本次先暂时只做个速读了
1
The Logic of Physical Garbage Collection in Deduplicating Storage
这篇文章看起来像是说他提出了两种GC方法,一个是PGC(physical),另一个是LGC(logical),没太看明白。
摘抄
这段话大致介绍了GC的重要性,感觉写得很不错,一些词可以参考一下
Most storage systems that write in a log-structured manner need a mechanism for garbage collection (GC), reclaiming and consolidating space by identifying unused areas on disk. In a deduplicating storage system, GC is complicated by the possibility of numerous references to the same underlying data.Freeing unreferenced space is a basic storage system operation.
determining the liveness of chunks 判断chunk是否应该活着
2
A_Focused_Garbage_Collection_Approach_for_Primary_Deduplicated_Storage_with_Low_Memory_Overhead
概述
大概是提出了一种用于优化GC的Mark&Sweep中的Mark阶段的方法,也即使用一个什么Austere RefGraph。它大概意思就是每次GC可以不针对全部文件,而是只针对那些被删除的文件及其他relative file(含有共享块),从而由此可以把deleted file的chunk分为两种类型:no-shared和shared。所以问题就转化为如何找到一个文件的relative file。然后我们通过refgraph来保存这些相关的meta data。
感觉大体上就是Odess的GC所用的方法,也许OdessGC对其做了一些简化。之后有兴趣可以钻验一下Odess以前的commit,了解一下这个项目是怎么一步步地被开发出来到今天这么庞大的。
不过看起来,好像本文是针对“Primary storage”,也即主存的?emmm,我们的大概是基于disk storage的。这点可能得注意一下。
针对主存的话,很重要的一点就是其CPU占用率、速度等因素。to-disk的话就不一定了。

确实,你说得好啊,我们之前的Odess是针对的backup storage,所以检测一个块能否被删除可以判断其是否“out-of-date”。而针对primary storage的去重只能判断其refcnt和“版本内”重复。相当于backup storage是多个版本比较,这个primary storage是一个版本内比较。体会一下这两种场景的差异性。
同时,我也悟了一点,就是测pmem场景的时候老师为什么要求的是比较那个trace内部的重复率,而不是比较两个trace之间的了。因为pmem也是主存场景(非易失性内存)。那个trace的具体场景应该是存放在内存中的文件系统。所以他的意思是Odess加上这个就可以新概念拓宽数据集了。
我考,这下真悟了,66666我大彻大悟
所以主流的对Mark&sweep的优化都不大适合于primary storage,毕竟它没有什么备份版本,或者什么内存cpu占用率太高了。
而且对于这种primary storage,感觉现在单位不是container了,而是不固定大小的file。比如本篇文章,就是根据file内部chunk的共享信息,来搭建起file之间联系的graph的:
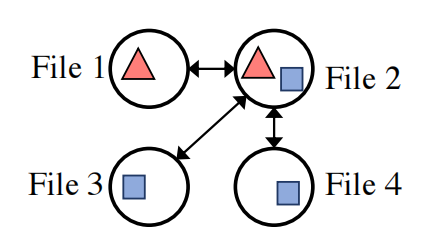
明天估计得根据今天的领悟去重新思考一下老师说的第三个问题了。
这个图画的很帅
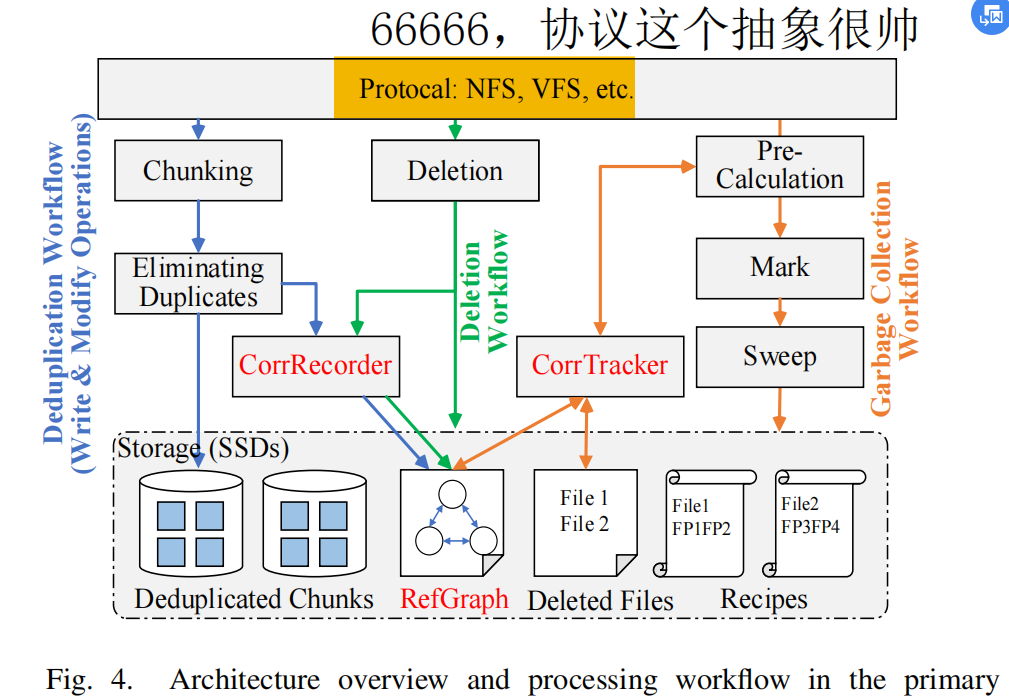
摘抄
reclaim stale chunks in large-scale primary deduplication systems 在大规模的主去重系统中回收陈旧chunk
介绍什么是去重
Data deduplication, which allows files to share their ”common” (i.e., duplicated) data in chunk-level [1], has been used in many use cases, including backup storage [2], [3], data syncing [4], and flash storage [5].
