Xia W, Jiang H, Feng D, et al. A comprehensive study of the past, present, and future of data deduplication[J]. Proceedings of the IEEE, 2016, 104(9): 1681-1710.
Data Reduction
一开始主要是一步步讲述了Data Deduplication这个概念提出的历程。
Compression
最一开始,都是用的压缩Compression。compression分为lossy和lossless(有损压缩和无损压缩),前者是通过去除一些不必要的信息来不可逆地减少数据大小(如JPEG图片压缩),后者是通过编码或者算术等方法可逆地减少数据大小(如GZIP、LZW等)。由于大规模存储系统(large-scale storage system)主要聚焦于无损压缩,因而下文也主要介绍这个。(deduplication也可以视为无损压缩的一种方法)
entropy encoding
信息熵
提到压缩,就不得不提到信息熵。一个变量X的信息熵可以如下计算:
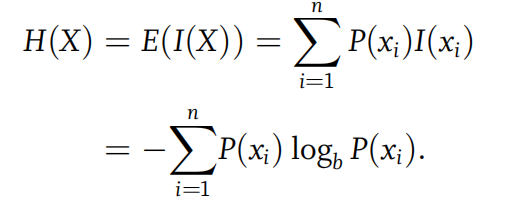
比如说通过字符串abaaacabba,我们可以计算其所构成字母的信息熵:
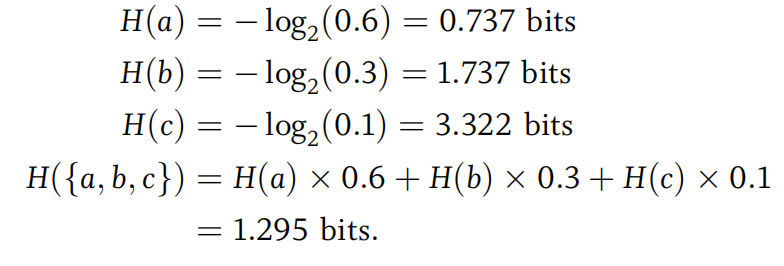
其实际含义是,对于“abaaacabba”这个上下文,{a, b, c}集合的每个字母至少需要1.295个bit来表示,也即字符串“abaaacabba”至少由12.95个bits来表示。也即,信息熵实际上是算出了压缩的极限。
哈夫曼树
早期的压缩理论就是根据信息熵来的,这种我们称为“entropy encoding”或者“statistical-model-based coding”,因为它需要基于某个上下文(statistics)来计算信息熵。最常见的就是哈夫曼树,它用一个frequency-sorted binary tree来生成前缀编码,从而对信息进行压缩。
缺点
然而,显而易见的是这种entropy encoding你首先就得有合适的statistics,这是不scalable的。所以它一般也不适用于现代的storage system的压缩要求。
dictionary-model-based coding
因而,“dictionary-model-based coding”就此浮出水面。它从string-level来识别重复数据,从而简化和加速了压缩。它的主要思想是通过滑动窗口识别重复字符串,并用位置和长度来替代这些重复的。(相当于是unique string只存储一次)代表性的是LZ压缩。
然而,它由于是string-level,所以需要对整个系统的所有string进行扫描,需要在compression ratio和speed之间trade off。
delta compression
它的提出是针对于小文件/相似chunk的。它的思想感觉有点类似密码学,大概是这样:
1 | given file A,B |
目前正在尝试把它纳入到deduplication system中。不过目前的瓶颈似乎是这样的,delta compression是要求要将当前chunk同base chunk进行对比,所以怎么找到base chunk就成了问题。
Deduplication
总之,在compression byte-by-byte识别redundant data这样粒度太小的劣势下,通过计算“cryptographically secure hash-based fingerprints”来识别redundant data的chunk-level的deduplication优势就来了!
