Capping
测试做得很友好很完善
对stream进行分段为segment;限制每个版本的容器数(主要是指引用的旧容器数);将那些包含重复块rate较小的容器所包含的重复块视为unique block进行rewrite。
HAR
sparse container和out-of-order container;连续备份间sparse container有继承趋势;每次重写所有继承的sparse container,并且维护当前的sparse container列表以供下次备份参考。
TODO
SMR
Improving Restore Performance in Deduplication Systems via a Cost-Efficient Rewriting Scheme
在去重时选择容器这个问题可以建模为一个NP的算法问题:(或者说Restoration,由于是反过程所以感觉原理也比较相似)
Input: n个等长集合;数组target【container、recipe】
Output: 并集包含target中所有数字的最少集合【selected restore containers】
Capping事实上就相当于进行了一个妥协,将该问题转化为:
Input: n个等长集合;数组target【container、recipe】
Output: 选择集合中target比率最大的T个集合【selected restore containers】
之前刚入门deduplication system,在看代码的时候,就在想对capping的处理是不是有点暴力了。具体来说,在Capping中,这个块是很多个容器都有,我们每次都默认选择第一个容器来作为这个chunk的index,也即只视第一个容器的chunk为referenced chunks,其它都为仅被引用一次的redundant chunks。而这有时候并不是最优解,因为有可能选同样包含该chunk的其它容器是最优解,也即它们事实上利用比率最大,但是里面部分chunk被视为了redundant而非referenced chunk。
本篇文章也正是针对该问题提出。它认为,Capping会产生这个问题是因为它依据了index来进行容器利用率的检测,但其实完全没必要这么做。故而,它提出采用容器之间的差异性来作为指标。
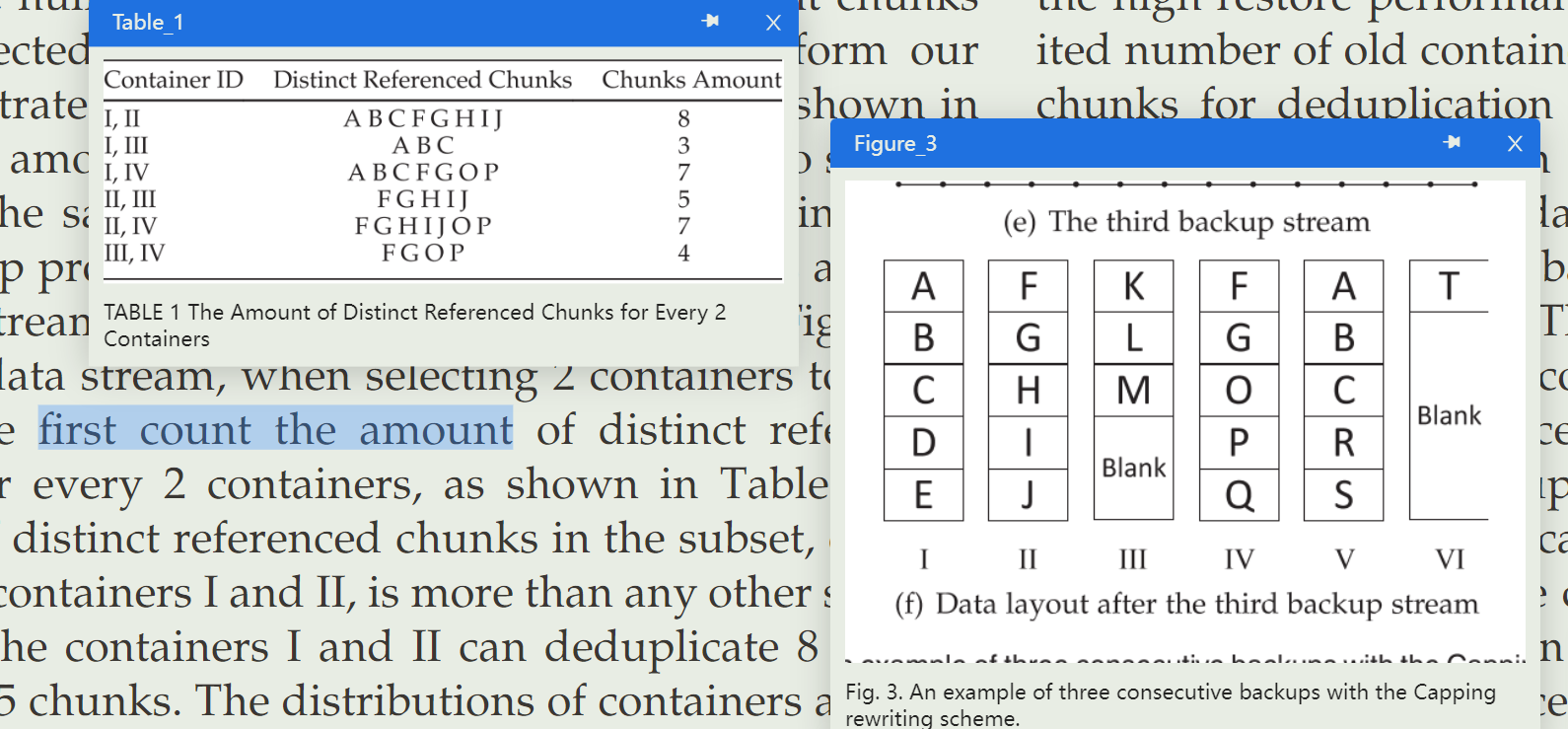
也即,它将问题转化为了:
Input: n个集合;
Output: 并集包含的数字最多的T个集合
然后只对这个选出来的集合id的容器进行去重,别的都重写。这样一来,它就能够使容器利用率相比于Capping大大增加,重写数大大减少,效果一流。
不过这个问题依然还是一个NP问题,故而它使用了贪心算法来进一步解决这个问题:每次从容器全集中选出一个跟当前smr集合不一样的chunk最多的容器。

补充:贪心算法可解的证明
求解任何单调子模性函数的最大值,都可以用贪心算法来取得一个质量不错的近似解。于是它的思路就是证明这个是单调子模函数即可



它最后还提出了一个GSMR,依据备份版本之间的特性进行的重写,感觉跟MFDedup的NDF很像,很神奇,后者多加了个更主要的布局整理的第二步。
DePFC
介绍