为什么去重会影响GC的性能(这里由于target是主存,所以学习一下语法思路等即可)
Specifically, duplicated chunks will be physically stored only once, and these ”common” chunks in different files will be referenced many times. With the storage data evolution (i.e., caused by file operations), the deduplicated systems are full of active chunks (i.e., still referenced by some files) and stale chunks(i.e., no longer referenced by any file). And GC workflow has to recognize and remove stale chunks by tracking references of all chunks. Considering the number of chunks can be at billion-level in primary storage, GC will be a heavy task(very time- and memory-consuming), and it may lead to system stalls or worse latency, which are critical issues for primary storage.
可以看看related work的A部分。可以看到比较契合我写的部分
可以着重参考一下
总结
看完了全文,现在来提炼一下其大致摘要吧。
本篇文章主要针对对Primary Storage的去重系统中的GC阶段开销大问题,提出了FGC的解决方法。
当前主流最常用的GC方法是Mark & Sweep,但由于它需要在Mark阶段扫描所有的文件来判断一个chunk的liveness,所以它的开销还是非常大。针对此,FGC提出了,无需扫描所有文件。它将删除文件中的chunk分为shared和non-shared两种类型,故而每次Mark阶段理论上只需找出所有shared的chunk,也即只需扫描与删除文件存在共享chunk关系的其他相关文件即可。
故而,我们需要维护一个数据结构,来记录这样的关联关系。顶点为一个文件,两个顶点有边表示两个文件共享了某个chunk。
然而,如果记录这样一个全图是相当耗费空间的,因此又提出了新的优化点:对于每个chunk,我们只需记录当前文件与每个chunk对应的base file之间的引用关系即可,也即一个file至多有chunk数条边。

并且通过统计可得,大部分情况下一个文件通常只对应一个base file就够了。
因而综上所述,这样一来我们就完美减少了GC的Mark阶段所涉及的文件数。它原本需要扫描所有的文件,现在只需要扫描delete file及其related file这几个(大多数情况下就两个)文件就行了。
不过这个RefGraph大小虽然够小了,但是要维护它还是有一定的开销:
- 宏观上,新增graph的边被抽象为无序的异步命令序列;但是删除就需要获取锁。
- 微观上,新增graph的边只需要扫描新文件即可;但是删除就可能需要遍历所有的related file进行graph的重构。
并且,在实际的primary storage场景中,增删改(改可视为增删操作的混合)十分频繁,每次都进行real-time的更新是不现实的。
故此,我们将这个维护graph的步骤,也跟tracker一起放在了GC的pre-calcu阶段。
不过我很好奇,这个听起来很牛逼,为啥只投了个CCFB呢?
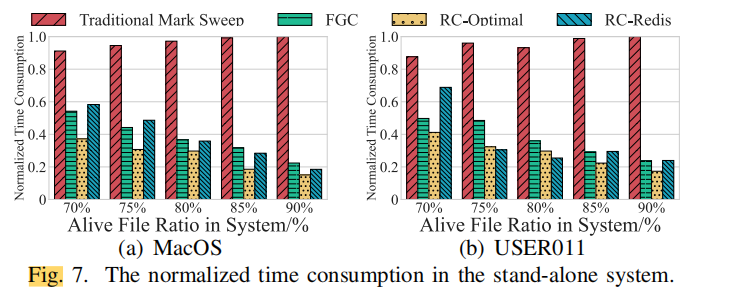
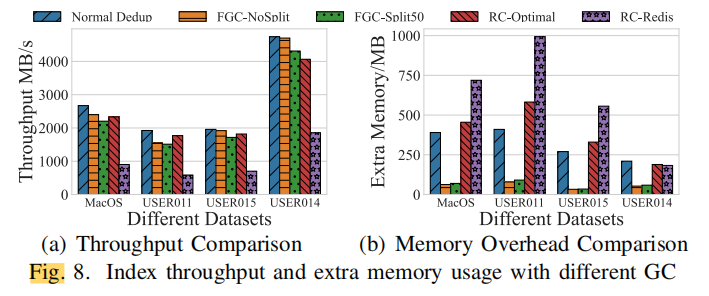
难道是因为速度比不过RC-Optimal吗,但是memory overhead确实挺不错。。。算了,不明白,也许山外山人外人吧。
总之,看下来感觉还是对primary storage这个应用场景有了更进一步的了解,也对GC的整体算法框架有了一定的了解。
不过感觉这篇文章主要聚焦的还是GC过程的效率,而Odess的话应该聚焦的是GC过程对碎片化问题的解决,侧重点还是各有不同。不过感觉Odess应该也是很前沿了,它用的cache-centered的算法应该也是很牛逼的。
感觉还是对所谓“idea”的产生理解比较抽象。也许都是初步有个雏形,知道这个方面暂时前沿还没有人做过,然后慢慢开始增加新的point的吧。。。所以最关键还是要先对这个领域的研究现状有一个全面完整的了解。加油吧只能说,还得是沉淀!