标题
**The Dilemma between Deduplication and Locality: Can Both be Achieved? ** 重复数据删除和数据局部性之间的困境:两者都能实现吗?
重复数据删除:deduplication,是一种用于压缩去重的常见方法,经常采用虚拟指针法。
一个硬盘中的文件往往会随着时间推移拥有多个备份,去重就是针对这些备份之间的概念。我们采用对每个chunk(通过fingerprint标识)进行引用的方法进行去重(虚拟指针法),但这会导致严重的碎片化(也即丧失数据局部性)和GC性能的问题。
数据局部性:
- 程序访问数据有局部性,因而备份数据之间也有局部性。
- 如果在restore时采用顺序访问,那么相邻两个数据块之间就产生了数据局部性。
本文聚焦于对硬盘进行备份过程中的去重压缩( deduplication on hard drive systems),提出了基于Neighbor-Duplicate-Focus indexing(NDF) and Across-Version-Aware Reorganization scheme(AVAR)两项技术、兼得数据去重和保持数据局部性两个优点的去重压缩框架MFDedup。
总结
background
container
在存储领域中,针对磁盘备份的压缩去重,传统是使用基于容器的数据布局。
许多基于重复数据删除的存储系统通常与压缩技术相结合,所有的块都作为压缩的基本单元存储在容器中。【也即,一个“容器”事实上是一个压缩的基本单元,这个划分是为压缩服务的。】因此,存储I/O通常是以顺序存储的容器为粒度的。容器通常具有固定大小。
一个备份相当于由多个指针构成,每个指针都指向某个container的某个chunk。
碎片化
碎片化与基于容器的I/O和hdd的查找延迟有关。随着备份层数增多,相邻数据所指向的version就很有可能会不一样,chunk粒度减小,碎片化问题严重程度会增大,从而导致相邻的数据存储的磁盘位置相差甚远,不利于应用程序的性能。
deduplication技术
Content-Defined Chunking 基于内容分块
Fingerprint Index
Restore Optimization
‘rewriting’ and ‘cache’.
GC
传统的Mark Sweep
遍历需要释放的备份,解引用备份中用到的chunks。当chunks引用计数为0释放。并且还要做container合并工作。
Container-Marker Algorithm
problems
数据局部性:
程序对磁盘的修改往往具有局部性特点。因而,相邻两个备份之间的被修改的差异可能遵循数据局部性特点,集中在某块区域。这就会导致碎片化问题,也即最经常被访问的那块磁盘区域会在备份间被划分为多个小块,并且指针情况错综复杂。
从而,对于局部访问频繁的那部分数据,同一个备份中的相邻两个chunks的局部性也会被破坏,因为它们虽然逻辑连续,但是物理存储却不一定连续。
restore和gc性能垃圾
对于restore,过多的deduplication就会导致一个备份中相邻数据块实际存储的容器不同,导致:
- 读放大问题:每次读取一个数据块就得读取其所在的整个容器(因为是IO粒度),导致read amplification很垃圾。
- 查找问题:需要多次读取不同容器,因而需要多次随机IO到不同容器位置,这与hdd(Hard Disk Drive)的设计相违背(HDD连续读取快,随机寻址慢),从而导致性能垃圾。
对于GC,需要unreference的chunks会分布在各个不同容器中,影响GC性能。
solutions
在container和backup中新加一层category分类,分类方式:
- 根据reference relationship对chunks进行分类
- 类别只考虑那些版本号连续 or 独立版本号的类别,如B1B2B3,B3B4,B1这种(也很容易知道,这样分类比较有意义),这样一来类别数目就可以从2^n降到n(n + 1)*/*2 for n backup versions。
这样一来,我们可以显著提高restore和gc:
restore
比如说要restore版本Bj,我们就需要恢复所有包含Bj这个版本指针的category,并且每个category中的多个chunks做的IO操作都是一样的(比如一个category的指针序列为B2B3B4,那么IO操作的回溯次序是一模一样的),这样就能极大减少随机IO。
gc
gc时,比如说要删除版本Bi,我们只需要删除所有category中的这个版本指针,并且在一个category没有版本指针后释放category及其对应chunk就行。
传统的方法将数据块保存在固定大小的容器中,也即相当于通过顺序划分数据块,随着备份层级增大,chunks碎片化问题严重,相邻的数据块可能存储在不同磁盘位置,导致局部性垃圾,读放大高,restore和gc开销大。于是MFDedup通过修改数据布局,通过备份版本号来对数据块进行分类。类似九九乘法表的volume布局。
备份
inline:fingerprint(NDF) offline:arrange(AVAR)
arrange:通过NDF。如果上一个版本的数据块没出现在新版本,就归档;否则就迁移到新版本备份对应卷组上。
restore
恢复所有包含了备份版本号的category。
gc
只需删除其unique 块。
abstract/introduction
deduplication被广泛用于减小backup,但会带来碎片化问题(影响restore和gc)和poor locality。
一个硬盘中的文件往往会随着时间推移拥有多个备份,去重就是针对这些备份之间的概念。我们采用对每个chunk(通过fingerprint标识)进行引用的方法进行去重,但这会导致严重的碎片化(也即丧失数据局部性)和GC性能的问题。
碎片化:
随着备份层数增多,相邻数据所指向的version就很有可能会不一样,chunk粒度减小,碎片化问题严重程度会增大,从而导致相邻的数据存储的磁盘位置相差甚远,不利于应用程序的性能。详情见下例子:
As an example, consider backup version 1 that has few or no duplicates, so its chunks are stored sequentially in containers.
