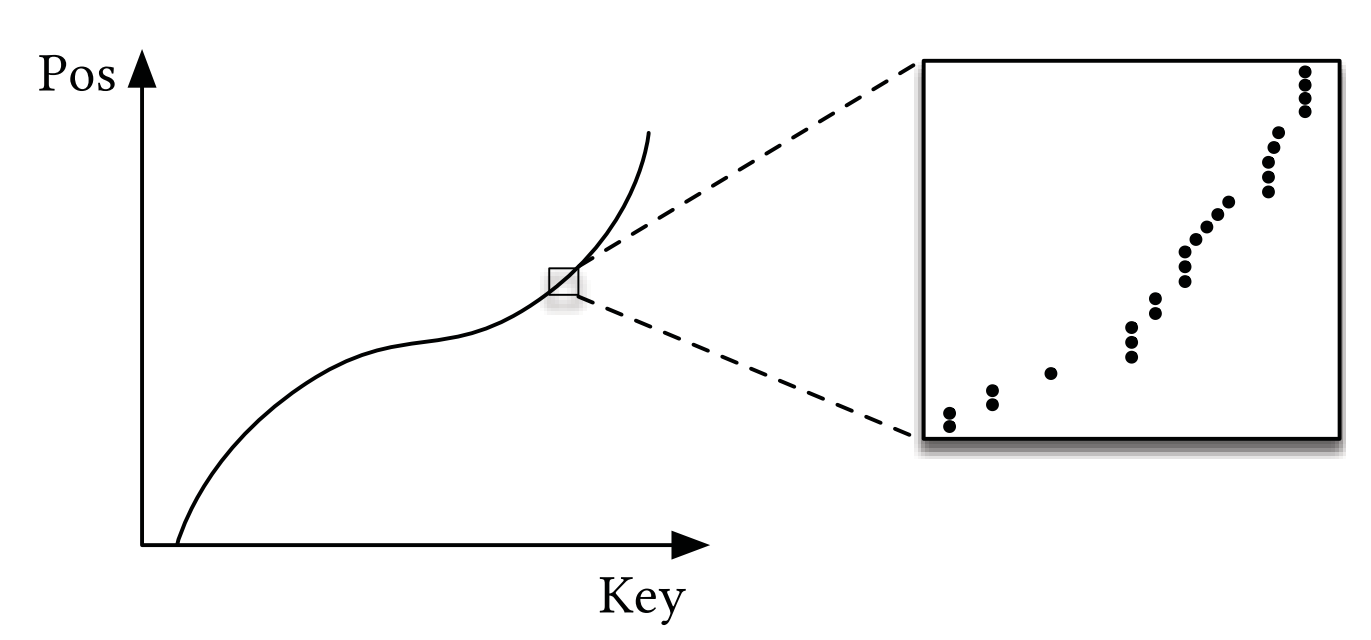
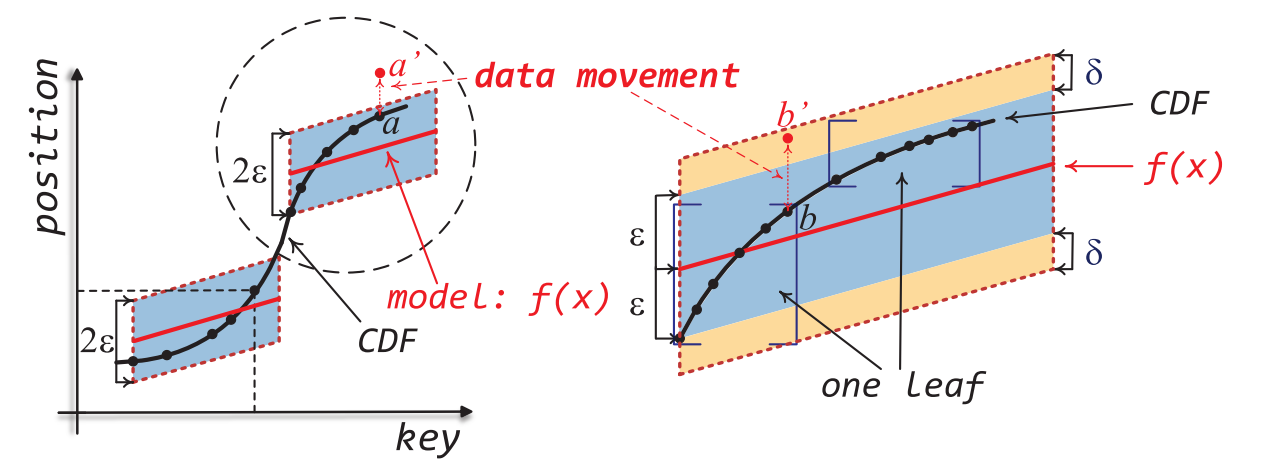
模型:数据存储在有序数组,直接通过简单模型拟合CDF(累积分布函数)来实现位置预测
解释:假设F(x)为预测的累积分布函数(CDF),表示key值小于x的概率;N为数据总数。则F(x)*N表示key值小于x的元素个数,也即当数组有序时,pos = F(x) * N 即为key=x的下标。
2. XStore
OSDI’20
场景:远端内存访问,server端存储ordered kvstore的数据和索引(range index,B+树),多个client端读取kvstore,通过RDMA来加速读路径。
2.1 Insight
问题:现有 索引结构 不够高效
读操作使用one-sided RDMA,每个RTT只能访问树型索引的一层,需要进行迭代式查询,消耗多个RTT
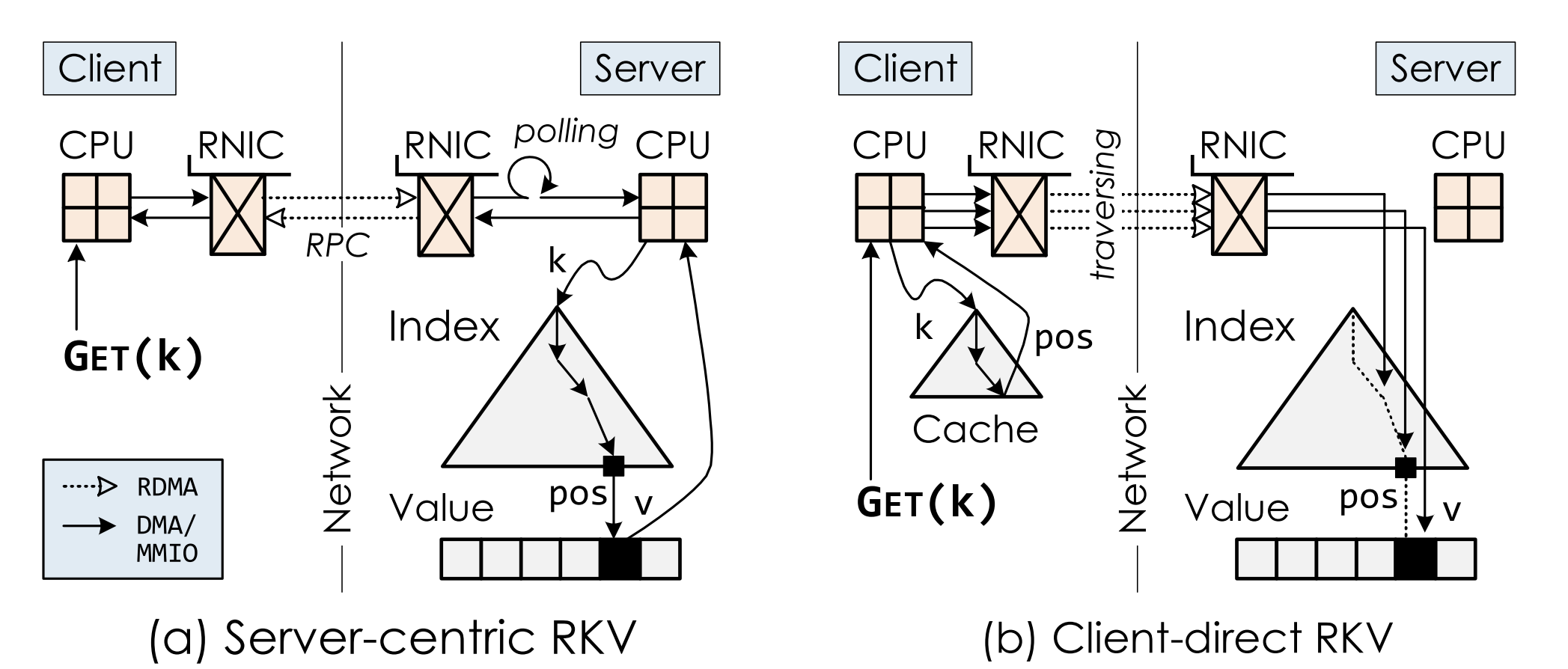
为了解决这个问题,引入了Index cache,cache索引树部分节点。
尽管引入index cache,依然不够高效,原因如下:
- Cache consumption:消耗cache多(654MB for 100M KV pairs)
- Memory-intensive:遍历树型索引是内存密集型操作,包含O(logN)随机内存访问(CPU花在index cache的时间占比30%)
- Cache invalidation:写密集场景下,
- False invalidation:不同数据节点共享查询路径(path sharing),B+树更新索引是递归的,一个数据节点没有被修改,查询路径cache也可能是失效的
- Bandwidth:更新cache时读取的索引节点多,挤占网络带宽
这几个问题随着数据量增大、B+树变大,会更严重
观点:Learned Index 更适合作为 Index Cache
读操作:key->ML Model->[pos - min_err, pos + max_err],client通过一次RDMA读取范围内key,本地查找得到精确地址。
- Cache consumption:cache模型即可,牺牲精度,换取相比B+树的更少的内存占用(6.7MB VS 600MB)
- Less memory access:一次计算+O(1)访存就可以得到目标key值,无需多次随机访存/网络roundtrip
- Cache invalidation:只需提供近似的估计,减少/推迟cache invalidation;模型小,更新消耗带宽少
挑战:如何适应 dynamic workload?