大概是说发现了一部分persistent fragment chunk,这些块会一直被重写。具体来说,它关注的是这样的情形。在Deduplication System中,数据流都是以tar形式输入的。而tar的打包方式大概是会给每个文件安上一个metadata block前缀,后面再跟数据块一样,所以最终会是metadata和数据混合存储,并且一般情况下,都是metadata变化较频繁(比如说时间戳变化之类的),数据块变化较为少。而对于小文件较多的场景,这时候就是一个容器中含有很多metadata和少部分data block,如果数据块是持久不变的,由于这个metadata经常变化(unique),导致目前的Rewriting方案都会觉得这个对应的容器的利用率很低,并且加上不会更新index,从而就会导致这个chunk一直被重写,就称这样的chunk为PFC。
这点其实也是审稿意见中提到的吧,文件间(或者说chunk间)访问频率不固定,不过NACC的做法倒是均等化了每一个chunk的出现几率
故而,本篇文章提出的思路是,在协作的其它rewriting算法选举出重写块之后,再进一步对重写块分类,分为PFC(persistent fragment chunk) 和 RFC(regular fragment chunk),然后后者普通重写,前者放在一起重写,并且更新fp index指向最新重写块。
其中,identify RFC and PFC是这么实现的,维护上一个备份版本的rewritten set。如果FC在其中,则为PFC(被重写过了一次);否则为RFC,加入本次版本的rewritten index。
然后,这个过程就会有两个比较关键的点:
Limited Scope to Compute the Container’s Utilization
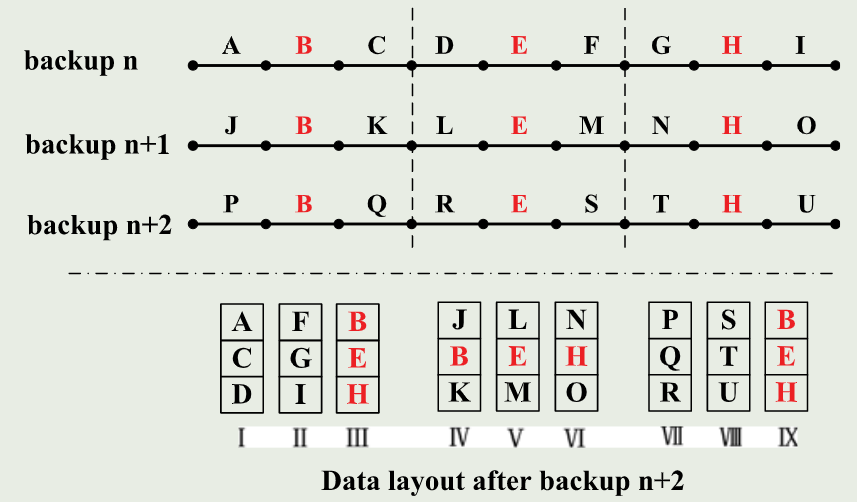
在对于Capping协作这种情况会导致该方法失效……
解决方法是引入一个FCBuffer。具体来说,这个FCBuffer是一个跨segment的数据结构,FC首先被写入FCBuffer,并且实时监测FCBuffer中的各个container的利用率,若利用率达到阈值,就移除FCBuffer中该container对应的所有数据块(因为这说明这些数据块已经被depfc过了)。然后当FCBuffer满的时候再写入新容器。
Restore Cache Thrashing
PFC之间可能间隔很远,特别第一点的FCBuffer带来的PFC和RFC混合存储可能会worsen这一点(毕竟本来RFC就是为了大局起见重写的,把他们集中放置反而可能让PFC之后又面临那个问题了),导致RFC一直滞留更是G。为了防范这点,它引入了一个LRU cache来模拟Restoration阶段,当一个container被驱逐时,就可能说明它里面含有的RFC和当前FCBuffer内所有PFC马上要离当前的context太远了,于是就赶紧写入它对应的所有RFC,以及FCBuffer中所有的PFC。这样一来就能改善距离过远的问题。
这一点我其实觉得有点费解,虽然说直观上觉得是对的,但是理性上还是很难说服自己,实在没怎么看懂。
整个算法流程如下图所示:

我看这篇文章,其实是想在当前代码框架尝试着去复现它的。然而,当前的代码框架是一个顺序写入recipe和block的逻辑,貌似不大支持有的chunk可能得在下一个segment的时候才能被确定recipe中的容器位置,我能想到的唯一解决方法是先把这些视为duplicate,等到最后整个dedup完成(所有segment输入完毕)的时候再统一进行一次recipe的更新,不过实现代价可能有点大所以暂时没敢动。