Then, version 2 may be highly re dundant with the first with small modifications throughout the backup, so its recipe has references to many chunks of the first version intermixed with references to newly written chunks.
Later, version N tends to have even worse locality as it refers to chunks written by many previous backup versions, so restoring a backup version involves random seeks back and forth across the disks, and read amplification is high since an accessed container may have needed and unneeded chunks.
为了解决这个问题,以往的策略是针对那些被频繁访问的数据或者碎片化程度(
fragmentation degree)到达一定的阈值之后就进行rewrite,或者使用SSD来cache那些被频繁reference的chunk。但这依然无法根治碎片化问题。我们提出了 MFDedup ,保持了备份的数据局部性,通过 data classification 生成了优化的 data layout。关键技术为Neighbor-Duplicate-Focus indexing(NDF) and Across-Version-Aware Reorganization scheme(AVAR)。
基于容器的数据布局
在存储领域中,针对磁盘备份的压缩去重,传统是使用基于容器的数据布局。
基于容器的数据布局相当于是对数据块进行分类,有几类就有几个容器。分类的依据可以是简单的顺序分类,也可以是哈希值分类等。
在我们对重复数据删除备份的观察中,我们发现备份版本Bi+1中几乎所有的重复块都来自于它之前的版本Bi
MFDedup基本思路