(进一步减少invalidation开销)
- Learned index 假设数据存储在一个有序数组;range index + CDF;插入时排序开销
- Learned index 误差上下界(min_err, max_err)是静态确定的,修改之后cache invalidation,需要retrain。
目标:减少这两者的开销
2.2 Solution
2.2.1 保证有序
B+树叶节点逻辑连续,可以视为一个逻辑上有序的数组 → B+树叶节点作为dataset训练模型
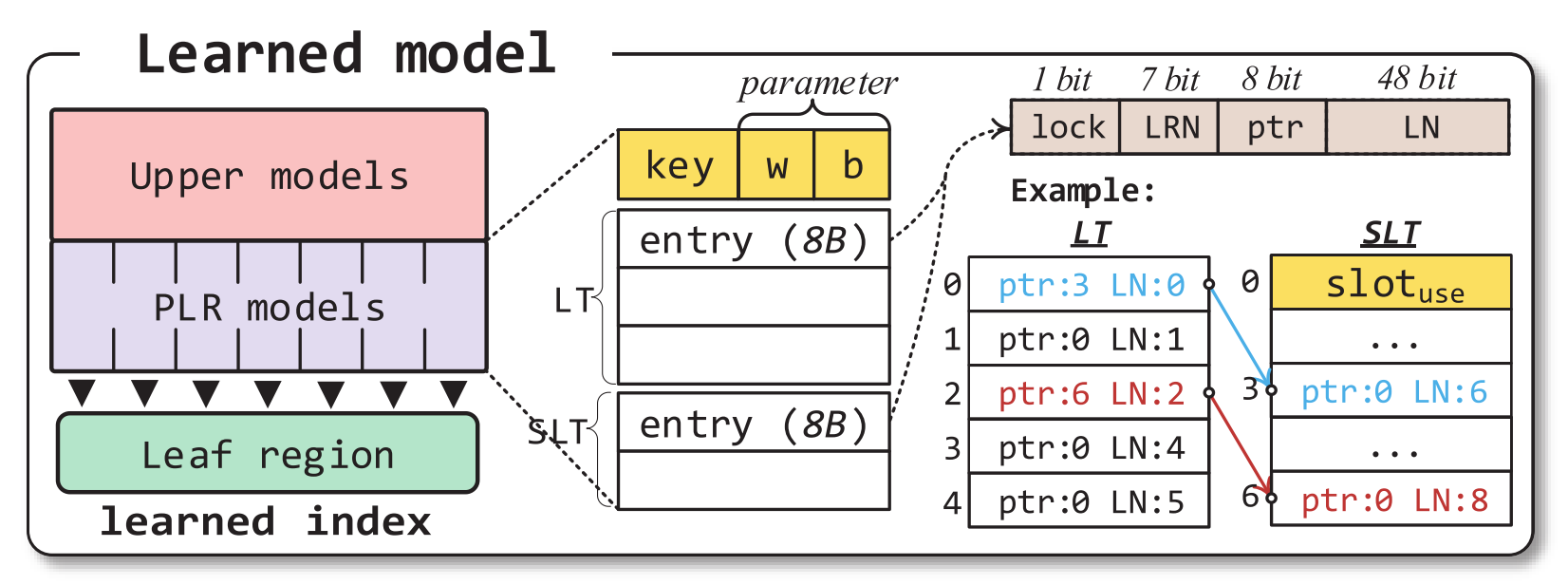
Hybrid:B+树索引(server),ML Model(client)作为 index cache。
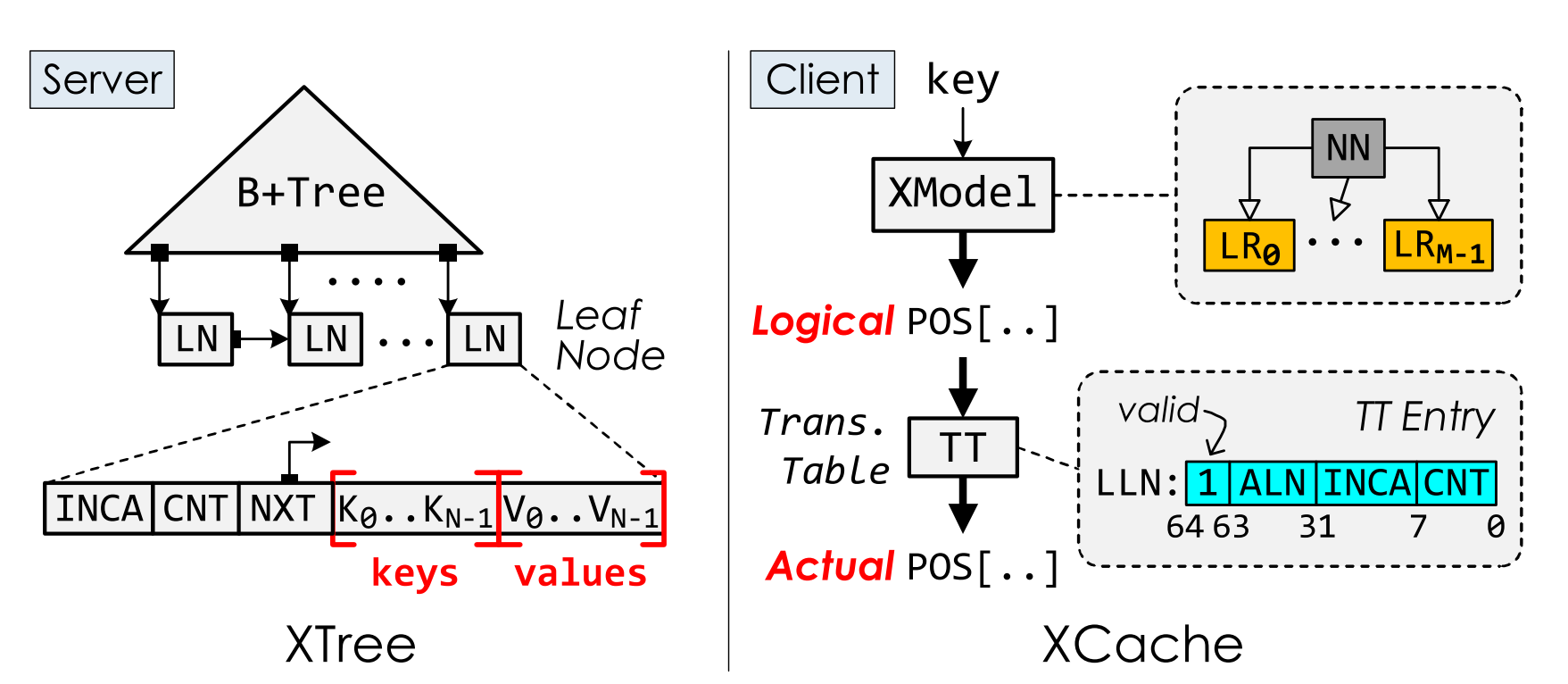
Index Cache 分为两部分:
- XModel:由server端训练,client按需cache
