读题
FastCDC: a Fast and Efficient Content-Defined Chunking Approach for Data Deduplication
首先还是一如既往见题知义环节。名字很简明,就是一个高效的按内容分块技术,用于dedup。
回忆一下按内容分块,大抵就是什么哈希值什么玩意的(说实话一点不懂),还需要界定分块范围。不过我感觉哈希技术应该都比较固定,所以我觉得这篇文章可能更聚焦于如何界定分块边界,比如有没有用什么滑动窗口算法?之类的。具体着实是不大明白,所以这篇论文的background部分也得好好研究。
Abstract
CDC:Content-Defined Chunking 按内容分块
以前的CDC【目前的大boss,Gear-based CDC】:一个字节一个字节地计算rolling hash从而划分chunk point,CPU占用率高。
解决方法:
simplifying and enhancing the hash judgment 简化并且增强hash judgment
解决CPU占用率高问题
skipping sub-minimum chunk cut-point 跳过次小chunk cut-point
进一步加速
normalizing the chunk-size distribution in a small specified region 让chunk size分布更密集
解决了由于cut-point跳跃而导致的deduplication radio降低的问题
Introduction
deduplication通过加密安全哈希签名【cryptographically secure hash signatures (e.g., SHA1 fingerprint)】标识重复内容。
chunk-level > file-level,因为其粒度更细。
常见chunk分类:FDC、CDC(解决boundary-shift problem)。
CDC经典通过Rabin fingerprint来解决探查边界问题,有效但是time-consuming;
因而有替代hash算法:Gear,SampeByte,AE
一般来说CDC分为两个阶段:
hashing
生成fp
hashing judgment
将生成的fp与given value对比从而确定chunk的cut-point
observation
Gear-based CDC,快,但是low deduplication radio,因为在hashing judgment阶段滑动窗口太小
hashing judgment阶段成为新的性能瓶颈,因为Gear的hash阶段已经够快了
predefined的最小chunk size(一般用于防止生成一丝丝小的chunk)能被用于CDC的cut-point skipping(跳过cut-point,也即对该region取消CDC的使用)。
如果放大该大小,可以加速chunking【很容易理解,因为跳过的变多了就不用chunk了】,但是会降低deduplication radio【也很容易理解,因为跳过了就无视了一些重复块】。
由1、2,我们提出 enhancing and simplifying the hash judgment来减少CPU开销,加速Gear-based CDC。
针对3,我们提出 a novel normalized Content-Defined Chunking scheme, 也即normalized chunking,来让chunk size分布更密集。
三个关键技术
Simplified but enhanced hash judgment
增大Gear算法hashing judgment stage的滑动窗口大小,by padding several zero bits into the mask value for the hash-judging statement of the CDC algorithm.
通过此,成功使Gear达到Rabin那样的去重率。
更深简化优化hashing judgment stage
通过此,降低CPU占用率
Sub-minimum chunk cut-point skipping
我们通过normalized chunking来达到扩大minimum chunk size,加速chunking的同时,又保持deduplication radio不会太菜。
normalized chunking:By selectively changing the number of mask bits ‘1’ in the hash-judging statement of CDC.
【想了想确实,因为chunk的最小size越大,那么chunking越快。如果块集中分布在某个区域,那不就是可以“扩大minimum size”了(对正态分布外的那堆丝丝跳过),就可以加速chunking。
我们就需要知道它这个集中分布到底是怎么做的,为什么在hashing judgment阶段做那个就可以规范,这估计需要来点background或者等下看看真实的代码了】
这样一来,我们就可以:
- reduce big chunk size:增加去重比(因为相当于小于最小size的部分变少了)
- add cut-point skipping technique:可以运用这个玩意从而增加chunking速率了
Background
CDC一般都是使用滑动窗口来计算hash值,当哈希值满足某种条件时,我们就把滑动窗口对应的这个数据块作为一个chunk进行切割。
rolling hash:能以迭代方式进行计算的hash算法。这也跟滑动窗口的思想很吻合
Rabin Hash的定义式:

如果滑动窗口hash值的最低log2D位与阈值r匹配,也即
fp mod D = r,则当前位置被标记为块切点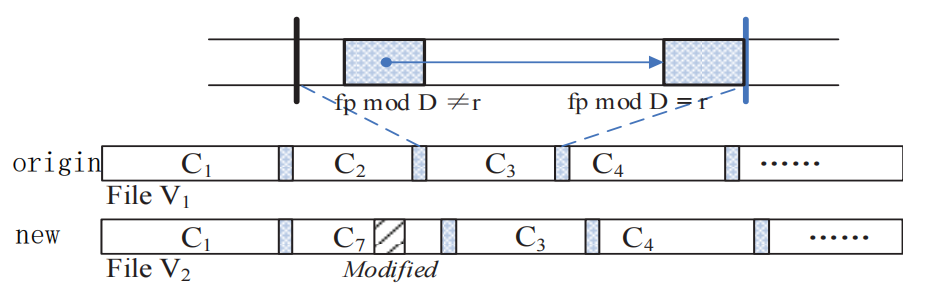
如图所示,计算得C7的fp不满足条件,故而C7不算是一个cut-point,而C3的可以。
由于Rabin hash是byte-by-byte,所以效率较低。解决方法:
算法加速
Gear、AE、SampleByte。具体算法是怎么做的详见文章。
硬件加速
还有提到了一个很有意思的点:typical data deduplication system workflow
chunking
fingerprinting
computes the cryptographically secure hash signatures(e.g., SHA1) of data chunks
在具体实现中感觉这玩意应该可以跟chunking合起来使用?好像不行,看看Odess怎么做的
【其实有一点还不大明白,就是fp的生成算法和chunking中的hash算法一样吗?有待观察】
indexing
identifying the identical fingerprints for checking duplicate chunks
识别指纹,从而进行重复块检测
storage management
指non-deduplicated chunks及其meta data的存储、可能的deduplication后的后处理,为了为之后的去碎片化、压缩、可靠性、安全性服务。
【这个是不是就有点豁然开朗了?咱们之前研究的各种data layout、rewrite什么什么的,其本质上就是通过修改改善storage system的meta data,以及进行一些去重后处理,从而达到去碎片化效果的。感觉它这个概括是真的很精炼,让我对storage system的全貌有了更深的理解。】
Observation and Motivation
Gear Hash
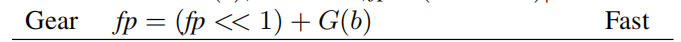
通过两个关键方法使生成的哈希值均匀分布。
映射
每个字节都映射为一个64位的整数值,也即图中的G函数。也即G大致定义为:
uint64_t G[256]运算
通过“+”将滑动窗口最新一个byte加入哈希信息,通过“<<”将滑动窗口最旧一个byte剥离出哈希信息。
这里也可以形象化理解。滑动窗口的哈希值事实上保留的是许多最近版本的信息值。每次左移,都会剥离掉旧版本的一部分信息【别忘了都是64位,所以还有一部分信息存留在保留的哈希值中】,而每次+,就会加入新版本的信息。故而,一个字节的信息生命周期为8次滑动窗口移动。可见,它可以同时保留有用的、一部分生命周期的新旧版本信息,体现了其Content-Defined的思想。
也因它每8次扔掉一次信息,所以它可能不大准确,开销较大的Rabin rolling看起来还再度利用了扔掉的a的消息,所以虽然开销较大,但是去重率较高:(N是滑动窗口大小)
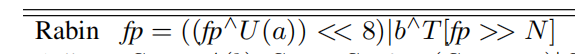
虽然感觉水平还是不够,不大懂究竟为什么uniform了。。。
Design and Implementation
Optimizing Hash Judgment
感觉还挺期待。回忆一下hash judgment是啥过程来着?是根据当前滑动窗口内的哈希值,还有这个经典模运算: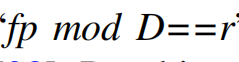 ,来确定cut-point。而hash judgment之所以产生性能瓶颈,有一个原因是因为滑动窗口太小了,所以我们需要增大窗口大小。但是窗口大小与mask比特数恒等【mask就是这个mod的D的2的幂数吧】,所以我们也需要改变mask。那么怎么改变呢?下面将给出答案。
,来确定cut-point。而hash judgment之所以产生性能瓶颈,有一个原因是因为滑动窗口太小了,所以我们需要增大窗口大小。但是窗口大小与mask比特数恒等【mask就是这个mod的D的2的幂数吧】,所以我们也需要改变mask。那么怎么改变呢?下面将给出答案。
Enlarging the sliding window size by zero padding
这里首先是一针见血给出了那个模式子的形象理解:低比特位决定cut-point。
a certain number of the lowest bits of the fingerprint are used to declare the chunk cut-point
mask的大小也就是D的幂数,Gear hash的特性决定滑动窗口大小必须跟mask大小一样。
说实话没太看懂为什么。。。这俩图都没看懂
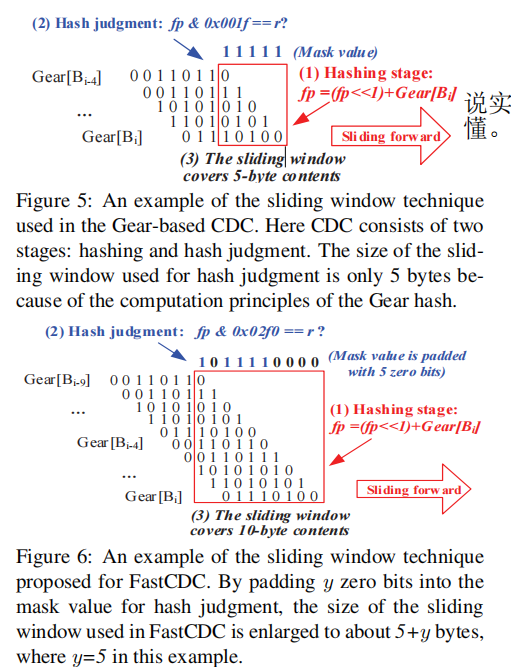
Simplifying the hash judgment to accelerate CDC
反正意思就是不用模运算了,也不用跟r比了,还是没看懂。。。
Cut-point Skipping
这一节主要是介绍了下cut-point skipping。
Rabin-hash的chunk size分布:
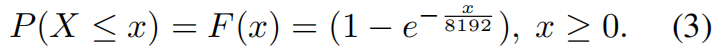
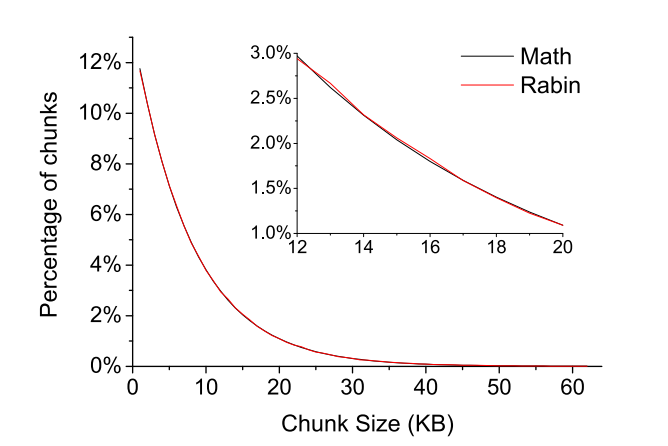
可以看到跟我们理想中的正态分布不一样,很大一部分(22%)为小于minimum size的chunk,导致skip增加,去重率降低。
skip对judgment的增速
可以通过几个方面理解:
- skip事实上增大了chunk的平均大小,增加的大小等于minimum chunk size
- skip可以免去一些judgment计算
这两点原因其实本质比较重合,但是考虑角度不同。
Normalized Chunking
感觉最牛逼的还是这个,主要实在想不通均匀分块是怎么做到的,因为不是content-based不
它好像操作是selectively change the number of effective mask bits ,也就是改那个模数D
For the traditional CDC approach with expected chunk size of 8KB (i.e., 213), 13 effective mask bits are used for hash judgment (e.g., *fp & 0x1fff==*r). 一般情况,都只用13位mask
For normal ized chunking, more than 13 effective mask bits are used for hash judgment (e.g., *fp & 0x7fff==*r) when the current chunking position is smaller than 8KB, which makes it harder to generate chunks of size smaller than 8KB.
我们是会根据情况看用多少位mask,如果当前chunk太小就多用几位(相当于分块条件严苛了),太大了就少用几位(从而更容易生成大chunk),这样就能限制小chunk数量和大chunk数量。
这里有一点需要理解一下。多用几位限制小chunk数量可以理解,那为什么少用几位可以限制大chunk数量呢?