传统方法的容器按顺序分类,重点在于简化新建备份时的写路径,但碎片化问题严重;我们提出的数据布局方法按照reference relationship分类,重点在于简化restore备份,写入可能复杂点,但是恢复和gc很快。
根据reference relationship对chunks进行分类
类别只考虑那些版本号连续 or 独立版本号的类别,如B1B2B3,B3B4,B1这种(也很容易知道,这样分类比较有意义),这样一来类别数目就可以从2^n降到n(n + 1)*/*2 for n backup versions。
这样的话,就只会重复删除internal、adjust块,而不会删除skip块,也即如下图右所示:
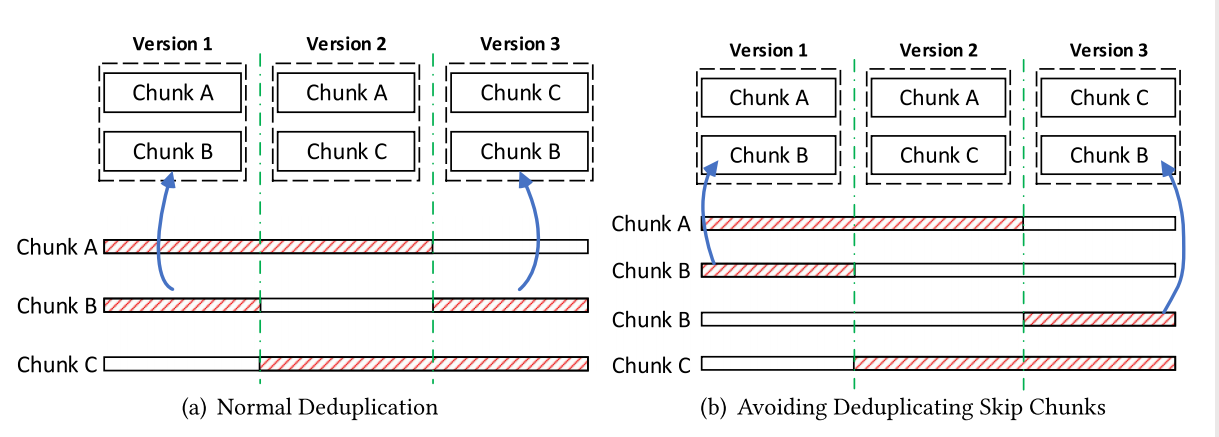
这样一来,我们可以显著提高restore和gc:
restore
比如说要restore版本Bj,我们就需要恢复所有包含Bj这个版本指针的category,并且每个category中的多个chunks做的IO操作都是一样的(比如一个category的指针序列为B2B3B4,那么IO操作的回溯次序是一模一样的),这样就能极大减少随机IO。
gc
gc时,比如说要删除版本Bi,我们只需要删除所有category中的这个版本指针,并且在一个category没有版本指针后释放category及其对应chunk就行。
不得不说,真是很巧妙。
background
containers
解释了一下为什么会有containers,以及其作用。
许多基于重复数据删除的存储系统通常与压缩技术相结合,所有的块都作为压缩的基本单元存储在容器中。【也即,一个“容器”事实上是一个压缩的基本单元,这个划分是为压缩服务的。】因此,存储I/O通常是以顺序存储的容器为粒度的。
容器通常具有固定大小。
碎片化
碎片化与基于容器的I/O和hdd的查找延迟有关。
inline and offline deduplication
- Inline Deduplication(内联去重): 在内联去重中,数据去重的过程发生在数据写入备份存储之前,即在备份数据被存储到磁盘或其他媒体之前。
- Offline Deduplication(离线去重): 在离线去重中,备份数据首先被写入备份存储,然后在后续的离线过程中进行去重。
