【2024.12.27 report】
CHIME: A Cache-Efficient and High-Performance Hybrid Index on Disaggregated Memory (SOSP’24)
Background
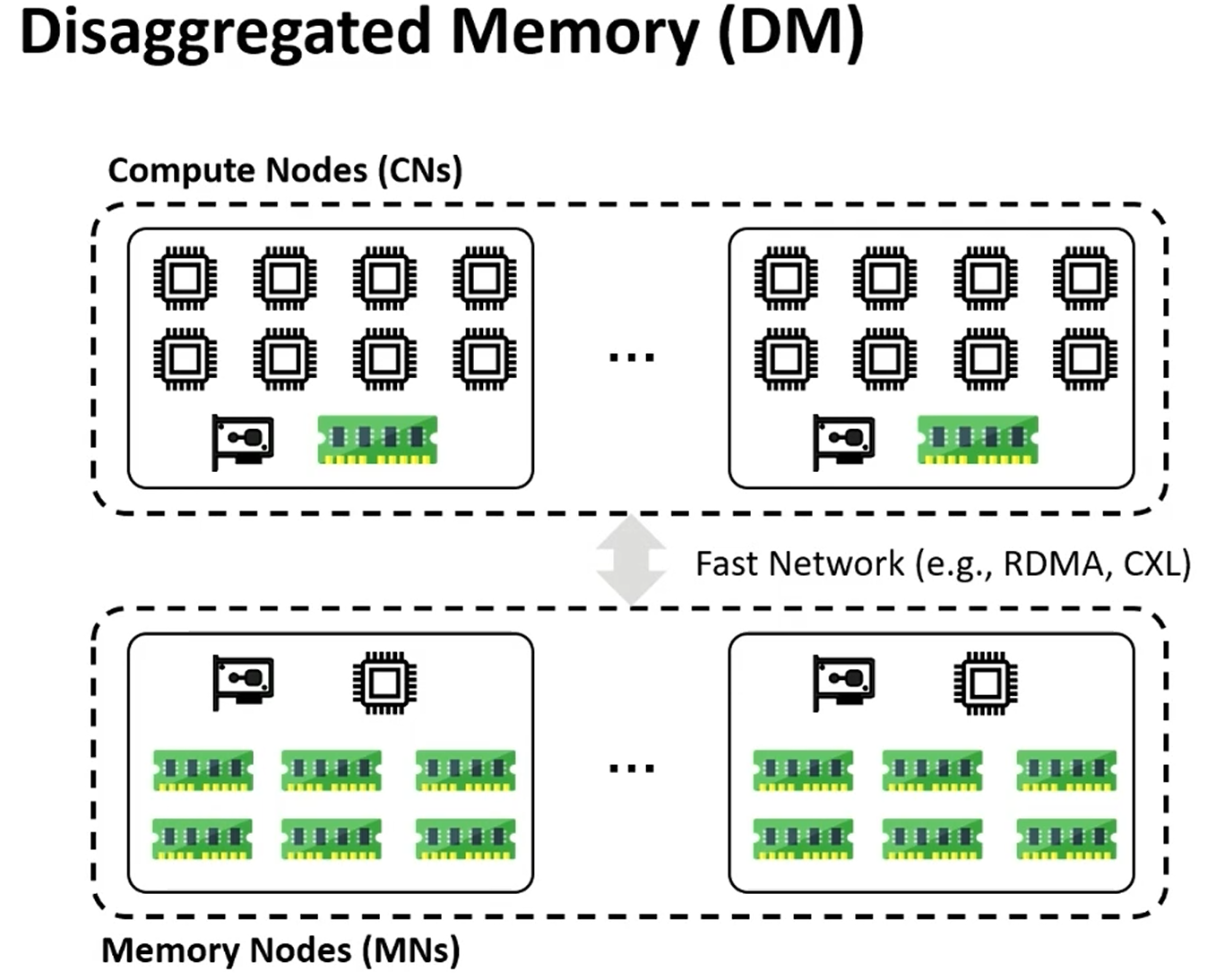
DM: disaggregated memory,分离式内存
计算节点和内存节点
计算端大部分内存访问都在内存节点,快速网络访问,少部分内存做cache
本文场景:
- Storage system: database,kvstore
- One-side RDMA
- 需要索引:range queries (1<=k<=5) + point queries (k==4)
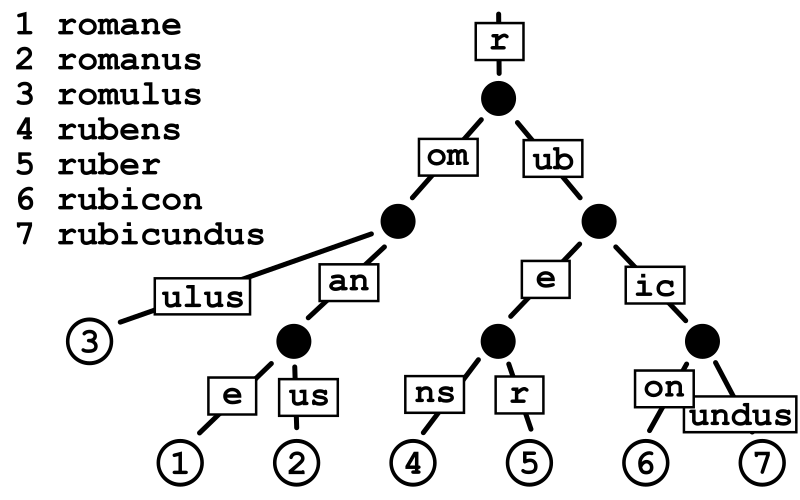
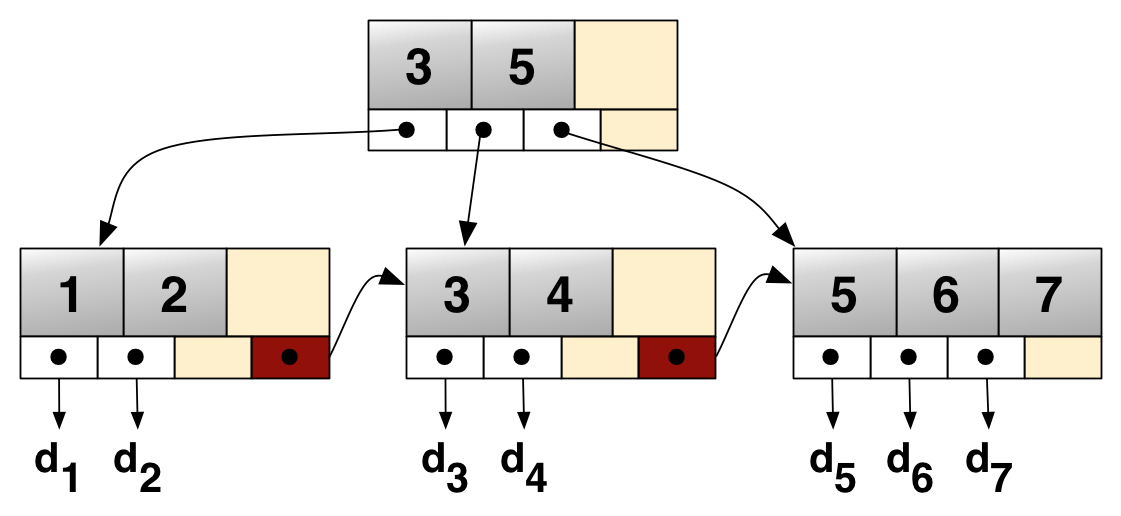
现有的DM索引:基数树 (radix tree);B+树;learned index(ML算法辅助)