Overview
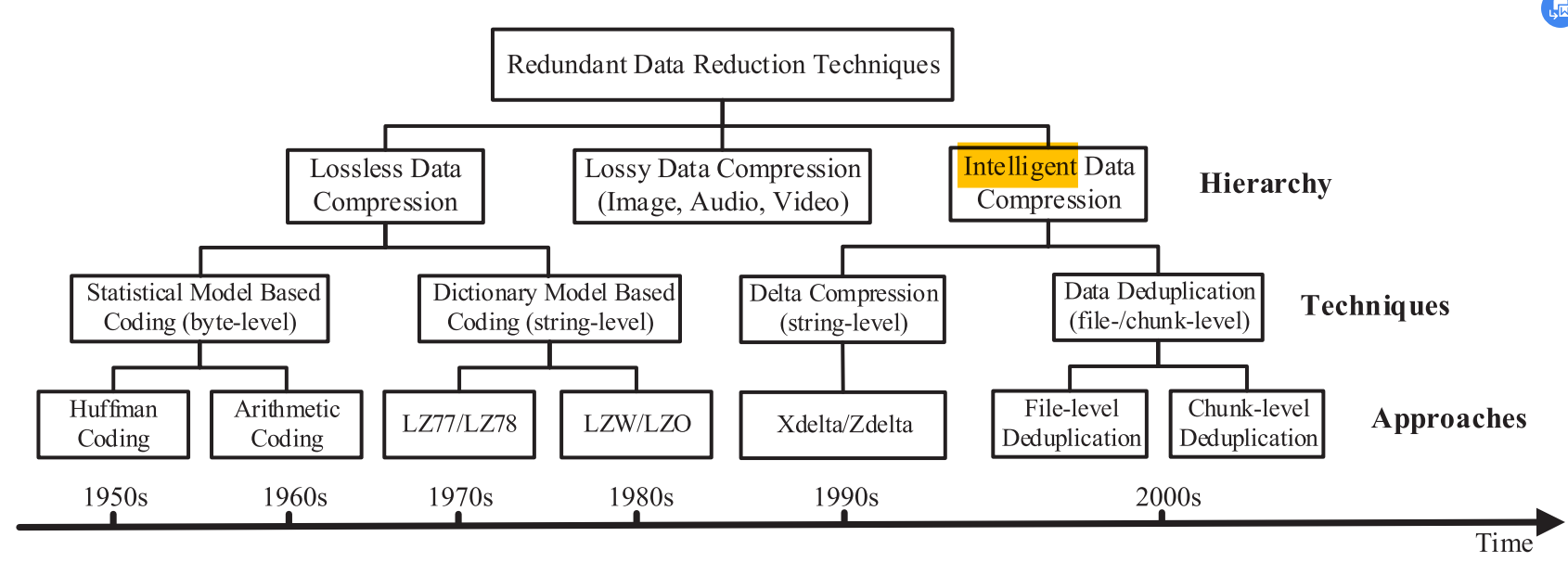
这里也是给了一张很棒的图来总结了上文。
Key Features
这个部分大概是说key features有两个,一个是chunking,另一个是fingerprinting。
chunking有两种方法,fixed-size和variable-size,前者会出现boundary-shift问题,后者更加泛用。
fingerprinting的主流方法还是基于SHA1(现在也用SHA256了)【Cryptographically Secure Hash-Based Fingerprinting】,主要是讨论了它哈希碰撞的可能性很小所以使用安全,还有就是讨论了fingerprint的特性:
很难找到两个不同msg指纹相同
很难从fp倒推出一个msg
Basic Workflow
A typical data deduplication system follows the workflow of:
- chunking
- fingerprinting
- indexing
- further compression
- storage management
- data restore
- garbage collection
- fragment elimination
- reliability
- security
Deduplication
In this section, we examine the state-of-the-art works on data deduplication in sufficient depth to understand their key and distinguishing features.