deduplication广泛运用于primary storage和secondary storage。其中,Primary storage prioritizes low latency, whereas secondary storage works prioritize high throughput.
这里还提到了一个很巧妙的RevDedup:
RevDedup shifts fragmentation to older backups by adjusting their references to newer backups to retain the locality of newer backups that are more likely to be restored. As a result, restoring older backups will be slower with this approach.
也就是说,原来是新备份指向原来的旧备份,从而导致新备份碎片化;现在是旧备份指向新备份,碎片化的变成了旧备份!同时,它只将创建新备份操作inline,调整旧备份指向新备份的操作offline,也降低了性能损耗。牛的。这个方法的缺点就是恢复旧备份会很慢。
Observation and Motivation
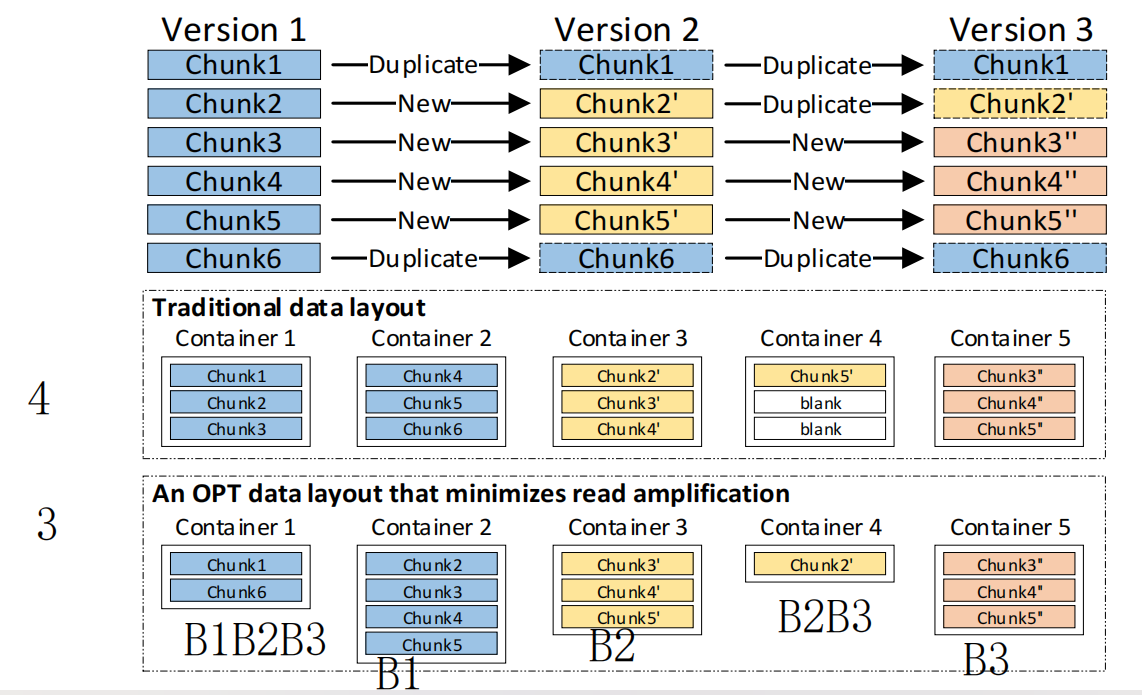
After
不过我以前还以为去重就是简单的在不同备份版本中建立二维指针,看来我还是想得太天真了。
下图是最理想的去重方法,保留了deduplication和locality:
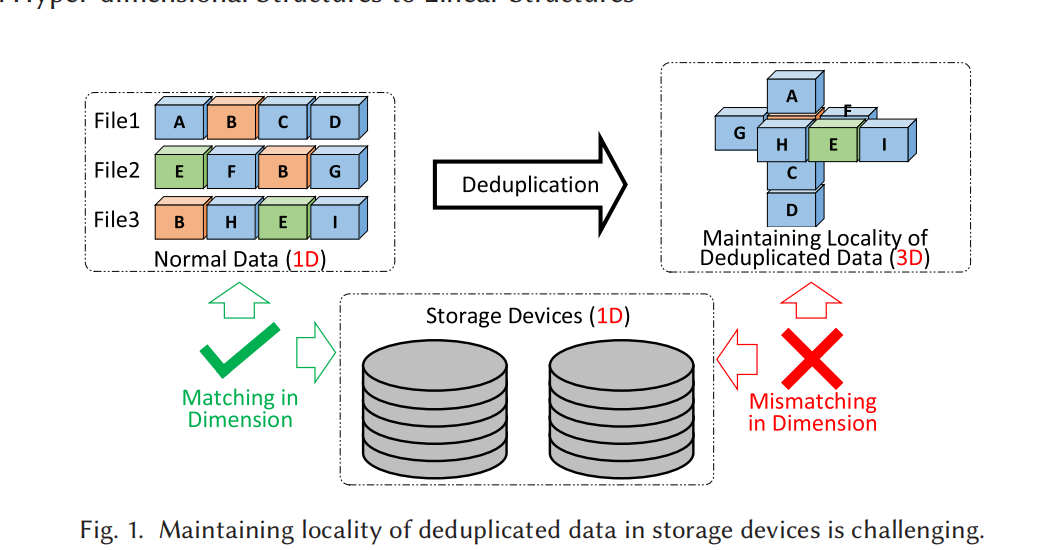
但意思好像是说这东西不实用,所以我们最终只能退而求其次,用二维指针法组织多个备份,但这就很难兼容locality。
而且这样就引出了一个很巧妙的角度:数据去重data layout的高维结构&&存储设备顺序存储,这两者之间的矛盾。
Directly considering how to flatten the hyper-structure of deduplicated data is difficult, and in this article, we consider how to maintain locality in the flattened structure and discuss that from both the micro and macro perspectives.