查询流程:
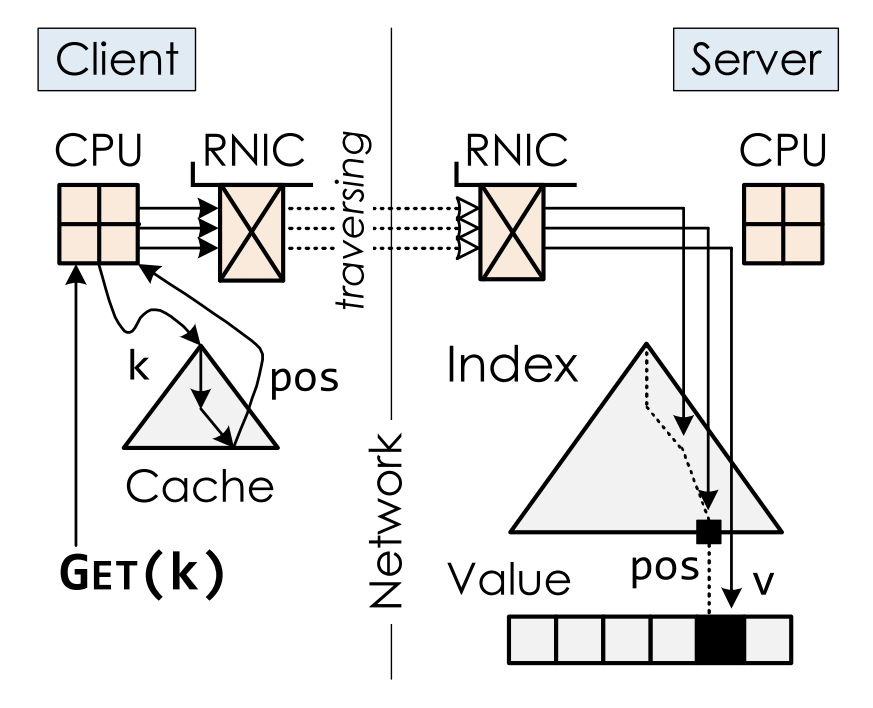
- 迭代式查询
- 本地cache减少查询次数
- 内存端近乎无计算资源,故而节点处理都必须在计算端完成(需要读取整个结点数据)
性能指标
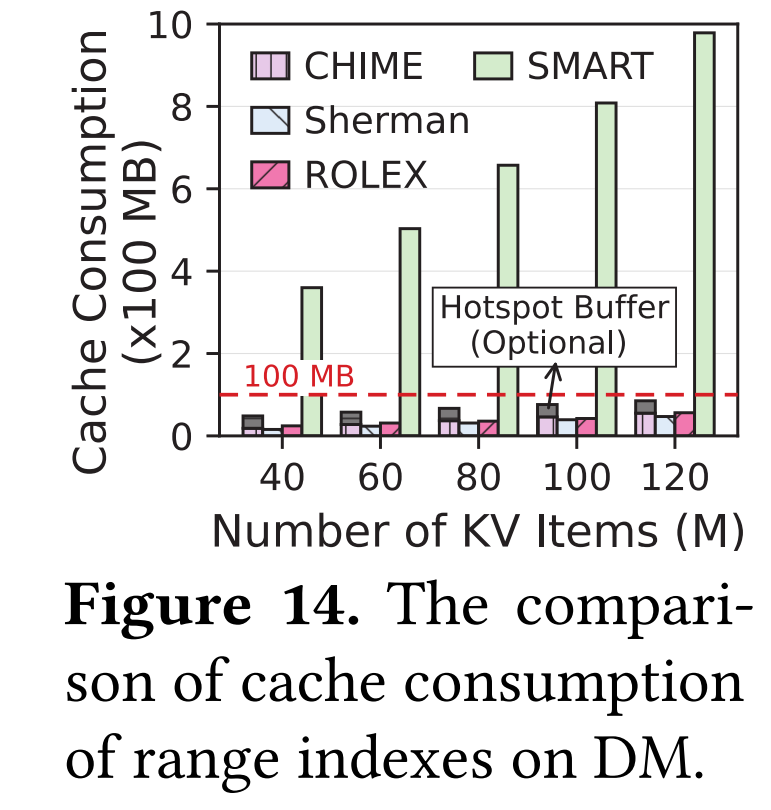
- 查找次数:Cache Consumption。计算端的cache消耗量,会缓存index node的地址(index caching)
- 网络带宽:并发读写情况,单次读写数据量(带宽)越小,吞吐量越高。Read Amplification(无效/有效)。只需查找某一段数据。索引数据块粒度越粗,读放大越大
Motivation
Trade-off between the computing-side cache consumption and the memory-side read amplifications for range indexes on DM!
