此为《程序员的自我修养:链接、装载与库》(俞甲子,石凡,潘爱民)的看书总结。
链接前与装载
链接前的编译阶段可以生成.o文件,.o文件是ELF文件,里面含有段表、符号表、bss段、common段等链接辅助段。
执行可执行文件时,首先要通过fork创建一个新的子进程,然后要通过exec为子进程制定可执行文件装载逻辑。在exec系统调用中,会进行elf文件的读取解析。它会解析elf header,根据其各种信息将程序copy到内存(进程的虚拟地址空间)中,后者也就是我们所研究的装载。
装载不同于“节(section),是以”段“(segment)为单位。进程虚拟地址空间被分为很多个VMA,每个VMA都有不同的属性(如权限,可读可写可执行)。ELF可执行文件除去在链接/编译过程中被视为一个个连续的节之外,它还会在链接的时候根据每个节的属性不同重排节,把属性相同的节连续放在一起成为一个个段。链接的时候还会形成程序头表。对应关系:节——段表,段——程序头表
装载进内存时,是以段为单位,一个段就对应着一个VMA。
内核通过execve系统调用装载完ELF可执行文件以后就返回到用户空间,将控制权交给程序的入口。
对于不同链接形式的ELF可执行文件,这个程序的入口是有区别的。对于静态链接的可执行文件来说,程序的入口就是ELF文件头里面的e_entry指定的入口地址;对于动态链接的可执行文件来说,如果这时候把控制权交给e_entry指定的入口地址,那么肯定是不行的,因为可执行文件所依赖的共享库还没有被装载,也没有进行动态链接。所以对于动态链接的可执行文件,内核会分析它的动态链接器地址(在“.interp”段),将动态链接器映射至进程地址空间,然后把控制权交给动态链接器。
ELF
编译器编译源代码后生成的文件叫做目标文件(Object文件),目标文件从结构上讲,它是已经编译后的可执行文件格式,只是还没有经过链接的过程,其中可能有些符号或有些地址还没有被调整。其实它本身就是按照可执行文件格式存储的,只是跟真正的可执行文件在结构上稍有不同。
Linux的可执行文件遵从ELF的结构模式。
ELF可以分为这几类:
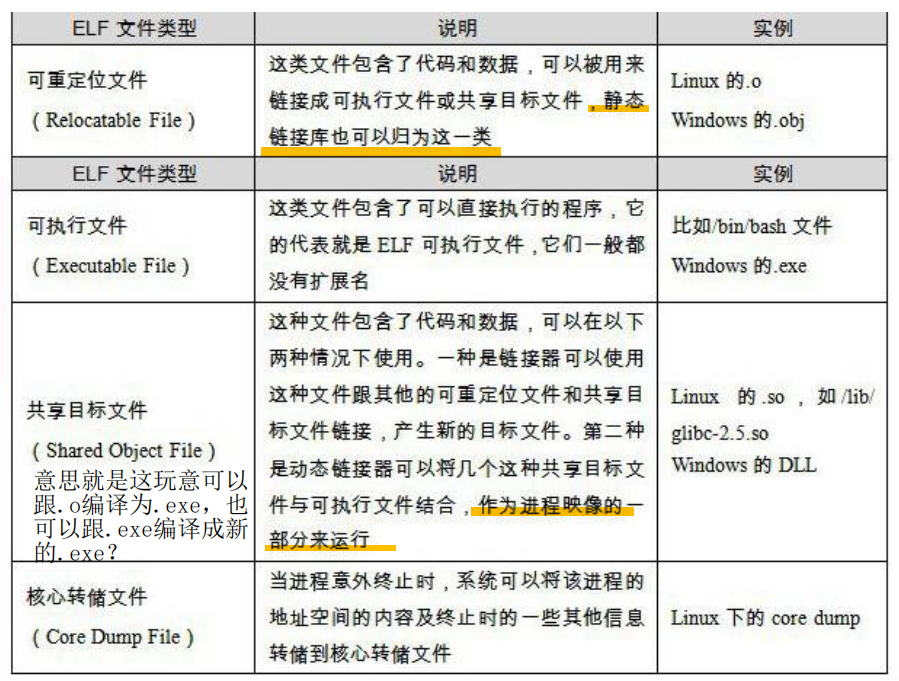
也即.o(可重定位文件)、.exe(无后缀)(可执行文件)、.so(动态链接库)、.a(静态链接库)、core dump。
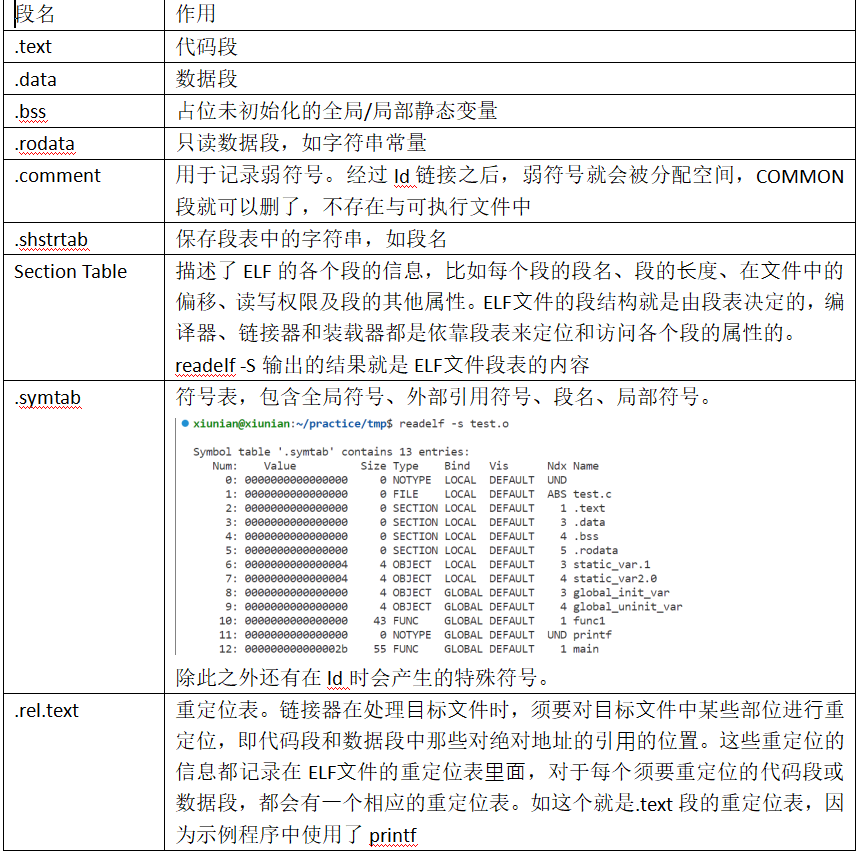
Object文件的结构
目标文件中的内容至少有编译后的机器指令代码、数据。没错,除了这些内容以外,目标文件中还包括了链接时所须要的一些信息,比如符号表、调试信息、字符串等。一般目标文件将这些信息按不同的属性,以“节”(Section)的形式存储,有时候也叫“段”(Segment)。
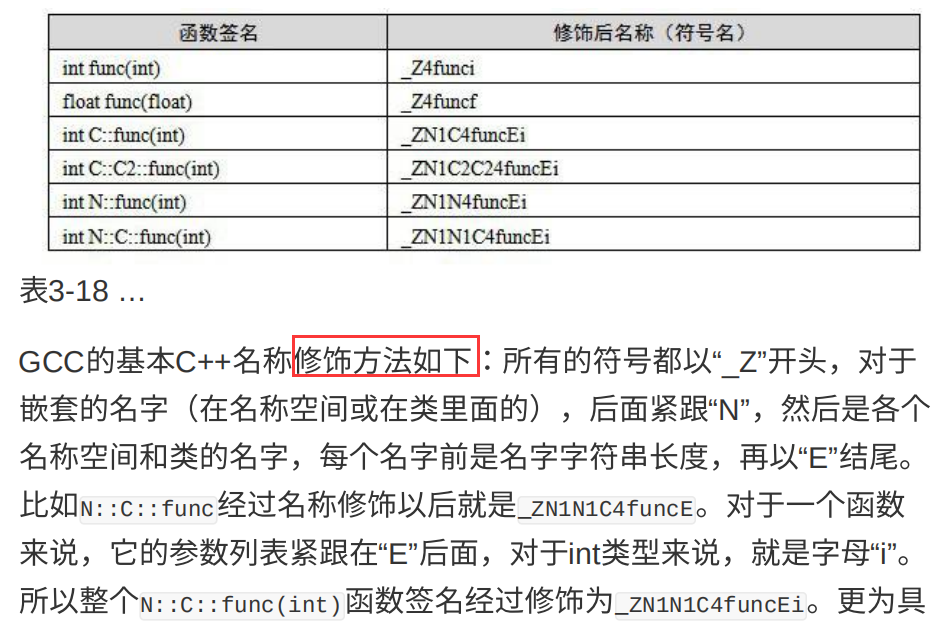
符号修饰