- 中间层TT:叶节点地址不连续,为了保持叶节点之间有序,需要在server端维护translation table转换逻辑地址和叶节点地址。由server端维护,client按需cache
Update 复用B+树结构,减少时间复杂度和并发控制复杂度
2.2.2 减少 retrain 开销
分段retrain
- 两层模型,top为一个 NN,第二层为若干个 linear regression (LR)。
- 简单模型,开销小;
- Partial retrain: 当数据发生变化的时候,可以只更新sub module
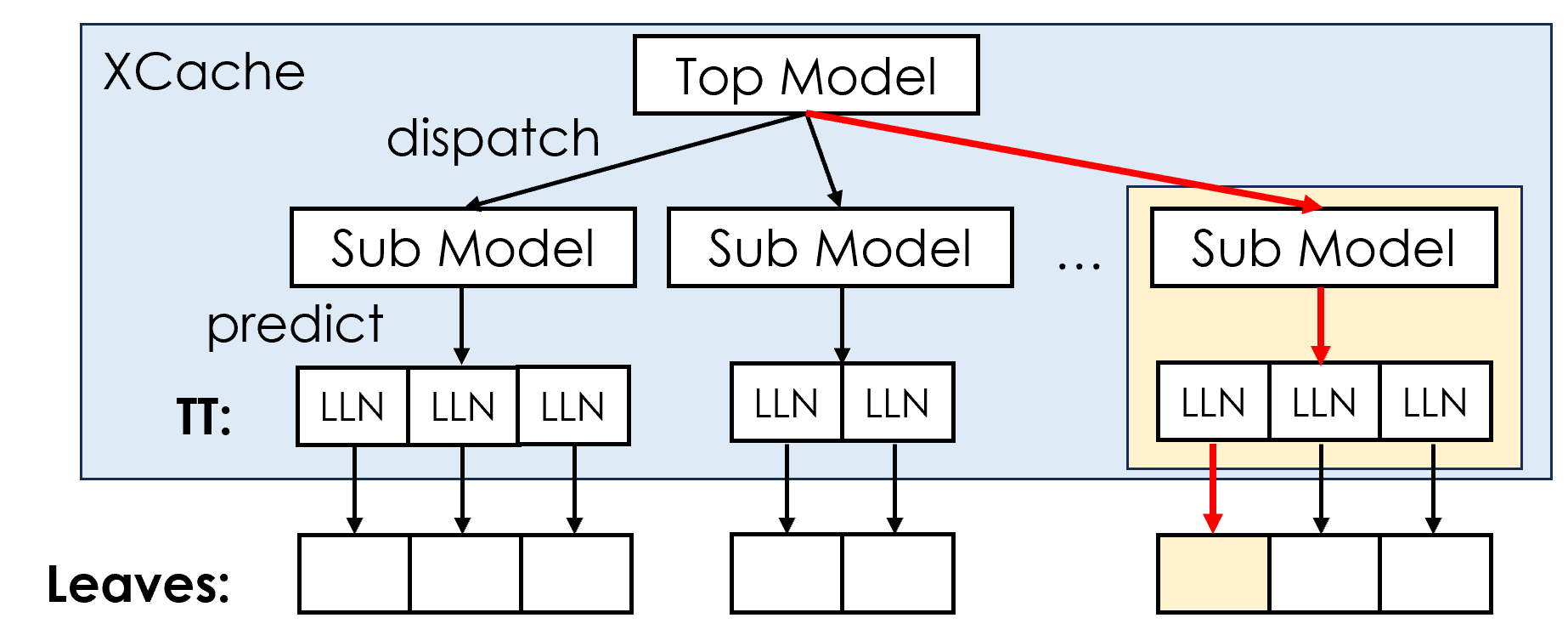
降低retrain频率
只在叶节点分裂的时候,才对 sub model 和 TT 进行异步更新
Q: 节点没有分裂的时候(normal insert),为什么可以用陈旧的 cache (model+TT) 获取正确的结果?