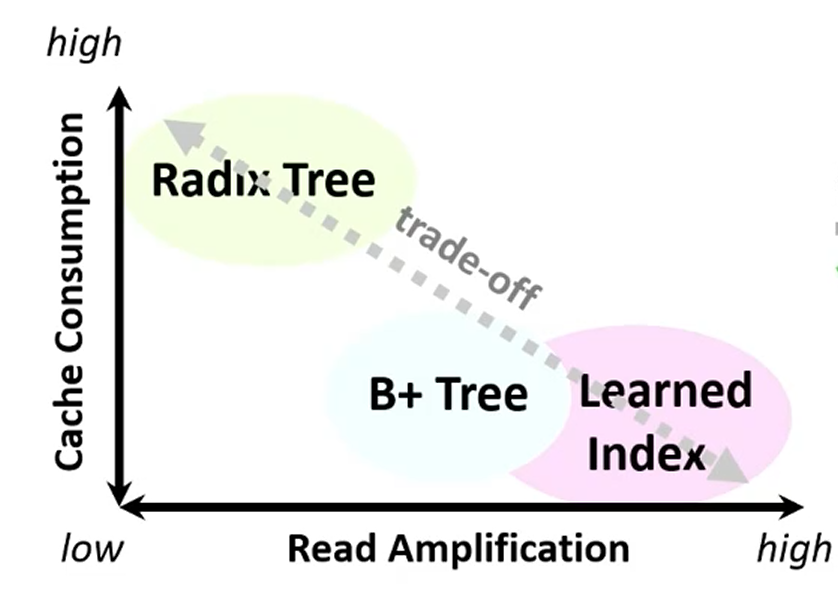
Cache Consumption
Index cache:缓存索引节点地址
B+树一个叶子索引节点对应一大段数据,基数树则一一对应,所以相同数据范围,B+树对应索引节点少,cache消耗量少
Read Amplification
每次取整个节点;叶节点存储数据
Solution
Hybrid: 粗中有细,B+树叶子节点再用一层哈希
Internal nodes: B+树
大多数都可以保存在计算端内存cache中(eval数据,不到100M)
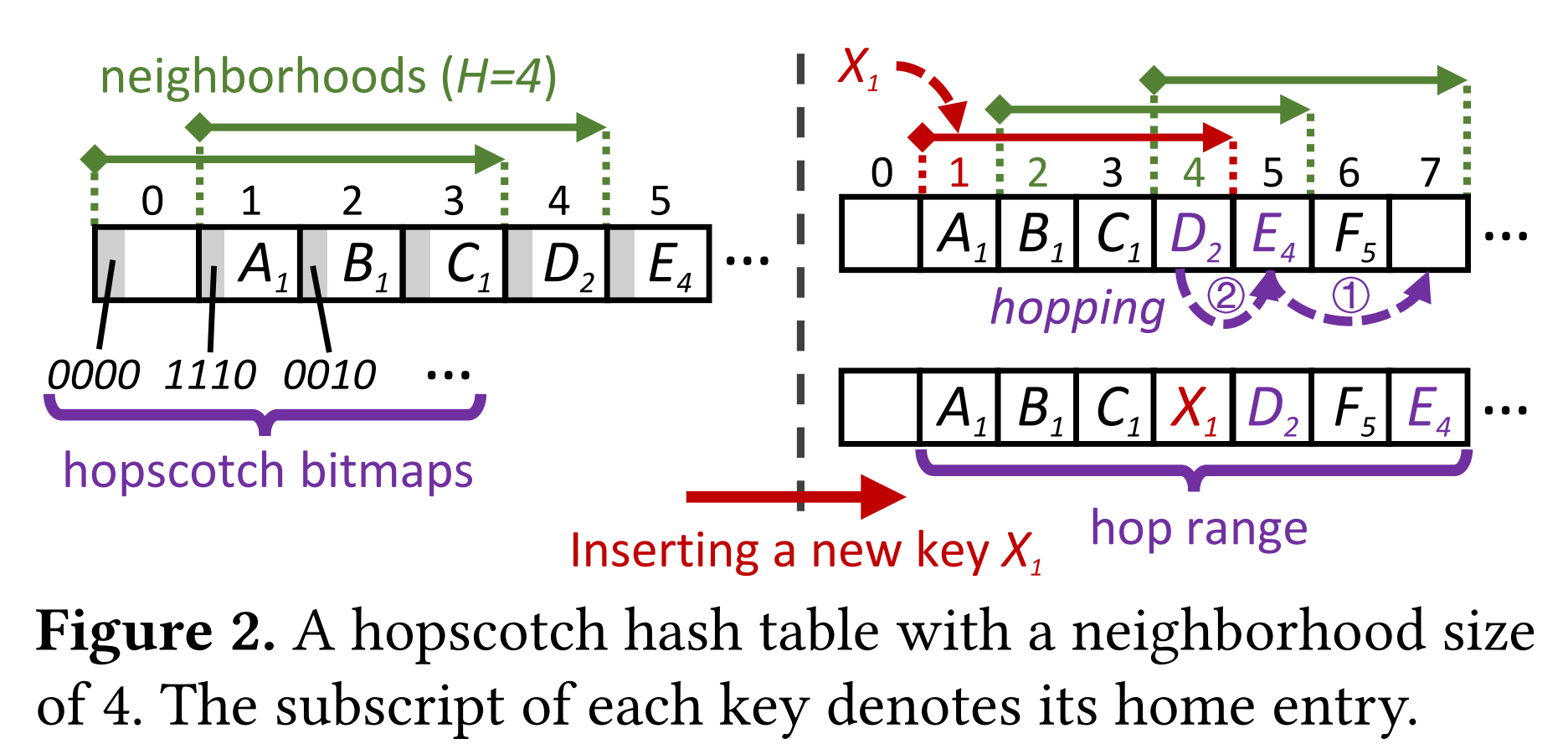
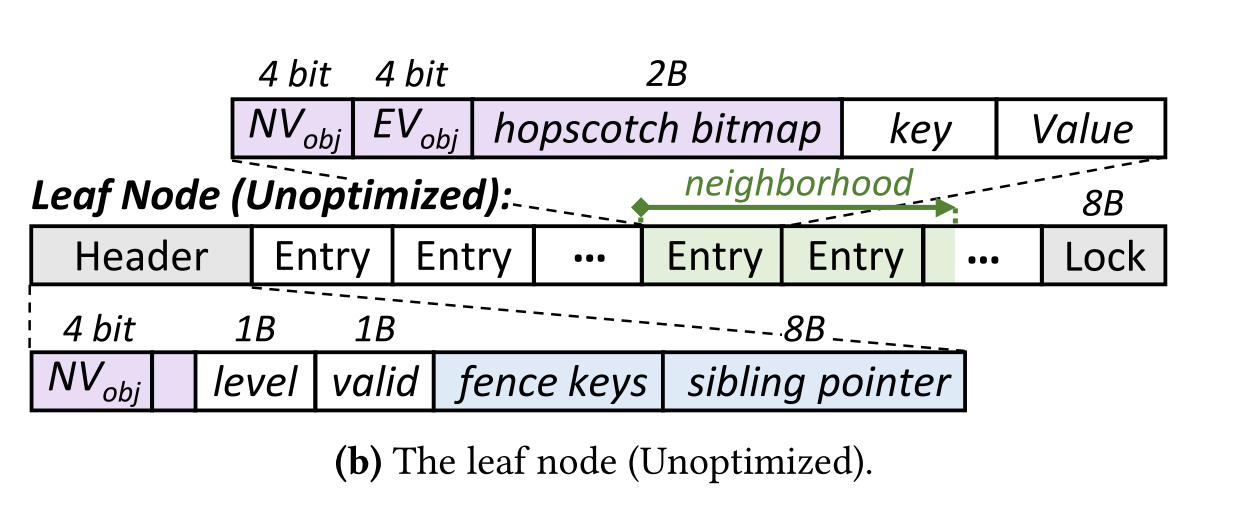
Leaf nodes: Hopscotch Hashing(跳房子哈希)
包含数据,用哈希表来消除
跳房子哈希:
解决哈希碰撞
邻域(H),保障数据一定在该邻域内
Eg. 哈希值结果为1,H=4,那么他保障数据一定出现在槽位1/2/3/4内。
Challenges:
如何高效并发控制?