众所周知,强大而又复杂的C++拥有类、继承、虚机制、重载、名称空间等这些特性,它们使得符号管理更为复杂。最简单的例子,两个相同名字的函数func(int)和func(double),尽管函数名相同,但是参数列表不同,这是C++里面函数重载的最简单的一种情况,那么编译器和链接器在链接过程中如何区分这两个函数呢?为了支持C++这些复杂的特性,⼈们发明了符号修饰(Name Decoration)或符号改编(Name Mangling)的机制。
C++为了与C兼容,在符号的管理上,C++有一个用来声明或定义一个C的符号的“extern “C””关键字用法:
1 | extern ”C” { |
C++编译器会将在extern “C” 的大括号内部的代码当作C语言代码处理。所以很明显,上面的代码中,C++的名称修饰机制将不会起作用。
强符号和弱符号
多个目标文件中含有相同名字全局符号的定义,那么这些目标文件链接的时候将会出现符号重复定义的错误。这种符号的定义可以被称为强符号(Strong Symbol)。有些符号的定义可以被称为弱符号(Weak Symbol)。对于C/C++语言来说,编译器默认函数和初始化了的全局变量为强符号,未初始化的全局变量为弱符号。我们也可以通过GCC的__attribute__((weak))来定义任何一个强符号为弱符号。

目前我们所看到的对外部目标文件的符号引用在目标文件被最终链接成可执行文件时,它们须要被正确决议,如果没有找到该符号的定义,链接器就会报符号未定义错误,这种被称为强引用(Strong Reference)。与之相对应还有一种弱引用(Weak Reference),在处理弱引用时,如果该符号有定义,则链接器将该符号的引用决议;如果该符号未被定义,则链接器对于该引用不报错。
链接器处理强引用和弱引用的过程几乎一样,只是对于未定义的弱引用,链接器不认为它是一个错误。一般对于未定义的弱引用,链接器默认其为0,或者是一个特殊的值,以便于程序代码能够识别。
1 | __attribute__ ((weakref)) void foo(); |
这种弱符号和弱引用对于库来说十分有用,比如库中定义的弱符号可以被用户定义的强符号所覆盖,从而使得程序可以使用自定义版本的库函数。
这里很帅,有条件编译那味了
在Linux程序的设计中,如果一个程序被设计成可以支持单线程或多线程的模式,就可以通过弱引用的方法来判断当前的程序是链接到了单线程的Glibc库还是多线程的Glibc库(是否在编译时有-lpthread选项),从而执行单线程版本的程序或多线程版本的程序。我们可以在程序中定义一个pthread_create函数的弱引用,然后程序在运行时动态判断是否链接到pthread库从而决定执行多线程版本还是单线程版本:
1 |
|
弱符号大概是说该变量可以被定义多次,最终链接时再进行决议;弱引用大概是说该变量(函数)可以不被定义。
静态链接
静态链接库(.a文件)本质上是一堆.o文件的集合。静态链接的基本过程:
1 | test.c ——(compile)——>test.o——(link)——>test(ELF exe) |
静态链接其实也就是分为两大步骤:
空间与地址分配
将input file的各个段都连在一起,并且为符号分配虚拟地址
符号解析与重定位
扫描所有输入文件的符号表形成全局符号表;
重定向
可执行文件基本可以确定自己在进程虚拟空间中的起始位置,因为可执行文件往往是第一个被加载的文件,它可以选择一个固定空闲的地址。因而,在link中,可执行文件的地址都以确定,就可以开始进行重定向。
通过重定向表对所有UNDEF的符号进行地址修正,包括相对地址修正和绝对地址修正。
在link中,会读取test.o以及lib.a中的符号表,完成重定向(绝对地址和相对地址)以及节的重排组织,最终组合形成以段为单位的可执行文件test。
可执行文件test会通过系统调用exevec被装载进物理内存(lazy allocation),分段映射到进程的虚拟地址空间。
静态链接的缺陷是,由于重定向在link过程完成,故而同一份共享库在物理内存中会有多份copy,极大占用物理内存和磁盘空间。优点是速度快。
动态链接
(下文注意区分两个概念:可执行文件和动态链接库)
动态链接库(.so)不同于静态链接库。
1 | test.c ——(compile)——>test.o——(link)——>test(ELF exe) |
在link中,仅会读入动态链接库的符号表,对于动态链接库的符号仅会将其标记为动态符号,而不会对其进行重定向。
可执行文件test会通过系统调用exevec被装载进物理内存(lazy allocation),分段映射到进程的虚拟地址空间。
静态链接是per-process一份库,内存中有多份库;动态链接是per-process一份库,内存也只有一份库。并且虚拟地址动态分配,也即库映射到进程地址空间的哪块VMA是不确定的。
由于动态链接库被装载时的虚拟地址不确定,所以对于动态链接库和可执行文件代码中与动态链接相关的绝对地址,不能简单采用装载时重定向的方法来对其重定向,否则会破坏其共享性和不变性。
试想一下,每个进程加载的动态链接库的地址都不同,那岂不是每个进程的动态链接库的重定向结果都不一样,指令都不一样,不就寄了。
所以我们此时进行了一个牛逼到家、惊天动地、无人能比的操作。
我们可以分离.text和.data,前者作为“共享”语义保持不变性,后者则在每个进程地址空间中都留存一个copy。然后,我们将所有立即数绝对寻址的地方,换为间接寻址!也即,把那个立即数绝对地址改成一个变量,变量值在.data段中存储。这样一来,就成功把绝对寻址替换成了相对寻址。加载的时候也只需将虚拟地址填进可变的.data就行。不得不说真是十分地巧妙。
这个从相对地址——绝对地址的转换过程,由ELF中的一个新段GOT表(.got)来实现。在link时加入了动态链接库符号表的可执行文件,以及动态链接库本身,都使用了.got段,以PIC形式出现。
