具体实验流程请见实验流程记录,本文仅作为一个简单的省流和导读。
我当初的实验代码请见github,貌似做完了看到它改版略多()
关键词:ChCore,微内核,OS Lab,capability细粒度访问控制(包括cap group、面向对象设计,这个确实相比于syscall灵活不少)、service之间隔离
内核启动及内存管理
相关实验:Lab0、Lab1、Lab2
ChCore基于ARMv8架构,采用buddy system+slab管理物理内存,采用了四级虚拟地址映射。这部分内容都纯粹在内核态实现,跟宏内核没啥区别。
Discussion:HM将MM移到用户态实现了,ChCore还是纯纯在内核态。不过值得一提的是,本届OS竞赛上SJTU基于ChCore的参赛作品似乎也像sel4那样把虚拟内存分配这一部分移到了用户态实现,之后有精力再拜读一下几位佬的代码。
资源管理
相关实验:Lab2、Lab3
capability
ChCore 微内核采用“Everything is an object”的设计理念,将内核提供给用户的一切资源统一抽象成内核对象(kernel object)。ChCore微内核中共提供了7种类型的内核对象,分别是 cap 组对象(cap_group)、线程对象(thread)、物理内存对象(pmo)、地址空间对象(vmspace)、通信对象(connection 和 notification)、中断对象(irq)。
用户以capability作为标识符,通过系统调用来使用相应的内核对象,举例:
1 | // 内存对象,可以映射后通过虚拟地址读写,也可以直接读写 |
用户态也可以授权、转移和收回capability:
1 | int usys_revoke_cap(cap_t obj_cap, bool revoke_copy); |
Discussion:用户需要借由syscall访问内核对象,而隔壁HM的memory manager移到了用户态实现,所以频繁修改page table之类的内核对象开销还是会非常巨大。HM的解决方法貌似是直接简单粗暴把内核对象的信息给映射出去,user根据权限直接读写就行了。
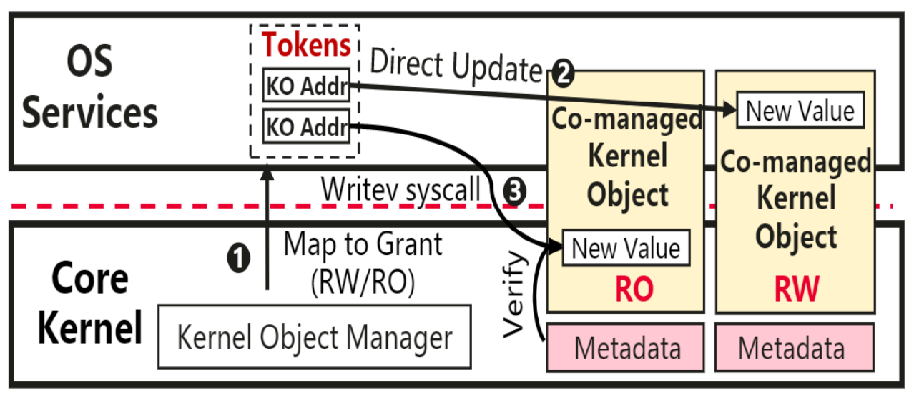
ChCore的mm相当于还是在内核态实现,并且还支持了部分内核对象的数据直接映射(如PMO),所以感觉这个问题影响不大。
cap group