本节终于要开始对deduplication的关键技术做详尽的介绍和讨论了。
A.Chunking
这部分确实如他所言主要介绍了chunking。它先是介绍了主流的CDC算法Rabin(具体在FastCDC那篇文章介绍过这部分了,这里就不再赘述),然后讲述了Rabin算法的三个主要缺点:chunk size方差大、计算量大、去重检测还不够精确。
针对这三个缺点,分别有各种文献提出了这几类关键技术(顺序与缺点一一对应):
Reducing Chunk Size Variance by Imposing Limits on MAX/MIN Chunk Sizes for CDC
当chunk size过大,虽然会加速后续的indexing等步骤,减少space消耗,但是会影响去重率;chunk size过小,虽然会增加去重率,但是会增大后续indexing等步骤的工作量。这又是一个trade-off。
这里主要介绍了各个主流方法都是怎么限制chunk size的,比如说LBFS简单粗暴,还有别的什么依据极值、非对称滑动窗口等做法。感觉还是FastCDC那个做法更加灵活聪明。
Reducing Computation to Accelerate the Chunking Process
也是有比如说Gear等等算法或者硬件层面上的改进。
Improving Duplicate-Detection Accuracy by Rechunking Nonduplicate Chunks
这个问题也是比较普遍,比如如图所示的C2和C5之间就可以再做进一步去重:
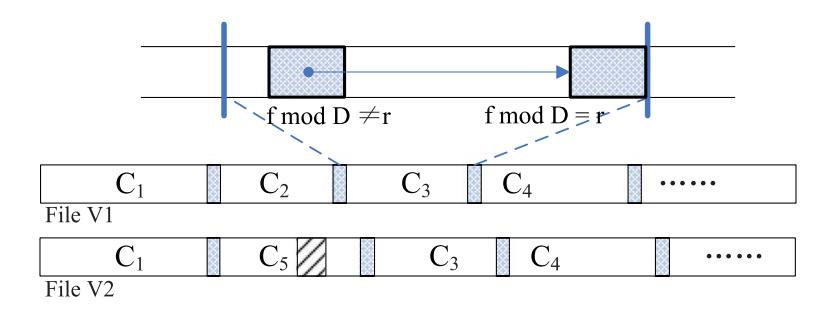
具体方法有比如说频率分析法选定某些频繁访问的chunk进行rechunking、把几个小的nonduplicate chunk给merge为一个大的然后rechunking等等。
这个可能对网络场景也有适用,毕竟网络传输也就主要是通过一个个很小的network package数据包。
Impact of Interspersed Metadata
主要是说如果数据集内meta data和主要数据混在一起可能干扰去重,比如说block header、还有tar打包后产生的文件的包含时间戳等信息的file header等等。
解决方法大概就是预处理之类的。
B. Accelerate Computational Tasks
这个部分大概就是提出了两种方法,一个是通过将deduplication system给pipeline了(就是Odess那个做法),然后再结合multithreading来对它进行多线程加速;另一个就是通过开发GPU相关库来对deduplication做支持,从而使用GPGPU架构来进行硬件加速。

C. Indexing
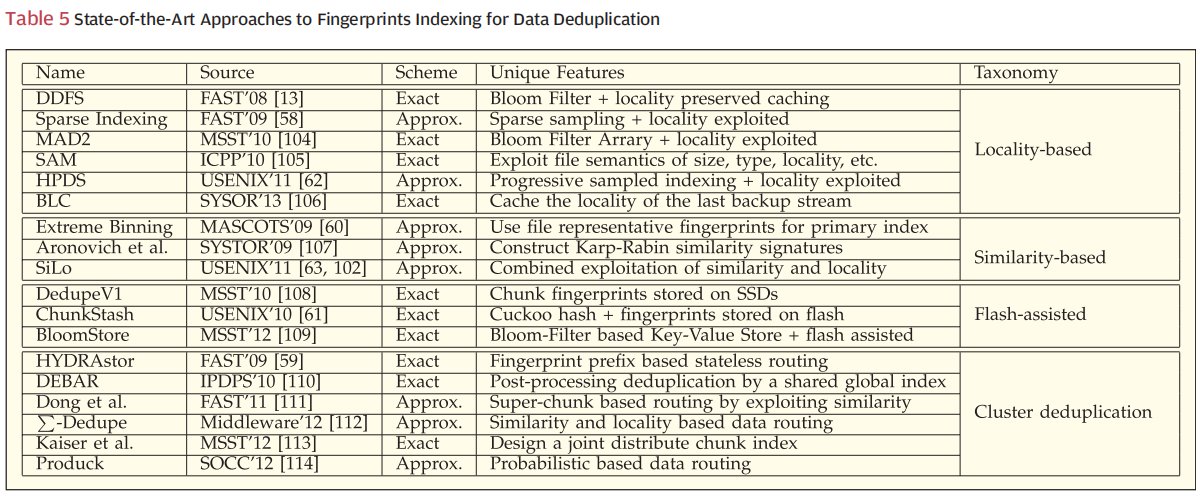
不知道这个indexing是不是就是我们pipeline中的dedup阶段,感觉是的。
这个阶段面临的问题就是,数据量太大,导致指纹量也很大装不进内存,也就是说可能得根据磁盘中的指纹进行快速的索引。
indexing大致有两种思路,一个是精准的indexing,另一个就是命中率较低但内存占用也低的indexing。感觉capping有可能也有点后者的感觉()
然后目前流行的也是有四类方法:locality-based, similarity-based, flash-assisted, and cluster deduplication approaches。
locality-based
大概意思就是说利用数据的局部性,每次要某个指纹不是只读它一个,而是顺带把磁盘中这个指纹后面几个也读进内存,磁盘中的也是按照数据局部性存储的。
除此之外,DDFS结合Bloom filter使用来精准检测重复。