不过想了想,如果是结合HAR实现的话,可能不一定会这么复杂。首先得知道为什么HAR的话PFC是每隔两个版本才被重写一次,因为你刚重写完的那个版本中PFC所在容器肯定不是sparse的吧,所以下一个版本自然也不会认定其为herite然后重写。因此,我们就需要的是根据相隔版本来构造RCrecent。而且值得注意的是,HAR检测需要重写的块是通过一个global的视角来实现的,只要对应容器是herite的那么它就是需要重写的,因此就不用考虑什么FCBuffer这种现象,更进一步的也不用啥LRU cache了,这个可以通过恢复时采用OPT算法或者更大的缓存来实现。具体来说,逻辑大概是这样:
如果chunk所在cid ∉ sparse herite
去重or重写
如果chunk所在cid ∈ sparse herite
- 如果chunk在上上个版本的RCrecent PFC
- 不在 PFC
代码实现
DePFC的代码感觉比别的两个要复杂,这里也暂且放个我的DePFC + Capping的代码实现吧,虽然最后发现还是不大行(指跟现有代码框架不大兼容,但感觉逻辑一类还是差不多),虽然未经debug,感觉也是可供参考。下面的代码暂没更新fp index,只是基本逻辑框架。
TODO,之后有时间继续完善下吧
1 | /* |
1 | /* Data Structure */ |
1 | // DePFC |
1 | // baseChunkPositions中是Capping分类出的FC |
1 | // DePFC |
其他
They propose DePFC that identifies and groups PFCs to increase the utilization of containers storing PFCs, making grouped PFCs no longer fragmented. However, DePFC fails to remove redundant data among similar chunks holding metadata blocks.
与之相关的是他们团队ICCD’21的另一篇文章,A High-performance Post-deduplication Delta Compression Scheme for Packed Datasets,利用了通过PFC来发现metadata block,然后对其进行内部的delta compression。
Comparison
正好一次性读了两篇文章,就来稍微想一下对比吧。我感觉相比DePFC,还是SMR的应用范围可能更广一些,毕竟DePFC可能只在巨多小文件的时候,效果才会出奇的好,平时感觉可能就比一般重写好些。SMR的话,可能还是有一个情况比较受限,比如说一个极端情况,target中正巧很少包含选举出的container中互异的那些chunk,这种情况下target可能需要被大规模重写。emmm…但感觉这种情况也特别少见,不大懂。
总之,感觉我还是缺少了点看出这些方法有什么缺点的眼力,不过好在看完了也是收获了挺多。过几天再看看两篇文章的evaluation具体都测了什么吧。