这个操作就是所谓的“地址无关代码”,通过-fPIC选项,就可以将代码编译为一个地址无关的程序。使用PIC模式编译的共享对象,对于模块内部的函数调用也是采用跟模块外部函数调用一样的方式,即使用GOT/PLT的方式。
小trick:如何区分一个DSO是否为PIC
如果上面的命令有任何输出,那么foo.so就不是PIC的,否则就是PIC的。PIC的DSO是不会包含任何代码段重定位表的,TEXTREL表⽰代码段重定位表地址。
这也很好理解,因为PIC本质上就是把代码段重定位转化为了数据段重定位。
除了动态链接库中的寻址(对变量和函数)需要使用PIC之外,对可执行文件的全局变量也需要使用特殊的机制。ELF共享库中的全局变量都类似以弱引用形式存在。当全局变量在主程序extern时,若该变量在共享库中初始化了,那么加载之后要把共享库的数据copy进主程序;否则,该变量值都以主模块为准。
这段原因解释看书真没懂,详情340页开始。
不过感觉它可能说的有点问题,我个人认为全局变量需要使用这种以方式存在,是为了保证进程资源独立。如果变量都以共享库中的数据值为准,那各个进程共享共享库不就乱了。。。你改一下我改一下
因而,总的装载流程是:
未优化情况下,在可执行文件被装载之前,先将其依赖的所有动态链接库加载进内存。若其所需的动态链接库已经被映射到物理内存,则将其装载到进程虚拟地址空间;否则,则映射到物理内存,并且装载到进程虚拟地址空间。然后,在装载动态链接库后,扫描可执行文件.got段符号进行装载时重定向(依据已经装载了的动态链接库虚拟地址来计算符号地址)即可。
但可以注意到这一步还是有优化空间。所以我们采取延迟绑定(PLT)的方法,第一次访问到动态链接库符号时,才对其进行重定向并填入.got中。
动态链接的缺点就是太慢了,一是因为PIC导致模块内部函数和全局变量也需要以.got形式访问,加了层寻址;二是运行时重定向开销巨大。对于前者,模块内部函数可以使用static关键字修饰;对于后者,采用PLT。

显式运行时链接
支持动态链接的系统往往都支持一种更加灵活的模块加载方式,叫做显式运行时链接(Explicit Runtime Linking),有时候也叫做运行时加载。也就是让程序自己在运行时控制加载指定的模块,并且可以在不需要该模块时将其卸载。
也就是说,前面介绍的动态链接库是由动态链接器自动完成的,程序啥也不知道;这里的动态装载库是程序自己控制的,所以会提供给程序各种API。
而动态库的装载则是通过一系列由动态链接器提供的API,具体地讲共有4个函数:打开动态库(dlopen)、查找符号(dlsym)、错误处理(dlerror)以及关闭动态库(dlclose),程序可以通过这几个API对动态库进行操作。这几个API的实现是在/lib/libdl.so.2里面,它们的声明和相关常量被定义在系统标准头文件<dlfcn.h>。