原机制:
- 版本号实现乐观并发控制:写操作独占锁,读操作不加锁
- 写操作:版本号+1
- 读操作:① 读版本号 ② 读数据 ③ 再读版本号,验证一致;否则retry
问题:版本号机制依赖于读写粒度的一致性!
分类
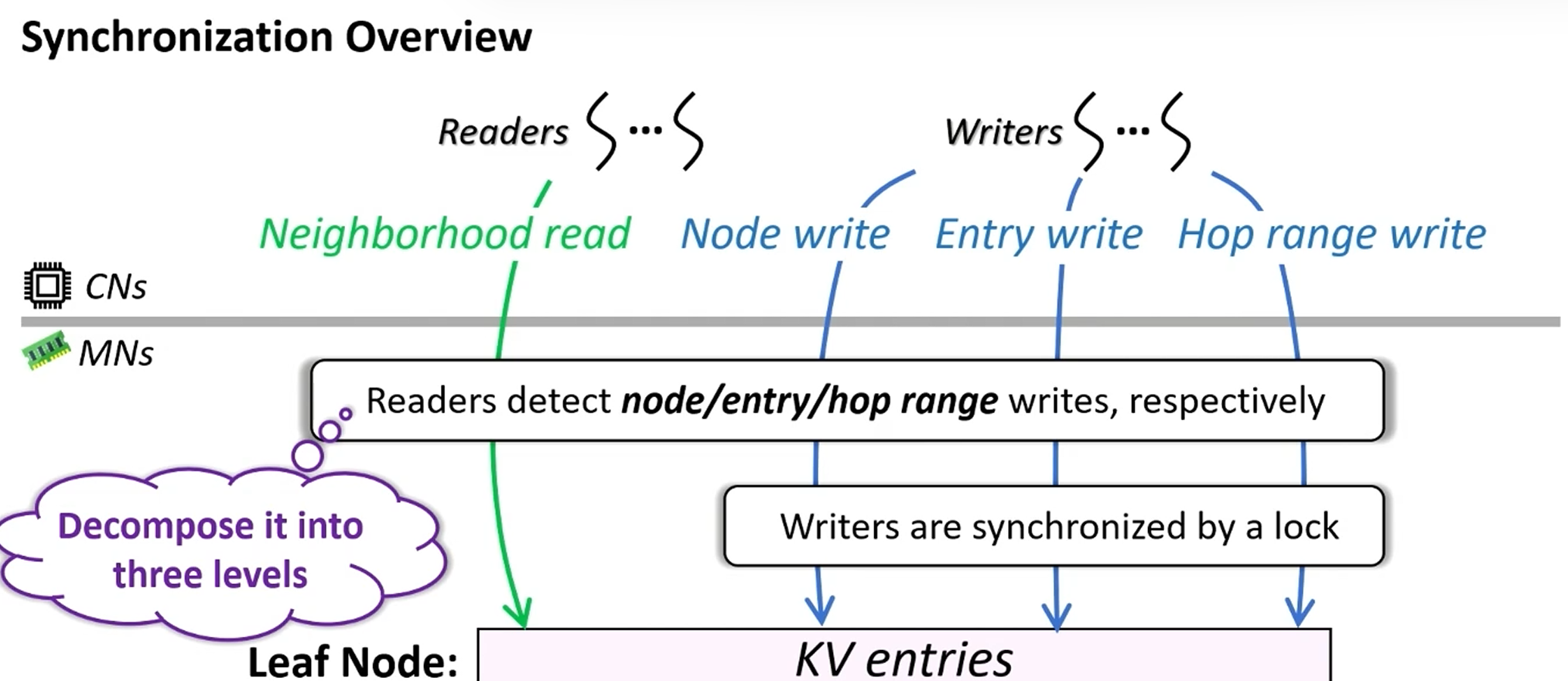
解法
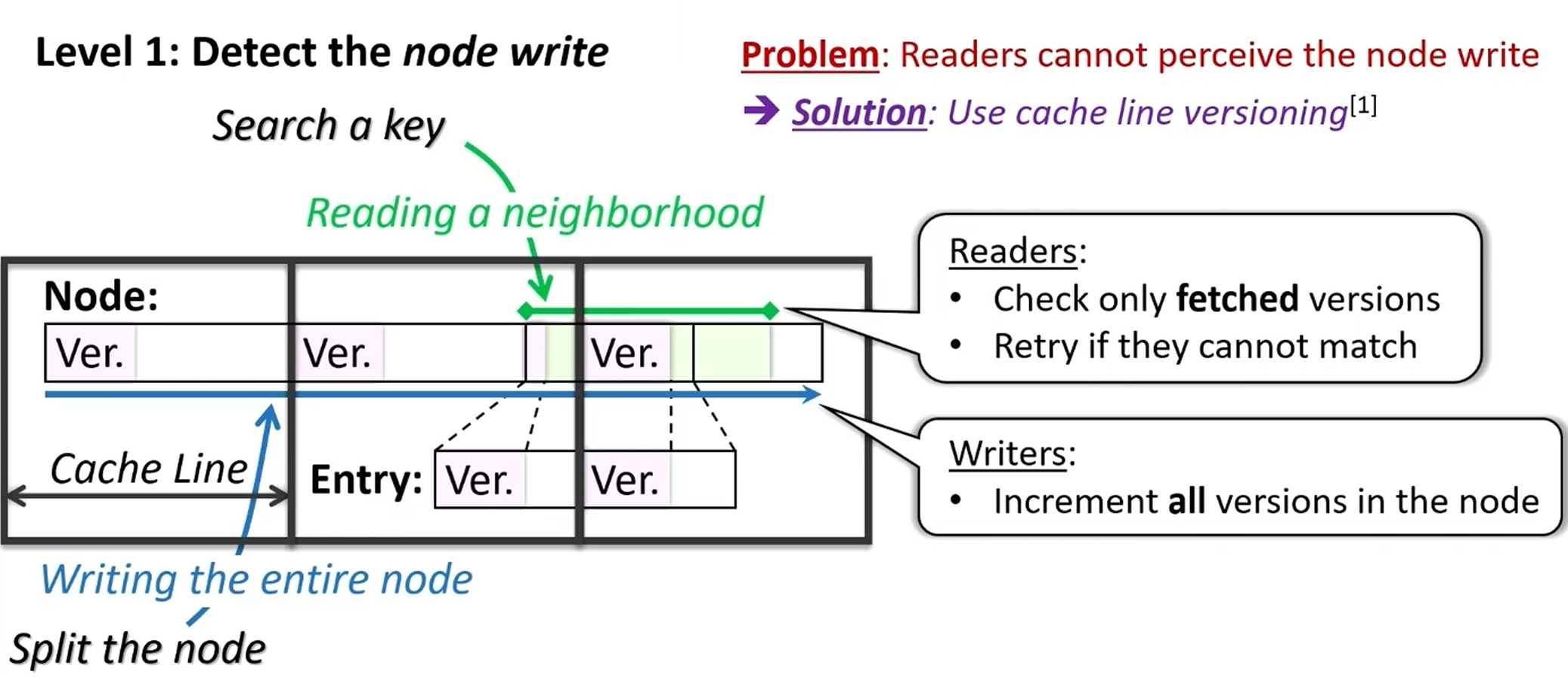
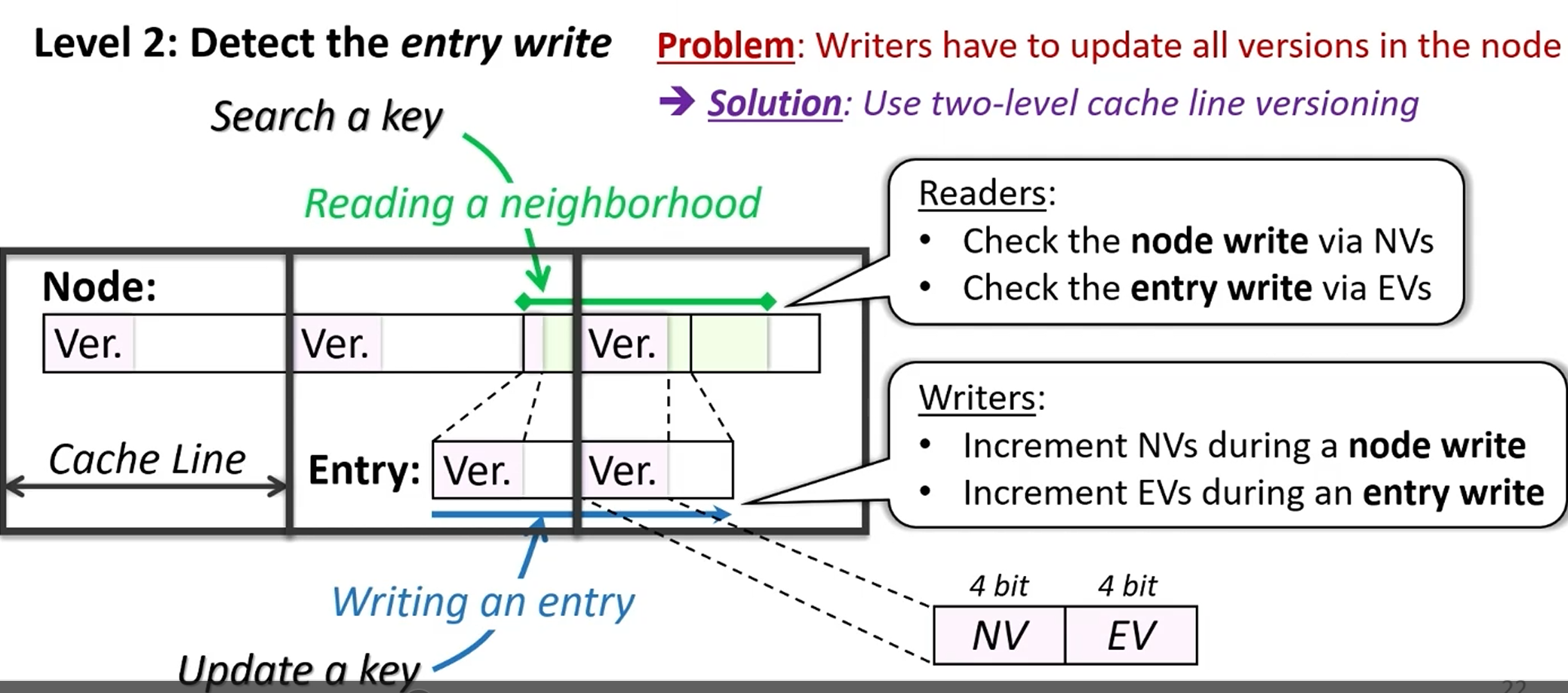