不同于隔壁Linux还是存在进程这个概念的(比如task_struct结构体既可以表示进程也可以表示线程),ChCore干脆把线程和进程切割了。进程变成了一个capability group,字如其名就是一个存储所有capability集合的东西,而线程则是真正的具有调度实体的执行逻辑的东西。当我们launch一个进程的时候,我们会读取其对应ELF可执行文件进行vmspace的初始化,并且为其创造一个main thread调度运行主要逻辑。
线程调度
这部分也跟宏内核是差不多的,ChCore也是比较现代地采取了一个schedule class和schedule entity的结构。
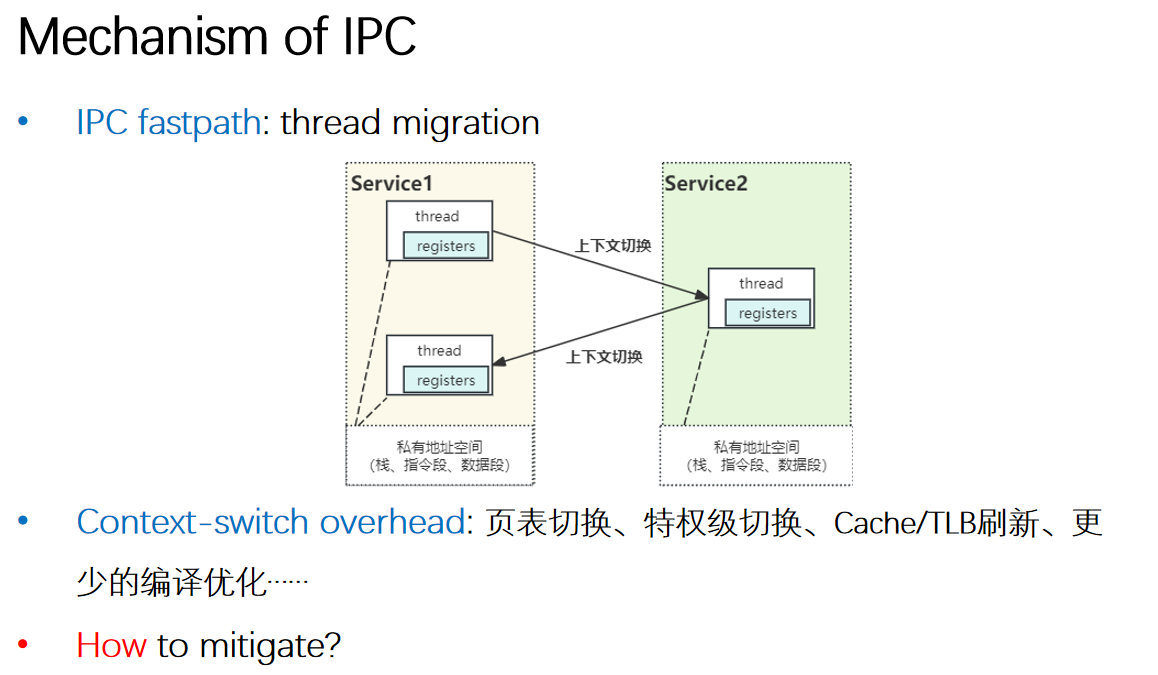
IPC通信
相关实验:Lab4 Part3、Lab5 Part1
这部分可以直接去看实验记录原文(Lab4: 多核调度与IPC——进程IPC通信)。
Discussion:
线程池
ChCore的server handler没有实现线程池结构,而是即用即建。不过它也做了跟HM类似的优化。HM为了防止OOM发生和使内存分配更高效,令每个thread在创建时就提前绑定频繁使用的system service的栈空间,并且伴之以经典的动态扩容stack pool。ChCore让每个thread与频繁使用的system service(虽然chcore也就这几个service)的连接一对一绑定,而非同一cap group的多个thread共享同一个IPC连接,从而提高效率。
IPC性能调优
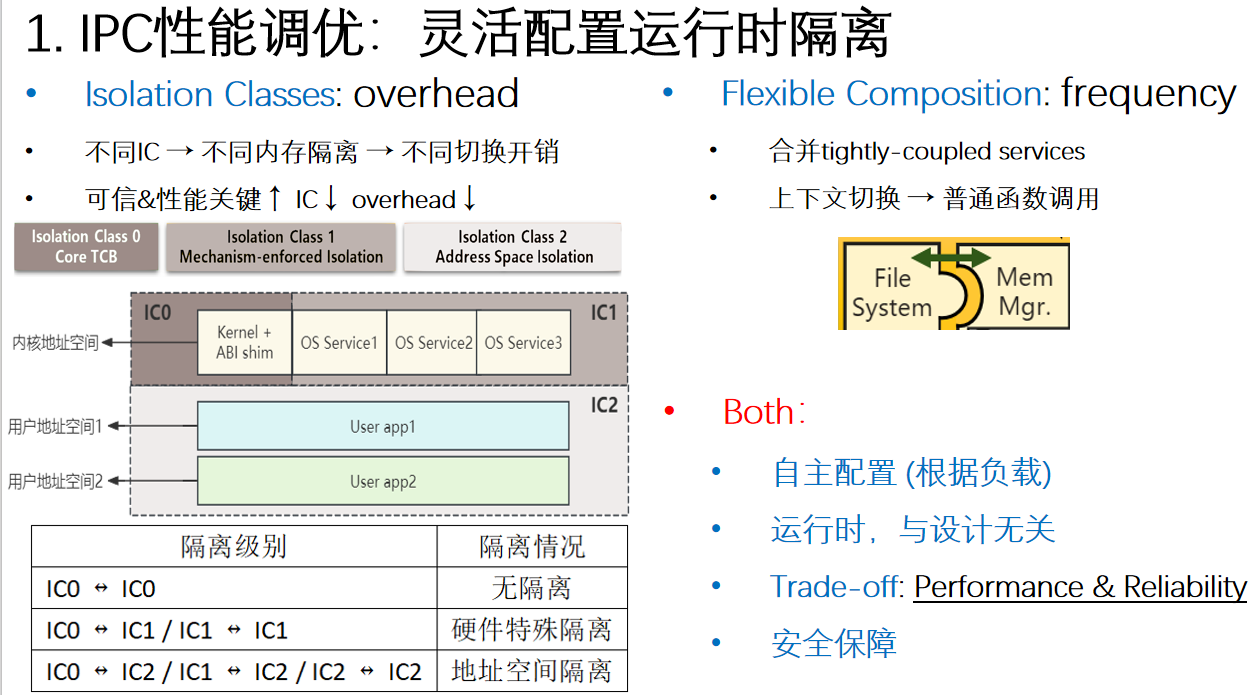
总结
Discussion:感觉挺多地方两种架构设计理念是差不多的,比如说Linux一些模块的面向对象设计;再比如说虚拟文件系统(proc kobject etc.)可以把内核数据暴露给用户态,通过fd可以IO重定向访问内核对象数据,从而不再仅使用syscall API这么死板,这其实就跟这个capability没什么差别了。还有比如说kernel module,比如说各种各样用户态OS,比如说Linux的模块化编译定制裁剪,再比如说HM的隔离级别,两者其实都在互相吸纳对方架构设计的优点,并且各有各的应用场景不同。我目前还是认为数据中心等scalibility要求高的场景还是用宏内核(Linux or专用OS)比较OK,在偏嵌入式的场景还是微内核或者混合架构的专用RTOS看起来更有前途一些。