很有意思的是,如果我们将filename这个参数设置为0,那么dlopen返回的将是全局符号表的句柄,也就是说我们可以在运行时找到全局符号表里面的任何一个符号,并且可以执行它们,这有些类似高级语言反射(Reflection)的特性。全局符号表包括了程序的可执行文件本身、被动态链接器加载到进程中的所有共享模块以及在运行时通过dlopen打开并且使用了RTLD_GLOBAL方式的模块中的符号。
它接下来举的例子很有意思,可惜不知道为啥在我这一直segment fault。。。好像是它用的内联汇编是32位什么的,我折腾了半天还是没办法,算了
1 | /* |
运行库
初始化
操作系统装载程序之后,首先运行的代码并不是main的第一行,而是某些别的代码,这些代码负责准备好main函数执行所需要的环境,并且负责调用main函数,这时候你才可以在main函数里放心大胆地写各种代码:申请内存、使用系统调用、触发异常、访问I/O。在main返回之后,它会记录main函数的返回值,调用atexit注册的函数,然后结束进程。
运行这些代码的函数称为入口函数或入口点(Entry Point),视平台的不同而有不同的名字。程序的入口点实际上是一个程序的初始化和结束部分,它往往是运行库的一部分。
一个典型的程序运行步骤大致如下:
操作系统在创建进程后,把控制权交到了程序的入口,这个入口往往是运行库中的某个入口函数。
入口函数对运行库和程序运行环境进行初始化,包括堆、I/O、线程、全局变量构造,等等。
入口函数在完成初始化之后,调用main函数,正式开始执行程序主体部分。
main函数执行完毕以后,返回到入口函数,入口函数进行清理⼯作,包括全局变量析构、堆销毁、关闭I/O等,然后进行系统调用结束进程。
Linux中的C语言运行库就是glibc。
运行库
运行时库(Runtime Library)为入口函数及其所依赖的函数所构成的函数、各种标准库函数的实现的集合。可以通过sudo apt-get install glibc-source安装glibc的源代码。
一个C语言运行库大致包含了如下功能:
启动与退出:包括入口函数及入口函数所依赖的其他函数等。
标准函数:由C语言标准规定的C语言标准库所拥有的函数实现。
I/O:I/O功能的封装和实现,参见上一节中I/O初始化部分。
应该指的是比如说提供File*指针、IO stream之类的高级功能封装。
堆:堆的封装和实现,参见上一节中堆初始化部分。
这点让我耳目一新!因为我以前一直以为堆栈都是操作系统实现的,现在想来才发现确实,操作系统只负责通过sbrk系统调用给内存,具体的堆分配算法由glibc的malloc实现。
语言实现:语言中一些特殊功能的实现。
调试:实现调试功能的代码。
库函数介绍
它这里主要讲了两个比较特殊的库,还挺有意思的:变长参数(stdarg.h)和非局部跳转(setjmp.h)。
变长参数
讲这玩意其实用作是printf的实现。看下下面这两个代码相信你就能明白printf的基本原理了:
1
2
3
4
5
6
7
8
9
10
11
12// Code 1
int sum(unsigned num, ...)