A:
正确性定义:能查到所有已有数值。新插入数据不会误判为不存在。
读取粒度为叶节点,引入两层映射关系:

key值最终映射到一个叶节点;每次RDMA读取粒度为一个叶节点。
只有在节点分裂的时候才会改变TT的映射关系(发生data movement),此时才需要重新训练;否则,读取一整个叶节点,然后进行local search,总能找到所有存在的值
本质上相当于引入了一层约束,保证数据移动带来的误差不超过一个叶节点。
2.2.3 Discussion
关于模型的选择,在两点上存在trade-off:① memory consumption;② retraining cost
简单的模型更新开销小,但需要堆数量以更细粒度更精准,消耗更多内存;
复杂的模型更新开销大,但消耗更少的内存。
2.2.4 Details (SKIP)
并发控制
- Correctness condition: no lost keys,读的时候原子地返回新值或者旧值就可以
- 多读者(client)单写者(单机server),简化并发控制
- 事务内存HTM,可以检测到并发RDMA操作
- 使用 cacheline versioning 保证RDMA跨cacheline读的原子性
如何处理数据增多时,误差不可避免地增大?
- 动态增加sub module的数量,这个过程需要retrain整个两层模型和TT。但不会影响性能,可以边运行边retrain,原因如下:
- TT相当于引入了一层快照,训练过程只需修改TT即可,不会移动数据,所以还可以继续用stale state或者fallback到B+树处理请求
- 通过调度,可以推迟冲突的sub module的retrain
- top module(训练开销相对较大)可以在数据不完整情况下retrain
- 值得注意的是,XStore也可以在删除值较多的情况下对model进行shrink resize
Optimization: 减少节点分裂时候的fallback
Speculative execution:其实是一个比较常见的思路。observation是,一般分裂只会移动一部分数据到新的sibling节点,所以只需要在该节点找不到key值且能确保不是non-exist的时候,顺着sibling指针查兄弟节点就行。
Range query + corner case
参见5.2.2的range query过程,以及5.2.3对corner case的描述
如何持久化?
Xcache 只用作读路径优化,对logging没有影响,并且可以rebuild。
如何scale out?
根据key range进行sharding
叶节点键值分离存储
当预测范围跨多个叶节点的时候,需要读取所有叶节点的键值对,会造成一定网络带宽放大,特别是一般情况下value很大很大。而事实上只需要读取key进行验证就够了,所以XStore的做法是先读metadata+key array,再算出value的offset去读,一共两次RTT。
2.3 Evaluation

2.3.1 Overall
- RDONLY:outperforms SOTA by up to 5.9× (from 3.7×)
- RW:up to 3.5× (from 2.7×) throughput speedup
2.3.2 Retrain开销
- 2个线程足够
- peak insertion speed: ↓ 13%
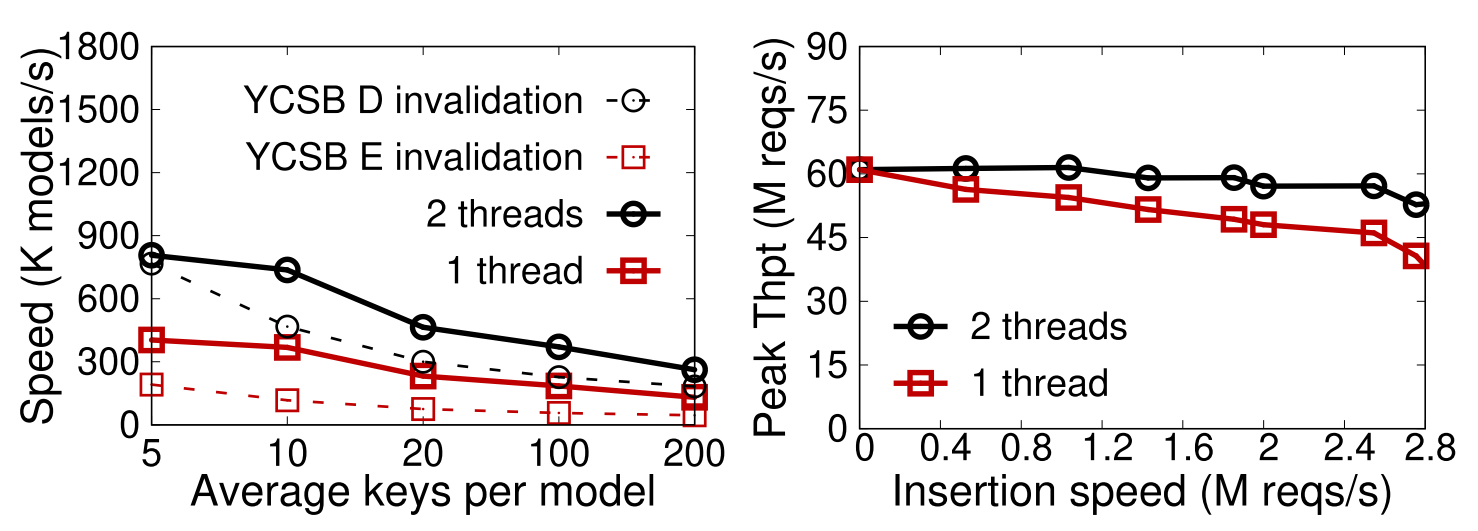
2.3.3 Data patterns
Key distribution
① 均匀分布;② 有噪声;③ 真实数据集
需要更细粒度的sub module拟合更复杂的分布情况
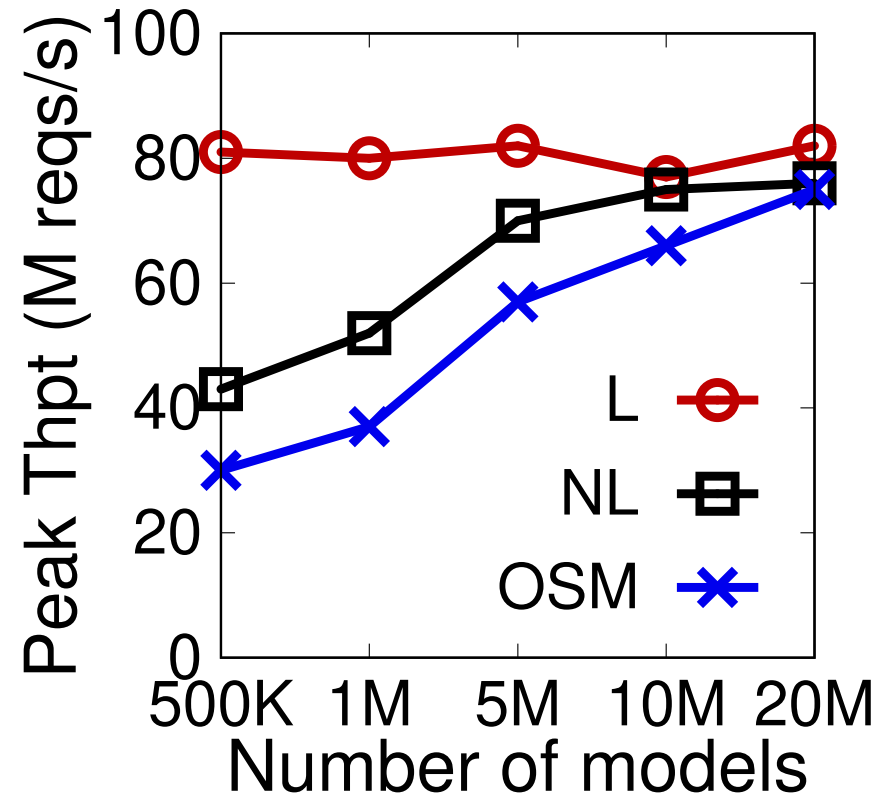
Access pattern
① 均匀访问;② 访问最新
②带来相对频繁的model retrain
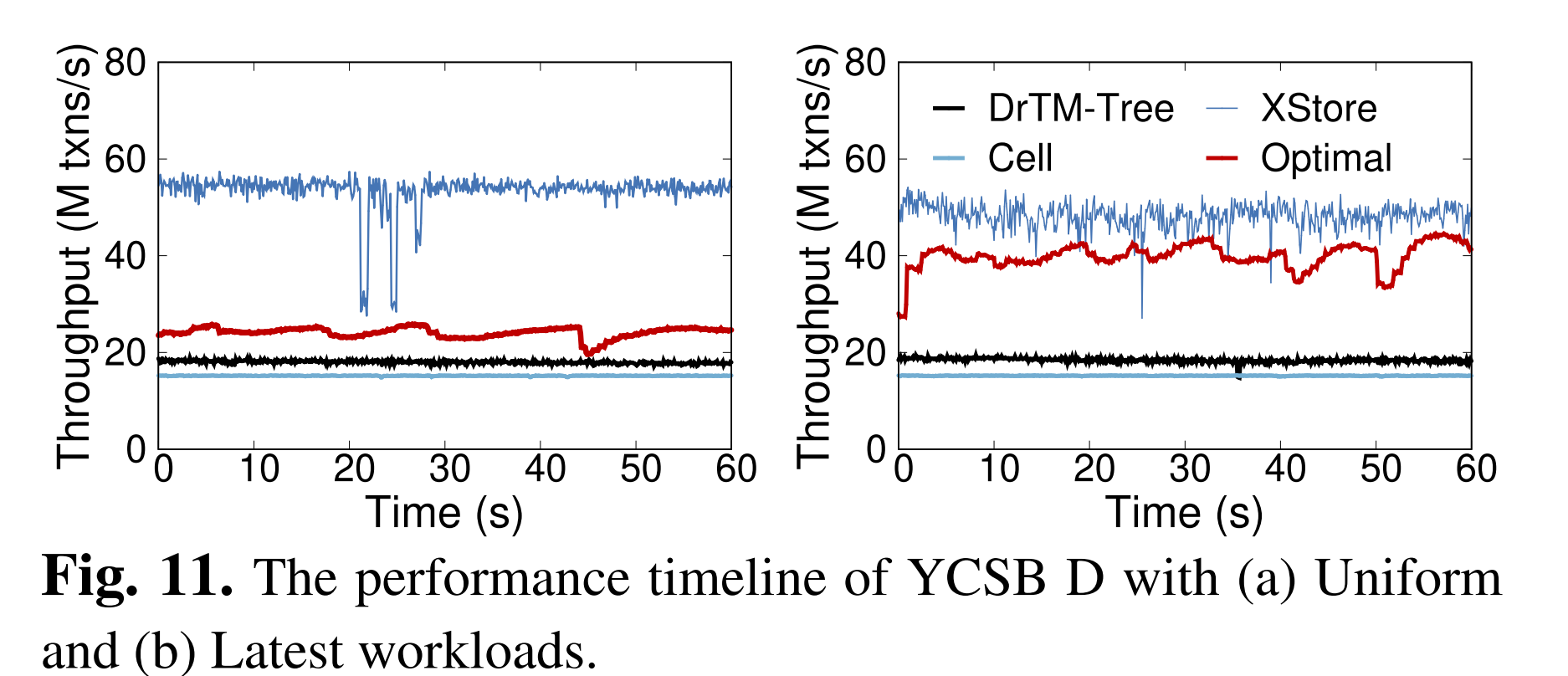
2.3.4 Sensitive analysis
Breakdown
相比于全cache情况占优

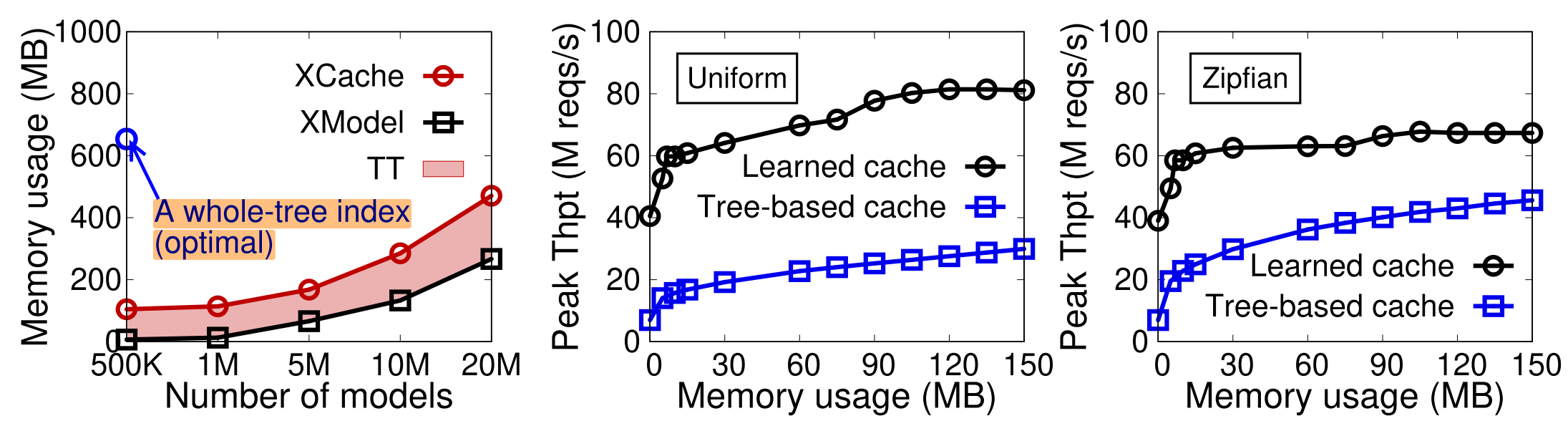
Memory usage
100M个KV的情况:
Whole-tree index: ~600****MB
Model size: 500K sub-models, 6.7****MB
- Sub-Model: 14B; two 32-bit floatingpoint model parameters, two 8-bit min- and max-error, and a 32-bit TT size.
TT size: 100****MB,client按需cache
- 15% of the whole-tree index。TT本质上相当于B+树的最后一层索引,并且TT entry比B+树索引节点小,所以内存开销更小。
Prediction error
- RDONLY: The prediction error of XCACHE is just 0.74.