A Bloom filter [22] is a space-efficient data structure that uses a bit array with several independent hash functions to represent membership of a set of items (e.g., fingerprints).
而Sparse indexing则采取“抽样”的方式。
这个一般用于提高performance。
similarity-based
最常见的方法是用一个fp set的最大值or最小值来表示一个file,然后对这个建立一个主索引。如果两个文件的代表fp相同,那么这两个文件很有可能重复读极高。
它这里提到了一个比较值得思考的观点:locality-based是利用了physical-locality,similarity-based是利用了logical-locality。前者还是比较容易理解的,因为它要求磁盘中的指纹按局部性存储,后者我是真没明白。。。之后有兴趣再看看相关论文了解一下吧。
这个一般用于reduce RAM overhead。
flash-assisted
感觉这个没啥特别的,相当于换了个闪存介质而不是磁盘来存储index。
Cluster Deduplication
这个相当于加了层分布式,将输入的数据流分成几个种类(比如说按前缀分)然后送到多个结点上并行地进行去重处理,然后每个结点内部又可以用别的算法了之类的。这就需要涉及到负载均衡、路由算法等等了。
缺点是可能降低deduplication ratio(可能是因为一些路由算法实现?)。
D. Post-Deduplication Compression

不过即便如此,一个chunk内可能还是有一些小地方是dunplicate的(internal redundancy),这时候压缩就大有用处了。并且多个chunk一起压缩,比单个单个压缩的压缩率更高。
这个还适用于上面说到的一种情况,也即那个用到rechunk的地方,完全可以用delta compression来代替,而且感觉后者可能还更通用()感觉被薄纱。
主要面临的挑战来自于这几个方面:resemblance detection, reading base chunks, and delta encoding。
resemblance detection
目前大概有这几种方法:
- Manber:计算polynomial-based fingerprints,两个文件的相似性取决于它们相同的这个fp的数量。
- superfeature:抽样选取一些Rabin fp作为feature,并把它们合起来成为一个大的superfeature,对这个东西进行index。这个好像应用比较广泛。
- TAPER:每个file都是一个bloom filter,比较filter相同的bit位数。
delta encoding
Additional Delta Compression Challenges
E. Data Restore
这里笔墨最多的还是在说碎片化问题,同时也简要介绍了去重系统的三个主要应用场景:primary storage、backup storage、cloud storage,以及碎片化问题给它们的薄弱方面的狠狠一击()
primary storage
它最主要的问题还是IO-sensitive
backup storage
它最主要的问题是随着备份版本增多碎片化问题的愈发严重
cloud storage
它最主要的问题是速度,其受网络带宽、碎片化的限制。
F. Garbage Collection
这部分也大概是讲了GC常见的两种方法,一个是reference count,另一个是mark & sweep。
前者需要inline地维护refcnt,后者则可以offline运行。
并且在backup system中,GC一般是删除了几个备份版本之后的background process。而在primary storage中,GC通常是inline的。