{
int* p = &num + 1;
int ret = 0;
while (num--)
ret += *p++;
return ret;
}
call:
int n = sum(3, 16, 38, 53);1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
// Code 2
void arg_match(const char* fmt, ...) {
va_list ap; // 本质char * / void *
va_start(ap, fmt); // 之后ap就会指向fmt后的第一个可变参数
int idx = 0;
for (int i = 0; i < strlen(fmt); i ++) {
if (fmt[i] != '%') continue;
idx ++;
switch (fmt[i + 1]) {
case 'd':
int argv_i = va_arg(ap, int);
printf("第%d个参数为:%d\n", idx, argv_i);
break;
case 's':
char* argv_s = va_arg(ap, char*);
printf("第%d个参数为:%s\n", idx, argv_s);
break;
default:
printf("unknown.\n");
break;
}
}
}
call:
arg_match("%d %d %s\n", 1, 2, "333");除此之外,我们也可以实现变长参数宏:
在GCC编译器下,变长参数宏可以使用“##”宏字符串连接操作实现。
1
非局部跳转
这位更是重量级
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
jmp_buf b;
void f()
{
longjmp(b, 1);
}
int main()
{
if (setjmp(b))
printf("World!");
else
{
printf("Hello ");
f();
}
}事实上的输出是:
Hello World!
实际上,当setjmp正常返回的时候,会返回0,因此会打印出“Hello”的字样。而longjmp的作用,就是让程序的执行流回到当初setjmp返回的时刻,并且返回由longjmp指定的返回值(longjmp的参数2),也就是1,自然接着会打印出“World!”并退出。换句话说,longjmp可以让程序“时光倒流”回setjmp返回的时刻,并改变其行为,以至于改变了未来。
glibc
glibc是对标准C运行库的扩展(如增加了pthread),全称GNU C Library,是GNU旗下的C标准库。
生命周期
于是,我们可以完整串联整个运行程序的生命周期:
由链接器ld将所有.o文件的_init段和_finit段(包含glibc对堆空间的初始化和释放、编译器对C++全局对象构造析构的实现以及app自己实现的init和finit函数)分别串在一起,并且链接上glibc库的包含了_start(会调用_init)的crt.o文件,最后就形成了包含各种glibc标准库和真·用户代码的可执行文件。
可执行文件被装载到进程地址空间后,首先会进行动态链接。然后,从程序入口_start开始进行各种初始化,调用可执行文件的这个_init段的内容。init完成之后,glibc就调用程序中的入口main。main执行过程中会用到glibc的各种标准库函数。main执行完后就会继续执行_finit段来结束一切。
C++的全局对象构造析构
构造(
_init)编译器会将每个全局对象的构造函数以如下形式包装:
1
2
3
4
5static void GLOBAL__I_Hw(void)
{
Hw::Hw(); // 构造对象
atexit(__tcf_1); // 一个神秘的函数叫做__tcf_1被注册到了exit
}然后将这个
GLOBAL__I_Hw放进.o文件的一个.ctor段中,最后由ld将各个.o文件的.ctor段链接起来,并计算出全局对象数量填入crtbegin.o即可。之后在
_init段中遍历.ctor的各个函数指针进行构造函数调用就行了后日谈:今天又在rtt中看到了这一牛掰操作。rtt也是大概通过这个原理实现的帅的一匹的“Automatic Initialization Mechanism”。
原理感觉也是将其放入一个特殊的”rti_fn$f”段,并且用rti_start和end来标识该段结束,
1
2
3
4
5
6// xiunian: INIT_EXPORT应该是这个
INIT_EXPORT(fn, "1.0") 宏展开:
const char __rti_level_fn[] = ".rti_fn." "1.0";
// 指示编译器将特定的变量或数据结构分配到名为 "rti_fn$f" 的内存段(Memory Segment)中
__declspec(allocate("rti_fn$f"))
rt_used const struct rt_init_desc __rt_init_msc_fn = {__rti_level_fn, fn };1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48/*
* xiunian: 牛逼,这里颇有学链接时的感觉了
* 这里介绍了组件初始化顺序
* Components Initialization will initialize some driver and components as following
* order:
* rti_start --> 0
* BOARD_EXPORT --> 1
* rti_board_end --> 1.end
*
* DEVICE_EXPORT --> 2
* COMPONENT_EXPORT --> 3
* FS_EXPORT --> 4
* ENV_EXPORT --> 5
* APP_EXPORT --> 6
*
* rti_end --> 6.end
*
* These automatically initialization, the driver or component initial function must
* be defined with:
* INIT_BOARD_EXPORT(fn);
* INIT_DEVICE_EXPORT(fn);
* ...