- RD latest: The prediction error would stably increase to 8.3 for YCSB D
- 一次读取1~2个****叶节点
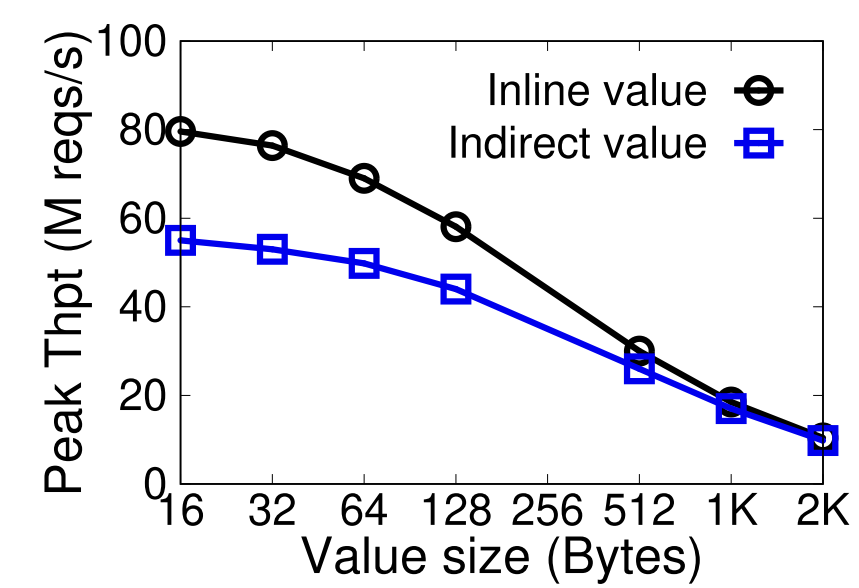
Inline/indirect KVs
indirect需要additional one RMDA
3. Related work
FAST’23 ROLEX
针对DM场景,拓展XStore的实现。
他的结构和核心观察(控制读写粒度)都跟xstore差不多,只是去掉了B+树,留下了叶节点,通过delta index来缓解写操作带来的压力。
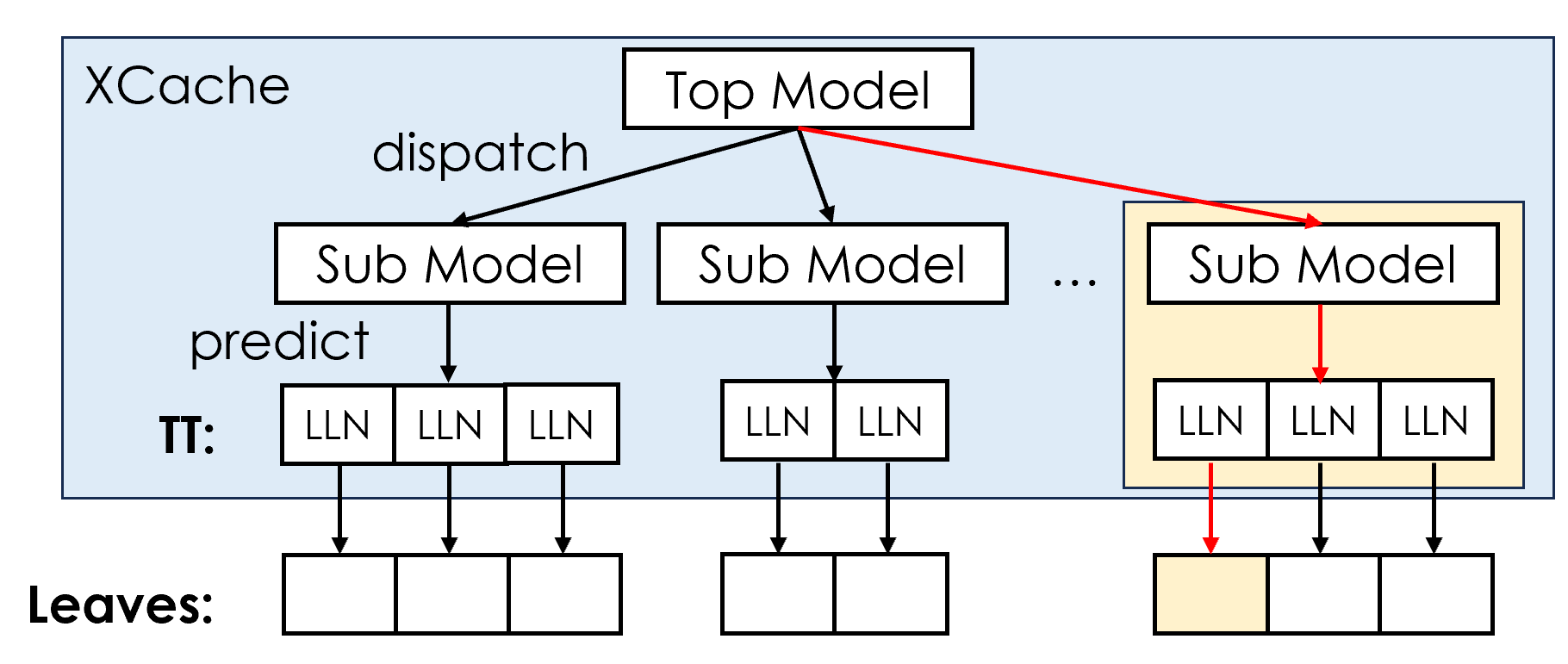
缺陷:每次读数据需要读取更多叶节点
SOSP’24 CHIME
hybrid index,用哈希表取代B+树叶子节点,将预测范围缩小在configurable的邻域内,减少叶节点数据对网络带宽的放大。
My note: CHIME
4. Comments
新技术在相对传统场景的应用,the first
① 新技术:learned index;② 传统场景:单机server,RDMA加速读操作
分析很全面
- 为什么传统方法不适配;为什么新技术更适配
- 新技术面临的挑战与trade-off(memory consumption,retrain cost)
更多针对抽象分析(far memory)而非具体的场景,所以在现在更流行的DM (Disaggregated memory) 上分析依然不过时。
解决方法精炼、solid
经典system思想:分段、读写分离hybrid架构、indirect layer to decouple(TT);考虑周全,实验完善
设计与场景适配:针对传统场景对实现进行了一些剪枝,突出重点
- Dynamic workload的支持
- xstore 通过B+树实现 in-place update,从而减少排序开销;
- 读写粒度为一个叶节点,减少 retrain 开销。(空间换时间)
- scenario-specified
- 模型简单性
- 考虑数据冷热,提高对热键的预测精准度;不同key值分布
- 有讨论分析
- server端的CPU bottleneck
- server端需要处理写请求,还需要重新训练模型
- 面向单机server,CPU资源相对(DM)充足;scale out可以缓解