还有值得注意的是,这边也提出了好几种去重针对的文件类型:backup files, database snapshots, virtual machine images,并且提到了一点就是去重事实上是根据它们的fingerprint去重的。
并且它还提出了deduplication中和文件系统中碎片化问题的不同。
并且值得注意的是,除了我上面说的读取一个类目的容器有助于解决读放大,它这边还说明了另一个很重要的点,也即是如何在restore时保证磁盘顺序读取的。
当我们restore备份时,每次都是得读取所有包括它这个版本号的category,也即所有Cat( i, n ) ( 1 < i <= k )。所以,我们可以将Cat( i, n ) ( 1 < i <= k )在物理设备上连续存储,从而方便磁盘顺序读取:
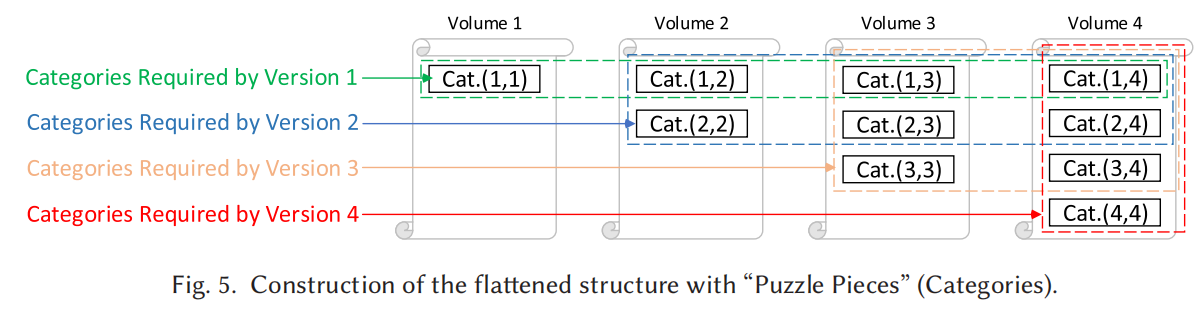
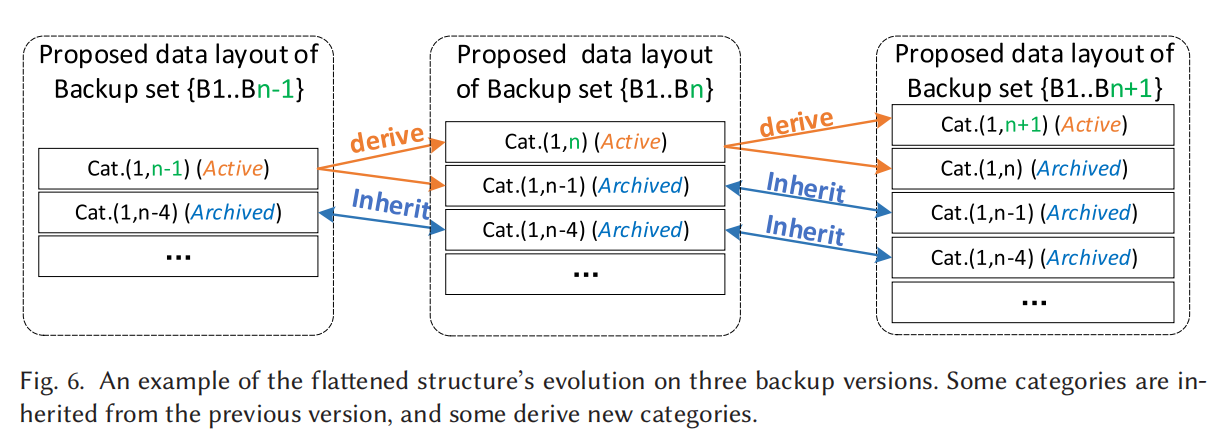
并且,每次产生新的备份版本时也无需更新所有的category,只需更新那些延续到latest的就行,其它的都已经算是archive状态只需备份无需更新。
所以,看到现在整理一下总体思路:
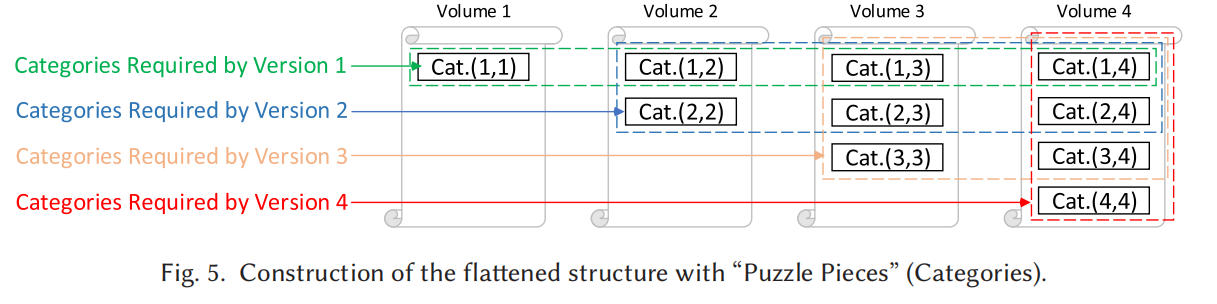
将chunk以连续备份版本号分类,总共分成n(n+1)/2个category(这样做无视了对skip data的deduplication。skip data:如一个数据块在版本1和3出现)。一个category中存放的是指针信息,指向了类似页表一样的hash table(recipe)。hash table中真正记录了数据块的物理地址。
对于restore
当我们restore备份时,每次都是得读取所有包括它这个版本号的category:
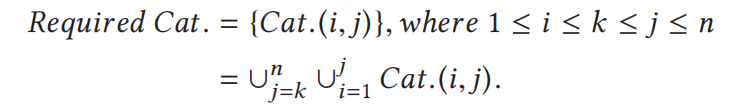
也即比如n=4,我们想恢复version 2,就需要Cat 1,2 2,2 1,3 2,3 1,4 2,4
所以,我们可以将Cat( i, n ) ( 1 < i <= k )在物理设备上连续存储,从而方便磁盘顺序读取:
对于update
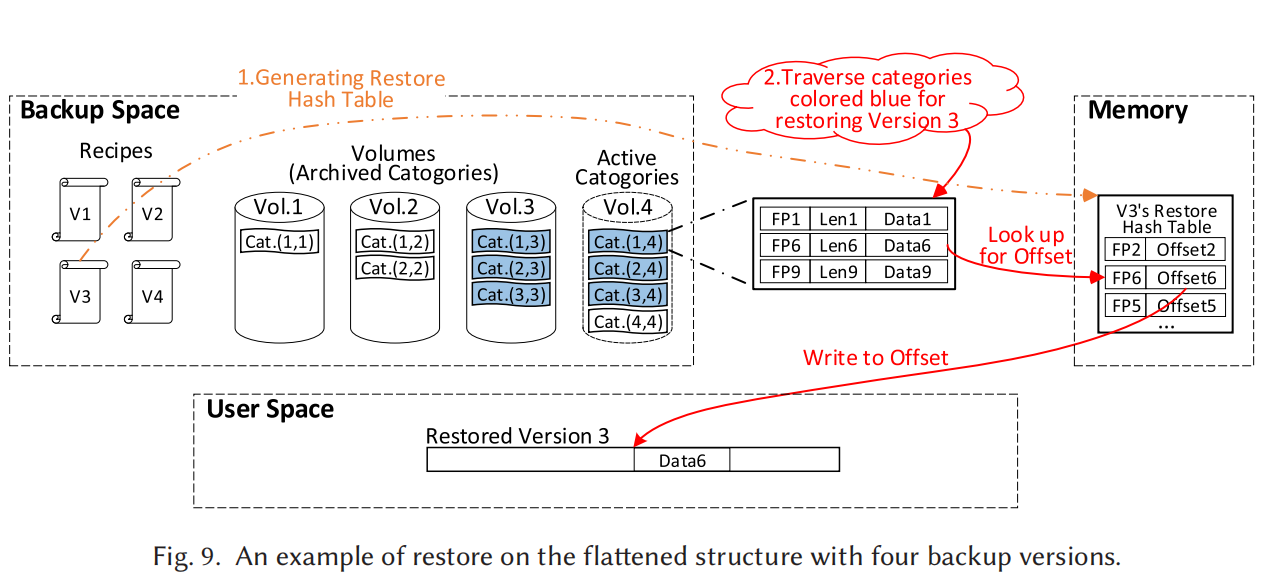
每次产生新的备份版本时也无需更新所有的category,只需更新那些延续到latest的就行,其它的都已经算是archive状态只需备份无需更新。
对于gc
删除某个版本时,只删除那个版本特有块,也即Cat n,n ,也就是说比如备份2被删了,那么Cat 1,3 依然整体存在而不会被拆分为Cat 1,1 + Cat 3,3。然后好像同时也会维护,如果一个数据块最后一个引用也没了,就直接踢了。
空间管理
通过卷的大小预估下次备份所占用的空间
因为卷相当于当前版本与上一个版本之间的差异,所以可以用来预估
通过在volum和category开头统计信息来获取剩余空间
可以看到,大大减少了GC和restore的开销,update开销也可以近似没有。