* INIT_APP_EXPORT(fn);
* etc.
*/
static int rti_start(void)
{
return 0;
}
INIT_EXPORT(rti_start, "0");
static int rti_board_start(void)
{
return 0;
}
INIT_EXPORT(rti_board_start, "0.end");
static int rti_board_end(void)
{
return 0;
}
INIT_EXPORT(rti_board_end, "1.end");
static int rti_end(void)
{
return 0;
}
INIT_EXPORT(rti_end, "6.end");之后真正初始化只需遍历然后调用函数指针即可
1
2
3
4
5
6
7
8
9void rt_components_board_init(void)
{
volatile const init_fn_t *fn_ptr;
for (fn_ptr = &__rt_init_rti_board_start; fn_ptr < &__rt_init_rti_board_end; fn_ptr++)
{
(*fn_ptr)();
}
}析构(
_finit)早期同理可得。现在变了,变成直接在
GLOBAL__I_Hw中注册atexit了。1
2
3
4static void __tcf_1(void) //这个名字由编译器生成
{
Hw.~HelloWorld();
}
实现小型运行库
看到标题就知道接下来有多帅了
在这一章我们仅实现CRT几个关键的部分。虽然这个迷你CRT仅仅实现了为数不多的功能,但是它已经具备了CRT的关键功能:入口函数、初始化、堆管理、基本IO,甚至还将实现堆C++的new/delete、stream和string的支持。
本章主要分为两个部分,首先实现一个仅仅支持C语言的运行库,即传统意义上的CRT。其次,将为这个CRT加入一部分以支持C++语言的运行时特性。
相关代码放在github了,其实感觉差不多是按它写的抄了一遍。可以现在稍微整理下文件结构。
just for C
前面说到,CRT的作用是执行init和finit段、进行堆的管理、进行IO的封装管理以及提供各种标准C语言库。因而,我们可以分别用如下几个文件来实现这几个功能:
entry.c用于实现入口函数
mini_crt_entry。入口函数中主要要做:调用main之前的栈构造、堆初始化、IO初始化,最后调用main函数。main函数返回后,通过系统调用exit来杀死进程。malloc.c用于实现堆的管理,主要实现了
malloc和free。使用了空闲链表的小内存管理法,实现简单。stdio.c用于实现IO封装,
fread、fwrite、fopen、fclose、fseek。实现简单,因而只是系统调用的封装string.c以字符串操作为例,提供的标准C语言库。
之后,我们将其以如下参数编译为静态库:
1
2
3
4$ gcc -c -fno-builtin -nostdlib -fno-stack-protector entry.c malloc.c stdio.c string.c printf.c
$ ar -rs minicrt.a malloc.o printf.o stdio.o string.o
# 编译测试用例
$ gcc -m32 -c -ggdb -fno-builtin -nostdlib -fno-stack-protector test.c再指定
mini_crt_entry为入口进行静态链接:1
$ ld -m elf_i386 -static -e mini_crt_entry entry.o test.o minicrt.a -o test
C++
如果要实现对C++的支持,除了在上述基础上,我们还需增加以下几个内容:全局对象(cout)构造/析构的实现、new/delete、类的实现(string和iostream)。具体来说,会支持下面这个简单的代码:
1
2
3
4
5
6
7
8
9
10
11
using namespace std;
int main(int argc, char* argv[])
{
string* msg = new string("Hello World");
cout << *msg << endl;
delete msg;
return 0;
}我们可以分步实现这些功能:
new/delete实现
简单地使用运算符重载功能即可:
1
2void* operator new(unsigned int size);
void operator delete(void* p);类的实现
不多说
全局对象的构造/析构
构造
全局对象的构造在entry中进行:
1
2
3
4
5
6
7void mini_crt_entry(void)
{
...