试想一下,大chunk是怎么形成的。是因为条件太严苛,所以得很久很久之后才有一个cut-point。
因而,小chunk是因为条件太松,大chunk是因为条件太严苛,所以我们对小chunk多用几位,对大chunk少用几位即可。
很好,感觉这也许就是一种adaptive(高情商)怪不得在提出COS那个自适应时夏老师说很常见,原来是使过了这个招hhhh
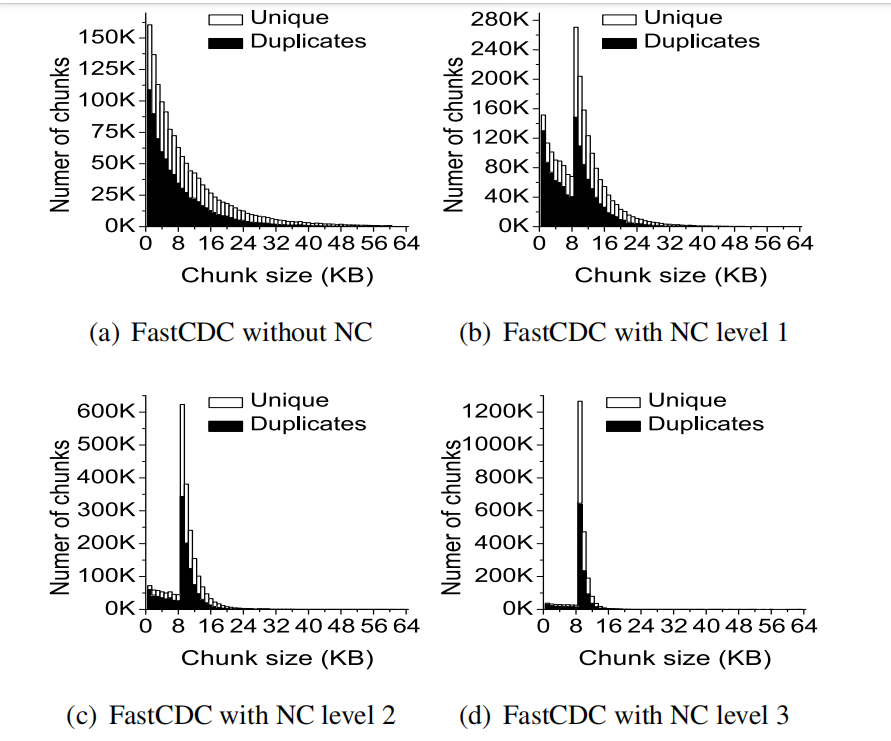
这样一来,与skip结合,既使得小chunk少致使去重率不会太低,又使得我们可以扩大minimum size的大小(所有块更加紧凑,自然最小块大小也就变大向中间靠拢了)
值得注意的是,最高level的FastCDC其实就相当于FSC(固定大小分块技术)。
【感觉这个思想很有意思,果然做什么都是要中庸之道,永远是结合两者的才是永远的神()这里相当于从分布上使用了中庸之道。】
altogether

Evaluation
性能评估是分别针对这三个优化点进行分析的。
Hash Judgment
对于第一个优化点hash-judge,我们重点比较的指标是chunking的速度和去重率,并且比较的是它跟其他几种去重算法的对应指标。这也是很显然的,因为hash-judge主要影响的是生成的块的大小和准确率,前者影响速度,后者影响去重率。
chunking速率我们合并统计了hash阶段和hash-judge阶段。
Gear算法hash快但judge慢,Rabin算法hash慢但judge快,FastCDC充分结合二者优点。
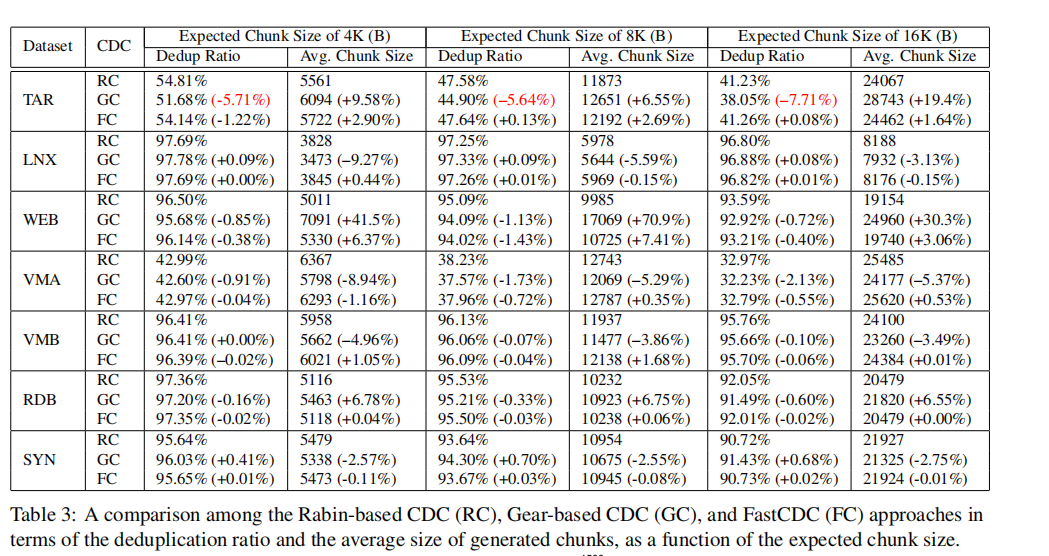
去重率也是列了张很清晰的表,感觉可以学习一下它这个表画的:
cut-point skipping
它主要比较的是FastCDC自身在不同Min-ChunkSize之间的chunking speed、去重率以及平均chunk大小,相当于起一个调参的启发性作用。
一个值得注意的点是,它这里强调了:
For the metric of the average generated chunk size in FastCDC, it is approximately equal to the summation of the expected chunk size and the applied minimum chunk size.
FastCDC生成的平均chunk大小为expected chunk + minimum chunk。