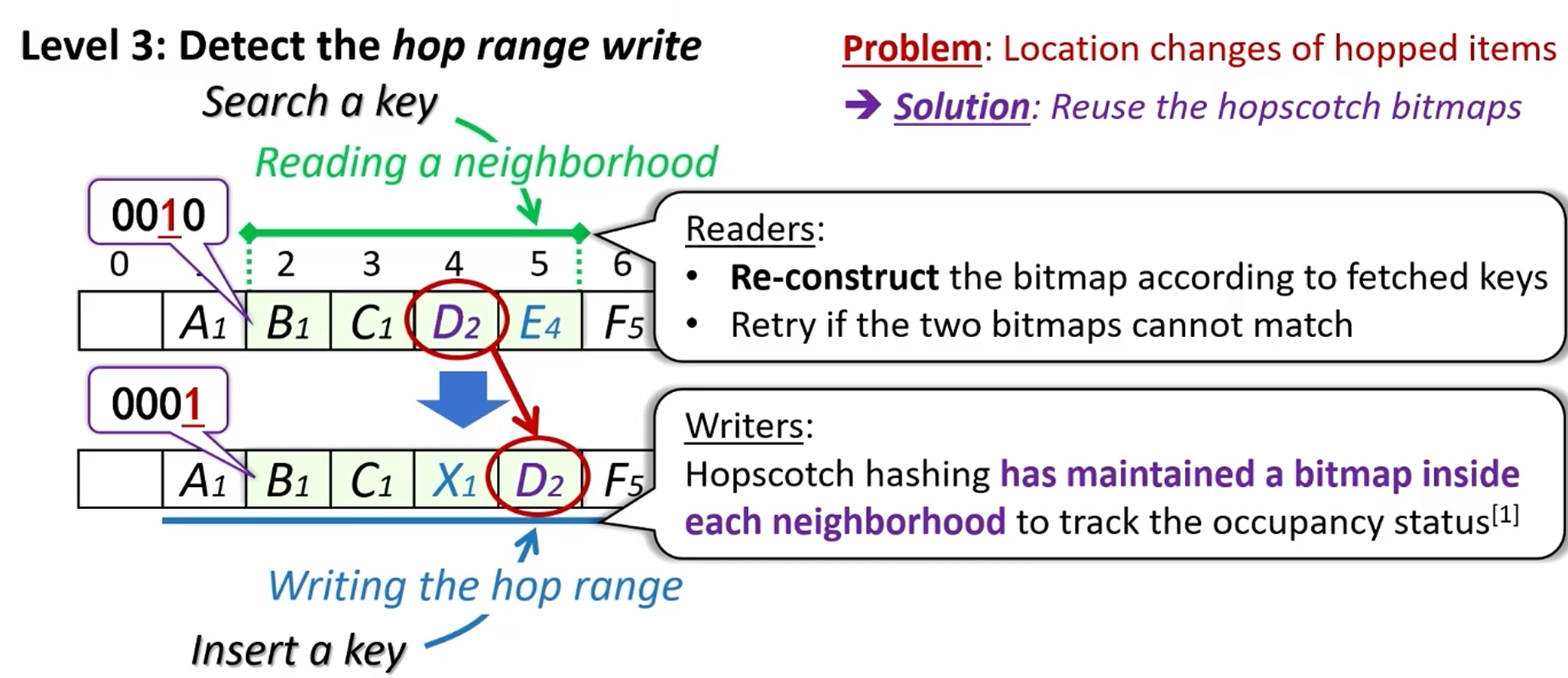
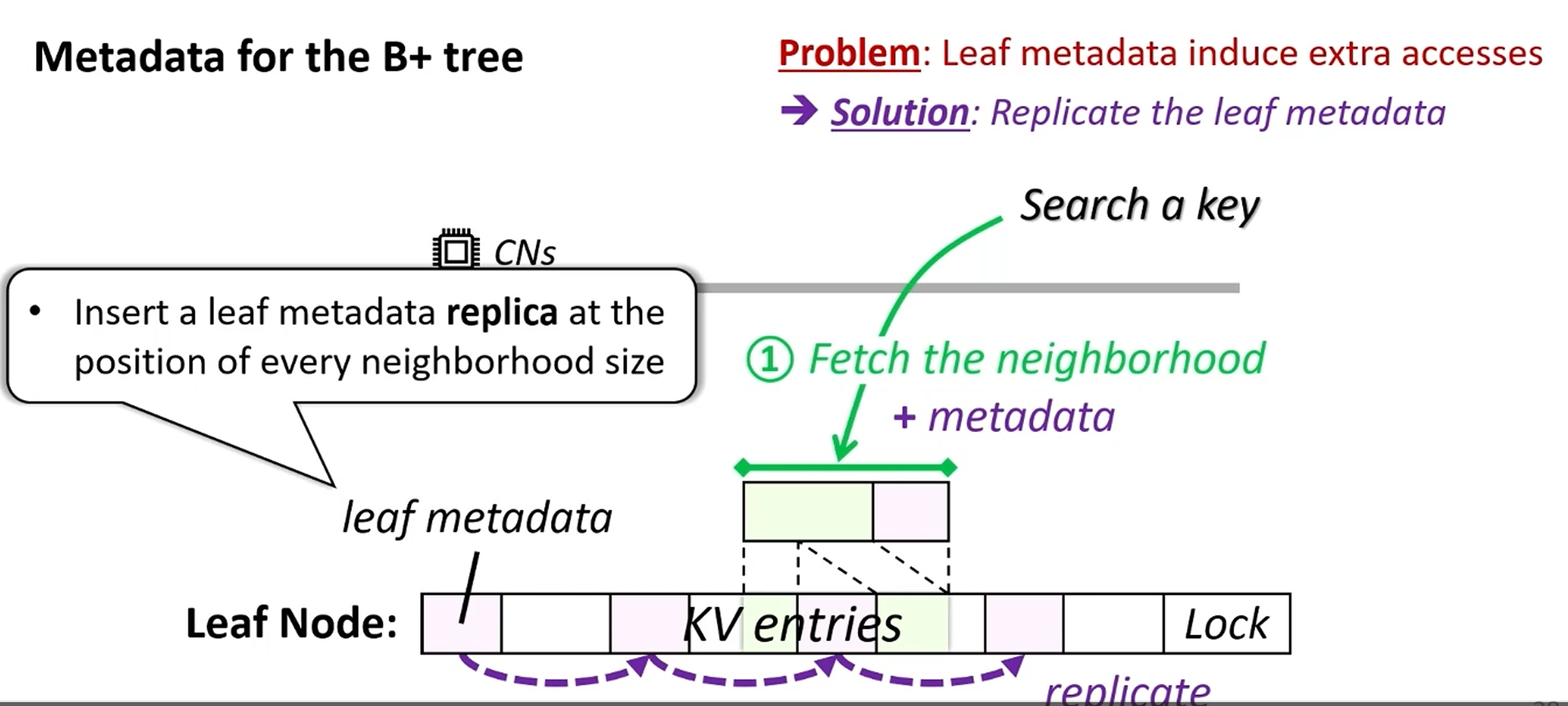
如何消除额外元数据读写?
hash(RDMA masked-CAS verbs)
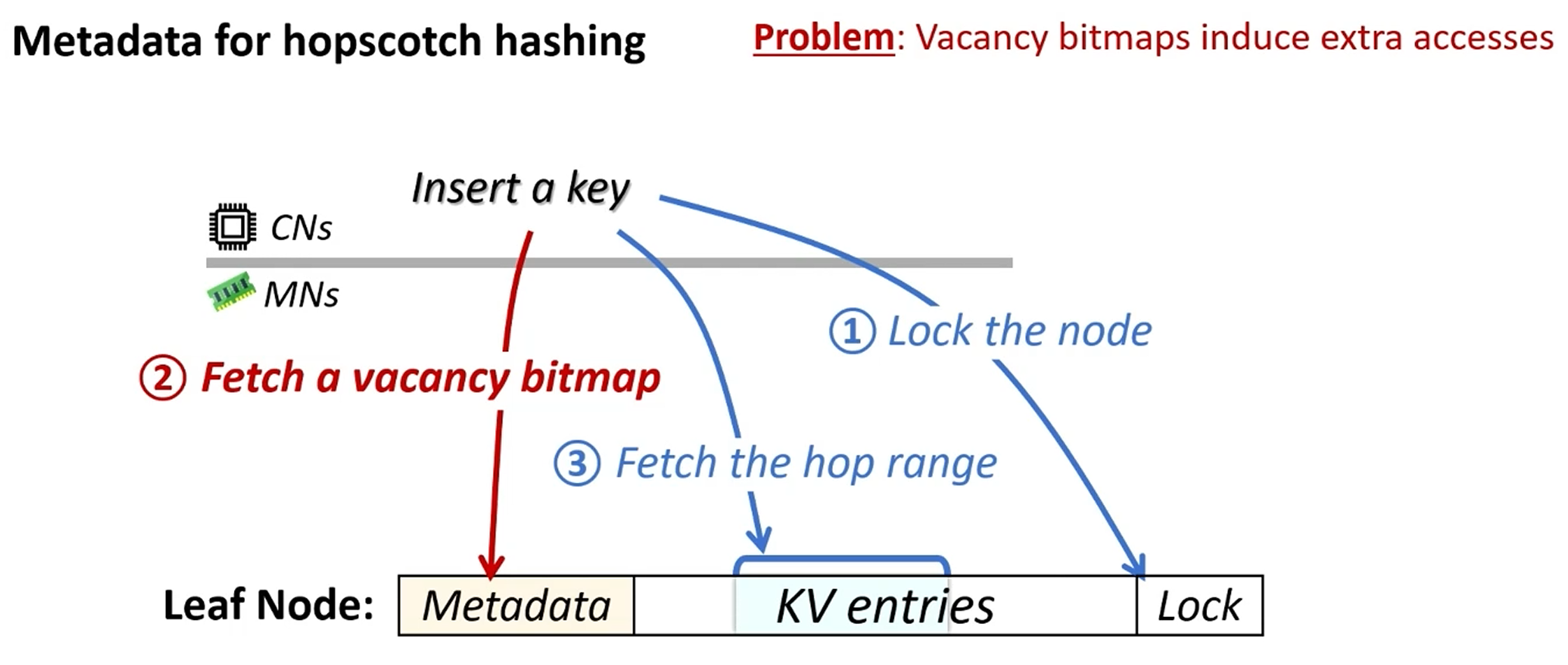
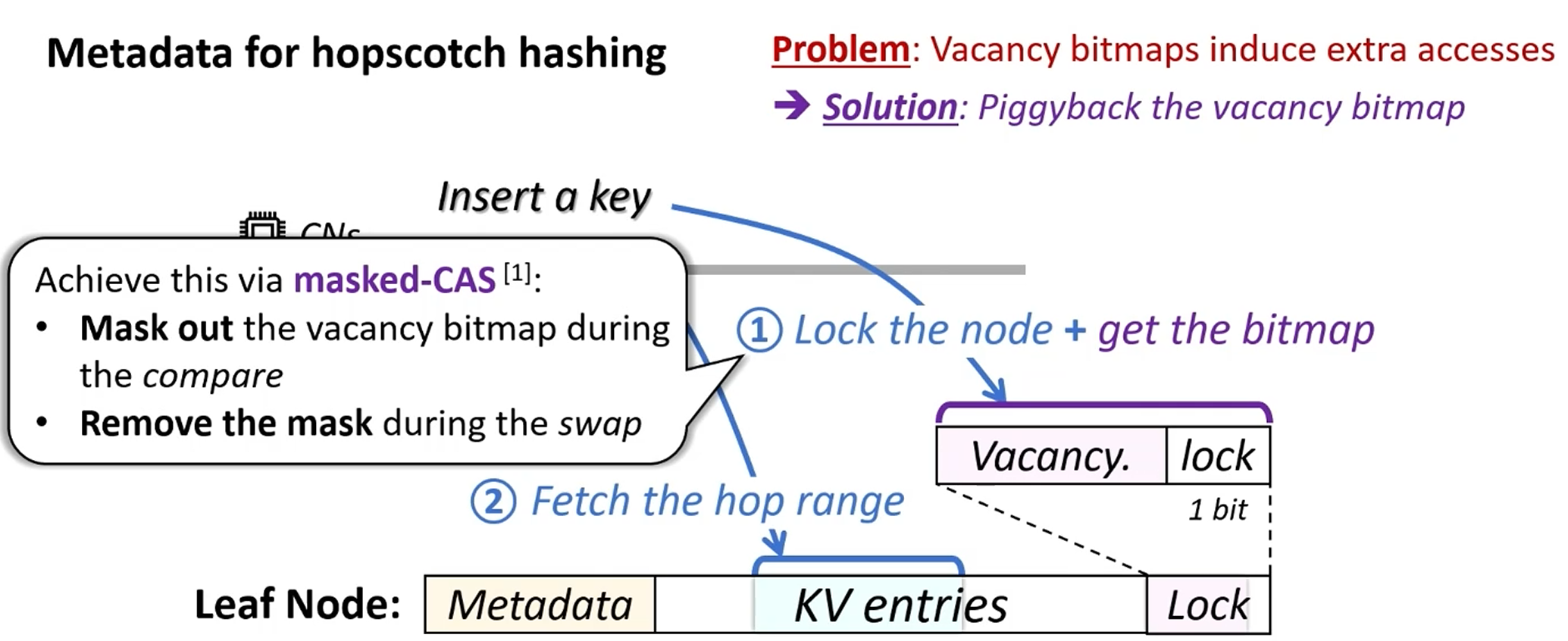
leaf(duplicate)
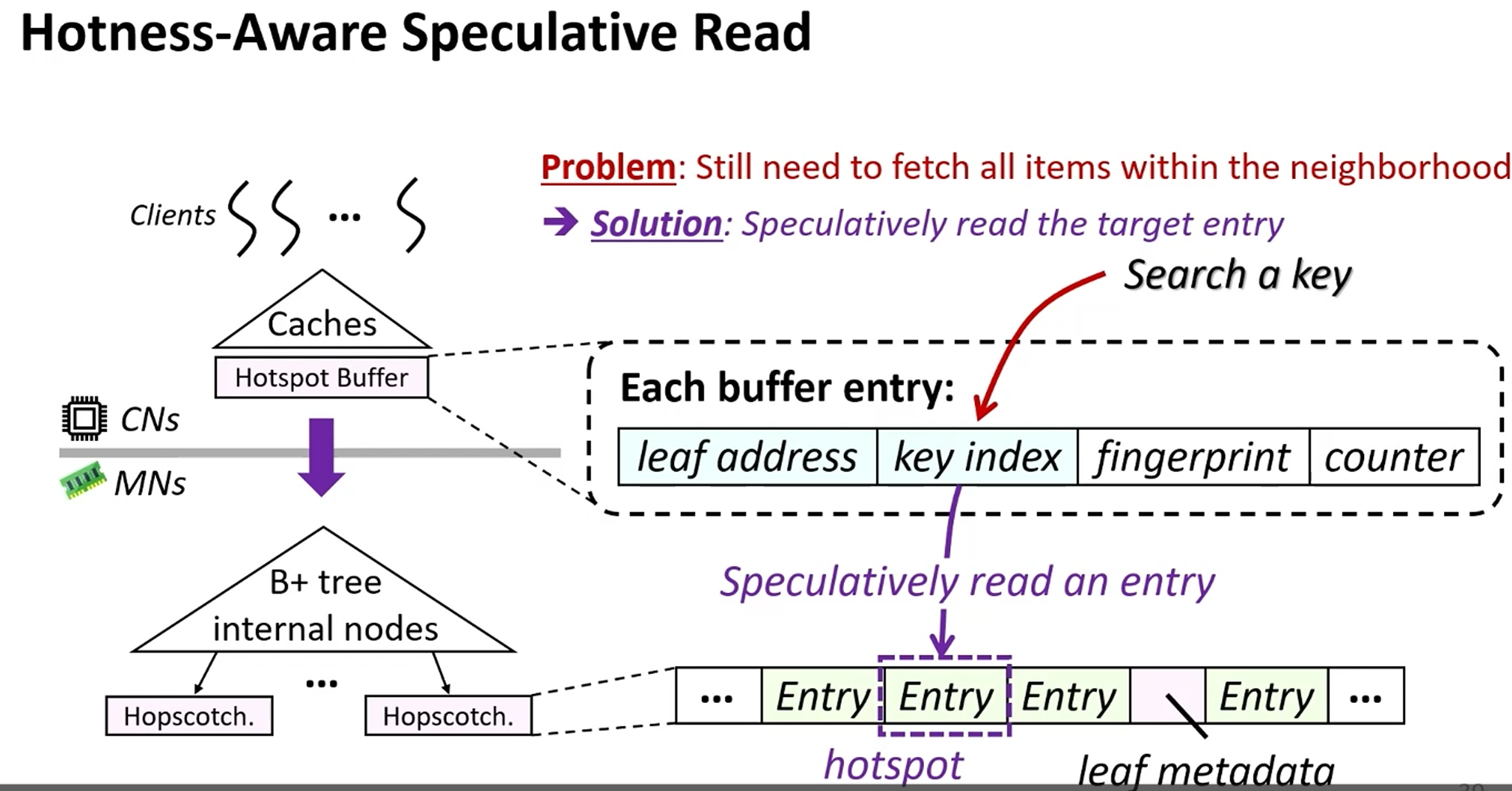
如何进一步减少邻域读放大?(计算端缓存hot index)
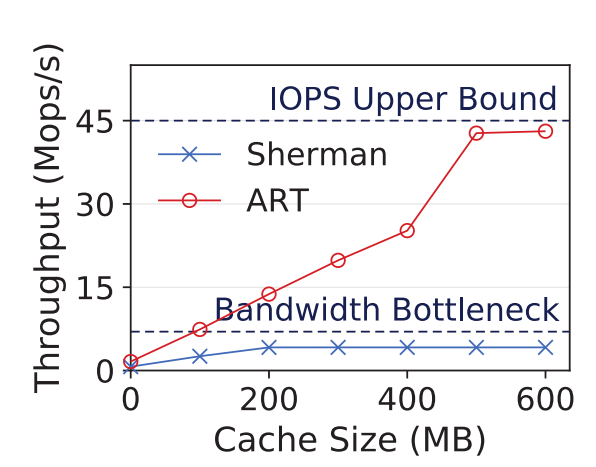
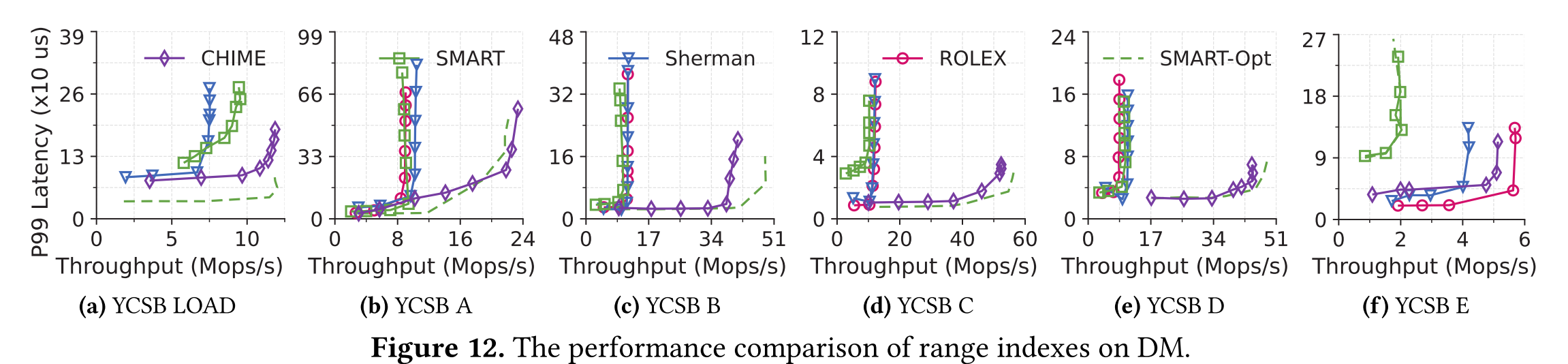
Evaluation

理论最优:无限cache的基数树
Comments
- 个人感觉更多适用于inline情况,也即key和value一起连续存储在叶节点。
- 索引放大更重要还是叶节点放大更重要、cache consumption是否关键,更多还是看use case。
- CHIME对learned index的适配好像比较粗糙。如果结合二者思想,CHIME+learned index(也许更像一种有序哈希表结构)是否有机会做到更好?因为跳房子哈希,似乎也保障了一个“有限误差范围”(邻域)