// 构造所有全局对象
do_global_ctors();
ret = main(argc,argv);
}前文说过,在Linux中,每个.o文件的全局构造最后都会放在
.ctor段。ld在链接阶段中将所有目标文件(包括用于标识.ctor段开始和结束的crtbegin.o和crtend.o)的.ctor段连在一起。所以,我们就需要实现三个文件:ctors.c主要是用于实现
do_global_ctors()。既然都有.ctor段存在了,那么它的实现就很简单,就是遍历.ctor段的所有函数指针并且调用它们。1
2
3
4
5void run_hooks();
extern "C" void do_global_ctors()
{
run_hooks();
}1
2
3
4
5
6void run_hooks()
{
const ctor_func *list = ctors_begin;
// 逐个调用ctors段里的东西
while ((int)*++list != -1) (**list)();
}crtbegin.c前文说到,按规定,ld将会以如下顺序连接.o文件:
1
ld crtbegin.o 其他文件 crtend.o -o test
因而,
crtbegin.c的.ctor段会被链接在第一个。其作用是标识.ctor函数指针的数量,将在链接时由ld计算并且填写。因而在这里,我们只需将其初始化为一个特殊值(-1)就行:1
2
3
4
5typedef void (*ctor_func)(void);
ctor_func ctors_begin[1] __attribute__((section(".ctors"))) = {
(ctor_func)-1
};crtend.c同样,
crtend.c的.ctor段标识着.ctor段的结束。因而我们也将其初始化为一个特殊值(-1):1
2
3
4
5
6typedef void (*ctor_func)(void);
// 转化-1为函数指针,标识结束
ctor_func crt_end[1] __attribute__((section(".ctors"))) = {
(ctor_func) - 1
};
析构
全局对象的析构同样在entry中进行:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17void mini_crt_entry(void)
{
...
ret = main(argc,argv);
exit(ret);
}
void exit(int exitCode)
{
// 执行atexit,完成所有finit钩子
mini_crt_call_exit_routine();
// 调用exit系统调用
asm( "movl %0,%%ebx \n\t"
"movl $1,%%eax \n\t"
"int $0x80 \n\t"
"hlt \n\t"::"m"(exitCode));
}具体也是以链表形式管理所有的函数指针,在
atexit中注册(加入链表),在mini_crt_call_exit_routine中真正调用,不多分析。
特辑:开发中遇到的链接小问题
已经在
LD_LIBRARY_PATH中加入某个静态库的路径,但是仍然报错error while loading shared libraries: libssl.so.1.1: cannot open shared object file: No such file or directory解决方法:执行
sudo ldconfigldconfig命令的作用就是将这些共享库的路径添加到动态链接器的缓存中,以便系统能够找到它们。具体而言,
ldconfig会检查默认的共享库路径(通常是/lib和/usr/lib),以及在/etc/ld.so.conf和/etc/ld.so.conf.d/目录中定义的其他路径。然后,它会更新动态链接器缓存,这样系统就知道在哪里查找共享库。Q:也就是说ld不是像gcc找头文件,是根据-I选项规定的路径即时查找的,而是只根据缓存吗?所以尽管我们通过ld path环境变量设置了新查找路径,我们还是得手动刷新下ld缓存。
A:是的,你理解得很对。
ldconfig主要是更新系统中的共享库缓存,而不是在每次程序运行时实时查找库文件的位置。动态链接器在运行时会根据缓存中的信息找到所需的共享库,以提高性能并避免在每次程序启动时重新搜索所有库。当你通过
LD_LIBRARY_PATH环境变量设置新的查找路径时,这只是告诉动态链接器在运行时应该额外搜索这些路径。然而,为了确保系统广泛地认识这些新的路径,以及其中的共享库,你需要运行ldconfig来更新缓存。关于Windows中的动态链接库(Dynamic Link Library)和类Unix系统中的共享库(Shared Library)
起初,是这样的一段代码吸引了我的注意力:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
/**
* @brief npcp官方提供的加载npcap的dll库函数
*
* @return BOOL 是否成功
*/
BOOL LoadNpcapDlls()
{
_TCHAR npcap_dir[512];
UINT len;
len = GetSystemDirectory(npcap_dir, 480);
if (!len)
{
fprintf(stderr, "Error in GetSystemDirectory: %lx", GetLastError());
return FALSE;
}
_tcscat_s(npcap_dir, 512, _T("\\Npcap"));
if (SetDllDirectory(npcap_dir) == 0)
{
fprintf(stderr, "Error in SetDllDirectory: %lx", GetLastError());
return FALSE;
}
return TRUE;
}这是查找系统中npcap库路径,并加入到DLL查找目录的一段代码。我的问题是,明明已经在cmakelists中指明了需要链接npcap,为什么还需要在用户代码中显式链接呢?问了gpt半天,得到了一个这样仍旧存疑的答案:

